


1. Introduction
In the past decade, there has been exponential growth in the number of modeling approaches that link white matter (WM) microstructural properties and the MR signal.1 Since none of the existing models (e.g., diffusion tensor, neurite orientation dispersion and density imaging (NODDI), etc.) is a perfect representation of the underlying microstructure, choosing a model and contrast for analyses can be challenging, potentially leading to errors in biological interpretation.1,2 Multi-modal imaging, and multivariate frameworks that combine several parameters derived from different models and modalities, have been suggested as a promising avenue to harness the complementarity of different neuroimaging-derived measures.3–5
Multivariate frameworks have the potential to counteract issues arising from the physiologically unspecific nature of commonly used neuroimaging measures and to capture the complexity and heterogeneity of biological properties.3,6–9 Multiple mechanisms give rise to brain structure (e.g., myelination, cell proliferation), support neuroplastic change10,11 and behavioral performance,8,12 and are involved in neurological disorders.13 Interpreting the results of univariate statistical analyses is thus challenging within this context. In addition to capturing a more nuanced picture of the expected mechanisms, multivariate statistical frameworks can offer greater statistical power than multiple univariate analyses as they reduce the amount of multiple comparisons correction required.14–16 Lastly, and perhaps most importantly, multivariate frameworks can be leveraged to move away from group comparisons and towards individual-level analyses, an essential step on the road to precision medicine.17–19
Multivariate approaches that combine structural MRI measures have been used in a number of promising contexts. At the group level, partial least squares (PLS) analyses and their variants can be used to assess the covariance between multiple measures.20,21 Other multivariate approaches that can be used in group analyses include principal component analysis (PCA), Sparse Group Lasso, independent component analysis (ICA) and non-negative matrix factorization.20,22–26 At the individual level, inter-regional correlations of multiple measures can be used to create individual-specific network maps based on morphometric similarity that can then be linked to behavior.8 Individualized network maps provide a more comprehensive structural mapping that captures both biological complexity and individual variability because they integrate multiple MRI features.27,28 However, in this study by Seidlitz et al., (2018), the shared covariance between MRI measures was not accounted for.8 This has the potential to bias inferences made from such analyses, as there is significant covariance between many commonly used imaging parameters.4,29 Various multivariate approaches that can overcome this issue exist, including multivariate linear regression,15,30 machine-learning,7,20,22,24,31,32 and Hotelling’s T2 test.14,33 However, many of these approaches (including multivariate linear regression and machine learning) are computationally expensive and some necessitate making subjective decisions.15,34–36 The Hotelling’s T2 test, a multivariate extension of a two-sample t-test, is a simple yet powerful option for group comparisons,14,33 but provides little insight at the individual level.7
Here we propose using the Mahalanobis distance (D2)37 for analyzing multimodal MRI measures. D2 is closely related to Hotelling’s T2 but can also provide an individual-level measure of deviation relative to a reference distribution. It is defined as the multivariate distance between a point and a distribution in which covariance between features (i.e., imaging measures) is accounted for. Initially developed by P. C. Mahalanobis in 1936 to quantify racial similarities based on anthropometric measurements of skulls, D2 can be thought of as a multivariate z-score where the covariance between features is accounted for.9
The D2 approach has been used extensively in outlier detection, cluster analysis, and classification applications.38–40 D2 has also been used in neuroimaging, mainly in the study of neurological disorders, to detect lesions,35,41 or to evaluate the degree of abnormality in the brains of patients relative to controls,6,9,16,42 but also to study healthy WM development.43 Despite promising implementations and its high versatility, D2 has not yet been widely adopted. To facilitate its use, we present here an open-source python-based tool for computing D2 relative to a reference group or within a single individual: the MultiVariate Comparison (MVComp) toolbox. We provide a step-by-step guide to computing D2 using the MVComp tool (https://github.com/neuralabc/mvcomp) for two distinctive scenarios: a) comparisons between a subject and a reference group, and b) within-subject comparisons between voxels (Section 2). Lastly, the results of these example cases are presented (Section 3) and the general approach is discussed (Section 4).44
2. Methods
2.1. General framework
Since D2 can be defined relative to virtually any reference of matching features, MVComp has been designed to support a wide range of applications. The first step is to define the set of multivariate data that will serve as the reference for computing D2. This choice depends on the hypothesis of interest, which will determine the Level of Analysis (Fig. 1). D2 can be computed between different brain regions within an individual (with the individual’s data also serving as the reference) or between an individual and a group, in spatially correspondent regions. In each case, multiple different Resolutions of analysis are possible, including voxel-wise and region of interest- (ROI) based comparisons.

Lastly, the choice of which dimensions to combine, either MRI-derived measures or brain regions (e.g., WM tracts), depends on what we want to capture. Combining brain regions within a multivariate measure allows to capture the degree of deviation from a reference even in the presence of high spatial heterogeneity,9,16 while combining features is useful in the presence of mechanistic heterogeneity (i.e., several concomitant underlying biological mechanisms) and when preserving regional specificity is desirable.35,41,42 Both brain regions and MRI measures can be combined, as has been done by Dean and colleagues (2017).6 See Fig. 1 for a comprehensive view of the possible combinations of levels of analysis, resolutions and with different dimensions combined.
To illustrate the flexibility of the D2 approach, we present 4 examples:
2.1.1. Comparisons between an individual and a group (reference)
Example 1: Computing a voxel-wise D2 map for each individual
Data: Diffusion MRI (dMRI) data in several subjects
Level of Analysis: Between an individual and a group (Fig. 1 right panel)
Feature Resolution: Voxel-wise D2 (in all WM voxels) (Fig. 1b)
Dimensions combined: dMRI-derived maps (Fig. 1i)
In this example the reference would be defined as the voxel-wise group average for each dMRI-derived measure 1, 2, n, where n is the number of measures) and D2 is computed by comparing the feature values in each voxel of an individual to the corresponding voxel in the reference (see Fig. 2a-c). The resulting D2 maps can then be entered into second-level analyses to, for example, identify brain-behavior associations. If two groups are being analyzed (e.g., patients vs controls), the control group could be used as the reference and D2 values computed between each patient and the reference would represent voxel-wise multivariate distance from controls.
Example 2 : Computing a single D2 score per individual
Data: dMRI data in several subjects
Level of Analysis: Between an individual and a group (Fig. 1 right panel)
Feature Resolution: Subject D2 (Fig. 1d)
Dimensions combined: WM tracts (spatial dimensions) (Fig. 1ii)
A single MRI measure can also be used and combined across multiple ROIs (e.g., mean FA in pre-defined WM tracts). The reference is defined as the group mean of each tract 1, 2, n, where n is the number of tracts) and a single D2 value is computed for each individual. In this case, D2 represents a measure of how different an individual’s WM microstructure is relative to a reference, across multiple tracts. This workflow can also be used if the user wishes to combine both brain regions and MRI measures. The reference is then defined as the group mean of each MRI measure for each tract 11, 12, 1n, i1, i2, in, where n is the number of MRI measures, i is the number of tracts and the length of the vector is n x i). Again, a single D2 score is obtained for each subject. These applications are not demonstrated in the present article but have been shown by others9,16 and can be implemented using MVComp.

To ensure that each subject’s data will not bias their D2 values in single sample designs (i.e., where the entire sample is used as a reference) and to allow the evaluation of controls in two-sample designs, a leave-one-subject-out approach is also possible. In this way, the subject under evaluation is excluded from the group mean (reference) and covariance matrix prior to calculating D2.
2.1.2. Comparisons within an individual
Example 3: Computing D2 between lesion voxels and normal appearing WM (NAWM)
Data: dMRI data in one subject
Level of Analysis: Within an individual (Fig. 1 left panel)
Feature Resolution: Voxel-wise (in lesion voxels) (Fig. 1b)
Feature Dimensions: dMRI-derived maps (Fig. 1i)
Here, the level of analysis is within-subject, the dimensions combined are multiple dMRI-derived measures in each voxel, and the reference is the average of all voxels within a region of interest (ROI) for each dMRI measure. To investigate the distance between WM lesions and NAWM, the reference would be defined as the average of all NAWM voxels 1, 2, n, where n is the number of measures) and D2 would be computed for each voxel classified as a lesion. Alternatively, the resolution could be ROI-wise if the user deems a single D2 value per lesion sufficient. This within-subject approach can also be used as a measure of similarity by computing D2 between all WM voxels and a reference ROI in a specific tract (e.g., voxels in the cortico-spinal tract, as in Fig. 2d). Voxels within the same WM tract as the reference ROI are likely to have lower D2 values (indicating higher similarity) than voxels in other tracts or in areas of crossing fibers (Fig. 2e).
Example 4: Computing D2 between each voxel and all other voxels in a mask
Data: dMRI data in one subject
Level of Analysis: Within an individual (Fig. 1 left panel)
Feature Resolution: Voxel-voxel D2 matrix (Fig. 1a)
Feature Dimensions: dMRI-derived maps (Fig. 1i)
D2 can be calculated between every pair of voxels (voxel x − voxel y) within a mask of analysis to compute a voxel-voxel D2 matrix (see Fig. 1a). In this case, the reference for computing the covariance matrix would be the data in all voxels contained in the mask.
See Supplementary material for a summary of the workflow for the 4 examples.
2.2. Data preparation
In all cases, data for all subjects should be preprocessed and all MRI measures of interest computed and transformed to bring them into the same voxel space. If instead of voxel-wise comparisons the user is interested in performing ROI-based comparisons, summary measures should be calculated for each region of interest (e.g., mean FA in each WM tract of interest) for each subject. Masks should also be generated to restrict analyses to chosen regions (e.g., WM) and these should also be transformed into the same space. Masks can be binary or thresholded at a later step within MVComp.
2.3. Computing the reference mean and covariance matrix
In the case of analyses between subject(s) and a reference (Fig. 1 right panel), the reference mean and covariance matrix are derived either from multiple features (Fig. 1i) or multiple ROIs (Fig. 1ii) in another group (e.g., control group). The comparison can also be between each individual and the mean of all other individuals if only a single group is available. In the case of analyses within an individual (Fig. 1 left panel), multiple features can be compared between voxels (e.g., Fig. 1 a-b) or between ROIs (e.g., Fig. 1c).
2.3.1. Comparisons between an individual and a group (reference)
Combining MRI measures
For this application, the group average of each measure must be computed from the reference group (mvcomp.compute_average can be used to perform this task). The mvcomp.feature_list function can then be used to create a list of feature names and a list of the full paths of the average maps that were created with the compute_average function. The feature_gen function extracts the feature matrix from a set of input images. Run on the reference group mean images with a provided mask, it returns the feature matrix (m_f_mat of shape n voxels in the mask x n features), a mask vector (mat_mask of shape n voxels) and a nibabel object of the mask (mask_img). The mask array contains zeros at voxels where values are nan or inf for at least one of the reference average maps in addition to the voxels below the threshold set for the mask. The norm_covar_inv function is then used to compute the covariance matrix (s) and its pseudoinverse (pinv_s) from the reference feature and mask matrices (m_f_mat and mat_mask). The correlation_fig function can be used to generate a correlation matrix from the covariance matrix (s), which is informative to verify if expected relationships between features are present.
A leave-one-out approach (where the individual to be compared to the reference is left out of the average) is preferred in cases where the individual subject is also a member of the reference group. This functionality is directly available in the model comparison function (model_comp). If the leave-one-out approach is used, it is not necessary to compute the group average nor to use the feature_gen and norm_covar_inv functions since the average and covariance matrix will be computed within the model_comp function from a group that excludes the subject for which D2 is being computed.
Combining spatial dimensions
The reference mean values (e.g., reference group mean FA in each WM tract) and covariance matrix are computed within the spatial_mvcomp function described in detail below. See9,16 for example applications of this implementation.
2.3.2. Comparisons within an individual
Voxel-wise D2 resolution
In the case of comparisons within a single subject, one of the possible applications is to compute D2 between specific ROIs. If the reference ROI is a set of NAWM voxels, the covariance matrix will be computed based on all voxels within that ROI in that subject. The path of the images (i.e., one image per measure) can be provided to the feature_gen function, along with the ROI mask, to create the reference feature matrix (m_f_mat) and mask vector (mat_mask). The norm_covar_inv function is then used to compute the covariance matrix (s) and its pseudoinverse (pinv_s) from the feature and mask matrices. The correlation_fig function can again be used to visualize relationships between measures.
Voxel-voxel matrix D2 resolution
For this approach, the covariance matrix is computed from a feature matrix that includes all voxels in the mask of analysis. For instance, if we are interested in computing D2 between each voxel and all other voxels in the whole WM, the covariance matrix is based on all WM voxels. Therefore, the matrix provided to the norm_covar_inv function will be of shape n voxels in the mask x n features.
2.4. Computing D2
Once the mean of the reference and the covariance matrix have been computed and the data for comparisons has been prepared, the D2 computation can be performed. Depending on the resolution of D2, this computation may be repeated several times (i.e., between every pair of voxels or once for each voxel or each ROI; Fig. 1a-c), or it may only be done once if the user is interested in obtaining a single individualized score of deviation from a group (Fig. 1d). The MVComp tool contains functions to easily compute D2 for each of these applications, according to this equation:
D2=(x−m)TC−1(x−m),
where is the vector of data for one observation (e.g., one subject), is the vector of averages of all observations for each independent variable (e.g., MRI measures), and is the inverse of the covariance matrix.
2.4.1. Comparisons between an individual and a group (reference)
Combining MRI measures
The model_comp function allows the calculation of voxel-wise D2 between each subject contained in the provided subject_ids list and the reference (group average) (Fig. 1 right panel; b). The user should specify the directories and suffix of the subjects’ features and of the reference images (feature_in_dir, model_dir, suffix_name_comp and suffix_name_model), the mask of analysis (mask_f) and a threshold if the mask is not binary (mask_threshold). If subjects or features are to be excluded at this point, they can be specified with the exclude_subject_ids and the feat_sub options, respectively. If the user wishes to use the leave-one-out approach, the exclude_comp_from_mean_cov option should be set to True. If this option is set to True, the mean (reference) and pinv_s are computed for each subject comparison, excluding the subject being compared before computing its D2. Therefore, it is not necessary to specify the directory of the reference (model_dir) in this application. The model_comp function yields a matrix containing the D2 data of all subjects (of size number of voxels x number of subjects). To obtain a D2 map (in nifti format) for each subject, the dist_plot function can then be used. The function also outputs a mean D2 map of all subjects and a histogram of all D2 values.
Combining spatial dimensions
The spatial_mvcomp function is used to compute a D2 score between each subject and the reference computed from all subjects (Fig. 1ii). A matrix containing the data (e.g., mean FA in each WM tract) of all subjects (n subjects x n tracts) should be provided to the function. The spatial_mvcomp function returns a vector with a single D2 value per subject, reflecting the subject’s individualized score of deviation from the group. As in model_comp, setting the exclude_comp_from_mean_cov to True leaves out the current subject when computing the mean and covariance.
2.4.2. Comparisons within an individual
Voxel-wise D2 resolution
The mah_dist_mat_2_roi function is used to compute voxel-wise D2 between all voxels within a mask and a specific ROI (Fig. 1 left panel; b). Here, in addition to the feature matrix containing the data for the voxels to be evaluated (n voxels in the mask x n features), the user will need to provide a vector of data for the reference ROI (i.e., mean across voxels in the ROI for each measure) and the inverse of the covariance matrix (pinv_s) calculated previously.
Voxel-voxel matrix D2 resolution
The voxel2voxel_dist function is used to compute D2 between each voxel and all other voxels in a mask (Fig. 1 left panel; a). This yields a symmetric 2-D matrix of size n voxels x n voxels containing D2 values between each pair of voxels.
2.5. Statistical analysis
Once D2 values are computed, second-level statistical analyses can be used to assess group differences and longitudinal trajectories, to explore relationships between D2 and behavior. Machine learning techniques can also be used to reduce dimensionality and produce network maps based on (dis)similarity.
2.5.1. Comparisons between an individual and a group (reference)
For group comparisons, a two-samples t-test can be performed on D2 values (e.g., D2 values in patients vs D2 in controls), which would be equivalent to performing a Hotelling’s T2 test on raw measures (i.e., without computing D2). Alternatively, a statistical method such as the Bhattacharyya coefficient can be used to estimate the degree of overlap between the distribution of each group, where less overlap indicates a higher probability that the groups differ, as in.6 However, such group analyses are likely to average out interindividual variability and may be problematic when heterogeneity is high.7 Wilk’s criterion is another approach that can be used to define abnormality based on a calculated critical value that accounts for normative sample size, number of features, and multiple comparisons.35,42,45
2.5.2. Comparisons within an individual
In within-subject analyses, clustering approaches can be applied to the voxel-voxel D2 matrix to partition brain voxels into networks or other parcellations.
Changes in D2, either from the group or subject-level, can also be assessed through longitudinal analyses, to investigate WM damage progression or brain maturation for instance.41,43 D2, or changes in D2, can also be related to behavioral outcomes (e.g., cognitive score, performance on a skill test, or symptom severity) in the same way one would with univariate measures of fractional anisotropy for instance.6,9,16
2.6. Determining feature importance
D2 summarizes the amount of deviation from a reference, based on several measures or brain regions, into a single score. This yields a useful metric to easily quantify abnormalities, whether due to pathology or to exceptional abilities such as musical skills. However, when summarizing several features into a single score, we lose specificity. To help address this limitation, it is possible to extract the contribution of each feature to the multivariate distances (D2) using functions of the MVComp tool to recover biological or spatial specificity.
2.6.1. Comparisons between an individual and a group (reference)
Combining MRI measures
If the user is interested in understanding the physiological mechanisms underlying microstructural deviations in a region of interest (e.g., voxels where D2 is high), the return_raw option of the model_comp function can be used. This allows the extraction of each measure’s weight in D2. If return_raw is set to True, the function returns a 3D array of size (number of voxels) x (number of measures) x (number of subjects) that contains the voxel-wise distances for each feature and each subject. A flattened mask of the region of interest (e.g., a region of high D2) can then be applied to select voxels from the 3D array. The distances can be summarized across voxels and/or subjects to obtain a % contribution to D2 for each MRI measure within that region.
Combining spatial dimensions
The return_raw option is also available in the spatial_mvcomp function. If set to True, a 2D array of size (number of subjects) x (number of tracts) containing the distances between every subject’s tract and the mean tract values is returned. These raw distances provide information regarding the contribution of each WM tract to D2, which gives insights on the localization of greatest deviation for each subject.
2.6.2. Comparisons within an individual
Voxel-wise D2 resolution
The return_raw option of the mah_dist_mat_2_roi function can be used to extract features’ contributions. In this case, the distances between features in all voxels being compared and feature values in the ROI are returned. The output will be of shape (number of voxels) x (number of measures).
2.7. Experiments
2.7.1. Data Description
We computed 10 microstructural features for 1001 subjects from the Human Connectome Project S1200 data release46 for these experiments. DWI, T1- and T2-weighted data were acquired using a custom-made Siemens Connectom Skyra 3 Tesla scanner with a 32-channel head coil. The DWI data (TE/TR=89.5/5520 ms, FOV=210×180 mm) were multi-shell with b-values of 1000, 2000 and 3000 s/mm2 and a 1.25 mm isotropic resolution, 90 uniformly distributed directions, and 6 b=0 volumes. T1-w data was acquired with a 3D-MPRAGE sequence and T2w images with a 3D T2-SPACE sequence, both with a 0.7mm isotropic resolution (T1w: 0.7 mm iso, TI/TE/TR=1000/2.14/2400 ms, FOV=224×224 mm; T2w: 0.7 mm iso, TE/TR=565/3200 ms, FOV=224×224 mm). Anatomical scans were acquired during the first session, and DWI data were acquired during the fourth session. More details on the acquisitions can be found at: https://www.humanconnectome.org/hcp-protocols-ya-3t-imaging. The imaging data of 1065 young healthy adults, those who had undergone T1w, T2w and diffusion-weighted imaging, were preprocessed. The data of 64 participants were excluded due to poor cerebellar coverage.
2.7.2. Preprocessing
Diffusion Tensor Imaging
The minimally preprocessed HCP data was used.46,47 The minimal preprocessing pipeline for DWI data includes intensity normalization of the b=0 images, eddy current and susceptibility-induced distortions correction, using DWI volumes of opposite phase-encoding directions, motion correction and gradient nonlinearity correction. DWI data were registered to native structural space (T1w image), using a rigid transform computed from the mean b=0 image, and diffusion gradient vectors (bvecs) were rotated accordingly.
Most subsequent processing steps were performed using the MRtrix3 toolbox.48 The minimally preprocessed DWI data was converted to the mif format, with the bvals and bvecs files embedded, after which a bias field correction was performed using the ANTs algorithm (N4) of the dwibiascorrect function of MRtrix3.49 The tensor was computed on the bias field-corrected DWI data (using dwi2tensor) and DTI measures were then calculated (FA, MD, AD and RD) using tensor2metric.50–52
Multi-tissue Multi-shell Constrained Spherical Deconvolution
The multi-tissue Constrained Spherical Deconvolution (CSD) was performed following the fixel-based analysis (FBA) workflow.48 The T1-w images were segmented using the 5ttgen FSL function of MRtrix3, which uses the FAST algorithm.53–57 Response functions for each tissue type were then computed from the minimally preprocessed DWI data (without bias field correction) and the five-tissue-type (5tt) image using the dwi2response function (msmt_5tt algorithm).58 The bias-uncorrected DWI data was used because bias field correction is performed at a later step in the FBA pipeline.59 The WM, GM and CSF response functions were then averaged across all participants, resulting in a single response function for each of the three tissue types. Multi-shell multi-tissue CSD was then performed based on the response functions to obtain an estimation of orientation distribution functions (ODFs) for each tissue type.58 This step is performed using the dwi2fod msmt_csd function of MRtrix3 within a brain mask (i.e., nodif_brain_mask.nii.gz). Bias field correction and global intensity normalization, which normalizes signal amplitudes to make subjects comparable, were then performed on the ODFs, using the mtnormalise function in MRtrix3.60,61
Registration
In order to optimize the alignment of WM as well as gray matter, multi-contrast registration was performed. Population templates were generated from the WM, GM and CSF FODs and the “nodif” brain masks of a subset of 200 participants using the population_template function of MRtrix3 (with regularization parameters: nl_update_smooth= 1.0 and nl_disp_smooth= 0.75), resulting in a group template for each of the three tissue types.48
Subject-to-template warps were computed using mrregister in MRtrix3 with the same regularization parameters and warps were then applied to the brain masks, WM FODs, DTI metrics (i.e., FA, MD, AD and RD), T1w, and T2w images using mrtransform.62 T1w and T2w images were kept in native resolution (0.7mm) and the ratio of T1w/T2w was calculated to produce a myelin map.63 WM FODs were transformed but not reoriented at this step, which aligns the voxels of the images but not the fixels (“fibre bundle elements”). A template mask was computed as the intersection of all warped brain masks (mrmath min function). This template mask includes only the voxels that contain data in all subjects. The WM volumes of the five-tissue-type (5tt) 4-D images were also warped to the group template space since these are then used to generate a WM mask for analyses.
Computing fixel measures
The WM FOD template was segmented to generate a fixel mask using the fod2fixel function.64,65 This mask determines the fiber bundle elements (i.e., fixels), within each voxel of the template mask, that will be considered for subsequent analyses. Fixel segmentation was then performed from the WM FODs of each subject using the fod2fixel function, which also yields the apparent fibre density (FD) metric. The fixelreorient and fixelcorrespondence functions were then used to ensure subjects’ fixels map onto the fixel mask.48
The fibre bundle cross-section (FC) metric was then computed from the warps generated during registration (using the warp2metric function) as FC is a measure of how much a fiber bundle has to be expanded/contracted for it to fit the fiber bundles of the fixel template. Lastly, a combined metric, fibre density and cross-section (FDC), representing a fibre bundle’s total capacity to carry information, was computed as the product of FD and FC.
Transforming fixel measures into voxel space
In order to integrate all measures into the same multi-modal model, fixel metric maps were transformed into voxel-wise maps. As a voxel aggregate of fiber density, we chose to use the l=0 term of the WM FOD spherical harmonic expansion (i.e., 1st volume of the WM FOD, which is equal to the sum of FOD lobe integrals) to obtain a measure of the total fibre density (FDtotal) per voxel. This was shown to result in more reproducible estimates than when deriving this measure from fiber specific FD (i.e., by summing the FD fixel metric).66 The FOD l=0 term was scaled by the spherical harmonic basis factor (by multiplying the intensity value at each voxel by the square root of 4π).
For the fiber cross-section voxel aggregate measure, we opted for computing the mean of FC, weighed by FD (using the mean option of the fixel2voxel function). We thus obtained the typical expansion/contraction necessary to align fiber bundles in a voxel to the fixels in the template.
Lastly, the voxel-wise sum of FDC, reflecting the total information-carrying capacity at each voxel, was computed using the fixel2voxel sum option.
NODDI measures
Bias field corrected DWI data was fitted to the neurite orientation dispersion and density imaging (NODDI) model using the python implementation of Accelerated Microstructure Imaging via Convex Optimization (AMICO).67,68 First, small variations in b values were removed by assigning the closest target bval (0, 1000, 2000 or 3000) to each value of the bvals file. This is to prevent the fitting algorithm from interpreting every slightly different bval as a different diffusion shell. A diffusion gradient scheme file is then created from the bvecs, and the new bvals file. The response functions are computed for all compartments and fitting is then performed on the unbiased DWI volumes, within the non-diffusion weighted brain mask (nodif_brain_mask.nii.gz). The resulting parameters obtained are: the intracellular volume fraction (ICVF, also referred to as neurite density), the isotropic volume fraction (ISOVF), and the orientation dispersion index (OD). In this study, we will use ICVF and OD.
Generating masks for analyses
The maps of each of the 10 measures of interest (FA, AD, RD, MD, T1w/T2w, FDtotal, FCmean, FDCsum, ICVF and OD) were then averaged across all subjects. These average maps served as the reference. A WM mask was created by computing the group average of the corresponding volume of the T1 5tt image (volume 2). A threshold of 0.99 was applied within the MVComp toolbox’s functions.
2.7.3. Experiment 1: Comparisons between an individual and a group (reference)
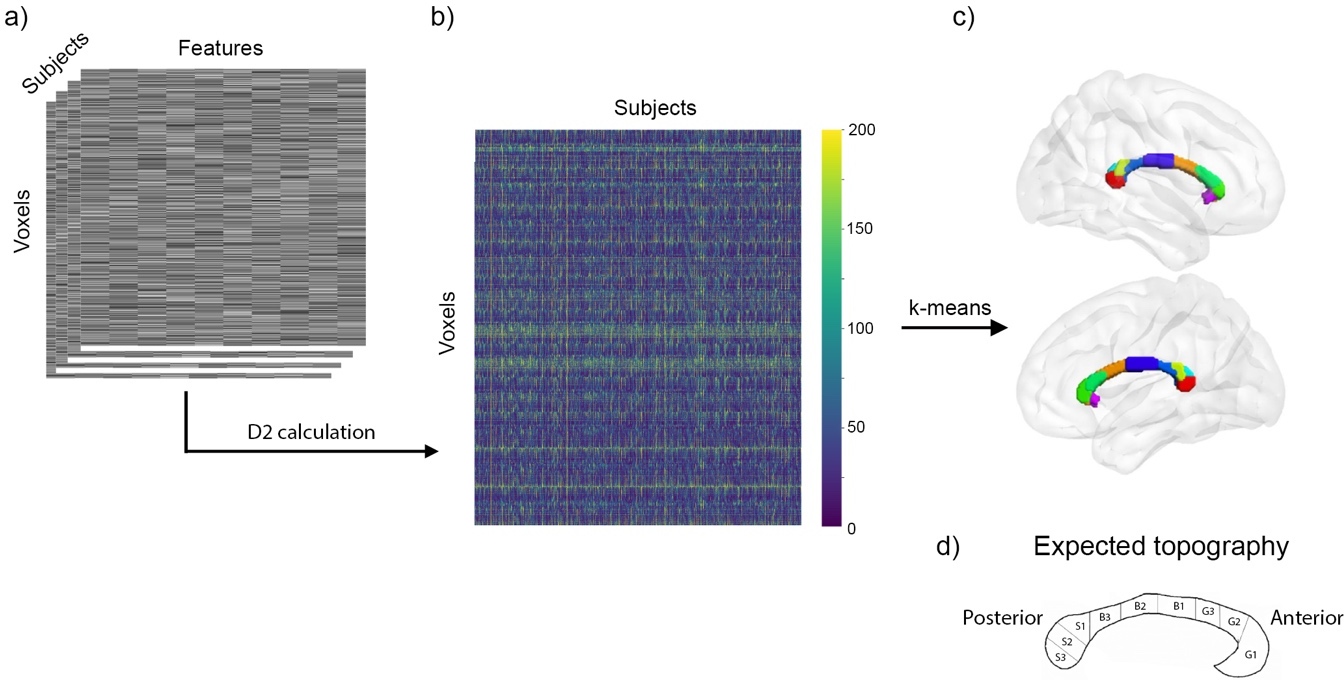
Here, we present an example case of using D2 in a large sample from the HCP dataset to quantify voxel-wise microstructural differences in WM according to several dMRI measures. Since the dataset used in this study contains the data of healthy young adults, a relatively homogeneous population, the entire sample was set as the reference and the leave-one-out approach was used to exclude the subject under evaluation. The analysis was restricted to the corpus callosum (CC). Voxel-wise D2 from 10 microstructural features was computed in the CC for each subject, yielding a D2 matrix of 1001 subjects X 2845 voxels. The D2 values represent voxel-wise microstructural differences in an individual’s CC relative to the group average, while accounting for the covariance between features. Large D2 scores in a voxel indicate greater deviation from the group average, whereas scores closer to 0 indicate lower distance (i.e., more typical microstructure).
Past literature on CC neuroanatomy shows several segments that are distributed along the anterior to posterior axis, where each segment is defined by common microstructural properties and/or connectivity profiles.69–71 We therefore hypothesized that these segments could be extracted via clustering, an unsupervised machine learning technique, of D2 values in the CC. We performed k-means clustering on the D2 matrix, setting the number of clusters to 9 based on literature on CC topography.69–71 Prior to clustering, we applied z-score and power transformation on the D2 matrix to achieve gaussian distributions of the standardized scores. Due to the large number of datapoints and potential effects of partial voluming, we observed several outliers in D2 maps of several subjects. We therefore excluded participants with at least 50 voxels that were deemed as outliers (i.e. exceeded a threshold of 5 standard deviations from the voxel mean D2). This yielded a final sample of 723 participants. Final visualization was done using BrainNet Viewer (http://www.nitrc.org/projects/bnv/).
2.7.4. Experiment 2: Comparisons within an individual
The within-subject approach allows the computation of voxel-voxel D2 in a single individual from multiple microstructural features. Here, D2 was calculated between each voxel and every other voxel in a subject’s CC, while accounting for the covariance between the 10 microstructural features. All voxels within the CC of that subject were used to compute the covariance matrix and this same covariance matrix was used in the D2 calculation of every voxel. The resulting D2 matrix is a 2845 voxel X 2845 voxel dense matrix representing the distance between each voxel and every other voxel in the CC (Fig. 4a-b). We standardized the matrix to z-scores and applied Principal component analysis (PCA) to reduce the matrix dimensionality (Fig. 4c). Of note, eigendecomposition on the D2 matrix would be a valid alternative approach to reduce matrix dimensionality. In fact, because data was centered prior to applying PCA, the first eigenvector should be equivalent to the first principal component from PCA. We then extracted the contributions of each metric to D2 within the voxels with the largest and the lowest scores on the first principal component (Fig. 4d-f).
3. Results
3.1. Experiment 1: Comparisons between an individual and a group (reference)
For this experiment, D2 was computed voxel-wise in the CC between each subject and a reference consisting in all other subjects (Fig. 3a-b). K-means clustering was applied to the D2 matrix of size (subjects) X (voxels). We observed that the 9 clusters were distributed along the anterior-posterior axis, in accordance with past evidence on CC microstructure and connectivity.69–71 Fig. 3c shows the clusters identified via k-means and Fig. 3d shows the topography expected according to literature. The genu of the CC was clustered into 3 segments, while the midbody displays 2 segments. The splenium was divided into 4 segments (with one segment positioned on the isthmus). Segmentations from individual MRI measures are also presented in Supplementary material.

3.2. Experiment 2: Comparisons within an individual
For the within-subject experiment, D2 was computed between all voxel pairs in the CC of a single individual, yielding a voxel X voxel D2 matrix (Fig. 4a-b). PCA was applied to the D2 matrix. Fig. 4c shows the first 10 principal components (PCs). We then extracted the contributions (i.e., loadings) of each metric to D2 within the voxels with the largest and the lowest scores on the first principal component. The first PC explained 95% of the variance in the voxel X voxel dense D2 matrix. The highest and the lowest PC1 scores were in the genu and in the midbody of the CC, respectively (Fig. 4d). In the voxel with the largest value on PC1, the fibre density and cross-section metric (sumFDC) contributed most to D2, while mean diffusivity (MD) contributed the least (Fig. 4f). On the other hand, in the voxel with the lowest score on PC1, all microstructural features had nearly equal contributions to D2, indicating minimal variability in this voxel (Fig. 4e).

4. Discussion
In the present study, we introduced the MVComp tool,44 a set of python-based functions that can be used to compute the Mahalanobis distance (D2) for a wide range of neuroimaging applications. At the group-level, MVComp allows the calculation of a score that quantifies how different the brain structure of an individual is from a reference group. The MVComp tool provides a versatile framework that can be used to answer various research questions, from quantifying the degree of abnormality relative to a control group in individuals with a pathology, to exploring interindividual variability in healthy cohorts. At the subject level, D2 can be used to assess differences between regions of interest or to compute a measure of similarity that can then be used for subsequent analyses (e.g., graph theory/network analyses). Lastly, D2 can combine multiple MRI measures in the same spatial locations, or it can combine a single metric across several brain regions.
Our approach allows the integration of several variables while accounting for the relationships between these variables. Several biological properties influence the same neuroimaging metric and multiple neuroimaging measures indirectly reflect a similar underlying physiological property. This overlap means that accounting for covariance between measures is essential. It also means that using a single neuroimaging measure, or measures stemming from a single model, offers limited potential for interpretation and is biased by the set of assumptions of the chosen model (e.g., some models assume fixed compartment diffusivities while others attempt to estimate them).1 Similarly, integrating the assessment of multiple brain regions may map better onto behavior (e.g., cognition or disease severity) than assessing each region separately. Here, again the relationships between variables should be accounted for as observations are not completely independent from each other (i.e., in the same individual, there is likely a great amount of covariance between FA in different voxels or in different WM tracts). While some multivariate frameworks have been implemented in the neuroimaging field, several of them are either applicable at the group level or at the subject level,8,18,33,72 and do not extend from one level to another. Frameworks using PCA can be implemented at both levels of analysis and recent studies have used PCA to combine dMRI measures, forming a reduced set of biologically interpretable variables.7,26 While this method is interesting as it allows for dimensionality reduction and visualization of patterns between variables, it differs from D2 in several aspects. For instance, in PCA, the component loadings are usually calculated once on the whole sample and yield a set of new variables that will then be used for all subjects and in all brain regions. On the other hand, the features’ loadings in D2 can be different for each subject and at each voxel. In this sense, D2 would provide a more individualized measure of deviation or dissimilarity relative to a reference, whereas PCA can be seen more as a dimensionality reduction method. Another advantage of the D2 framework is that it is highly versatile and relatively simple to implement. Moreover, the open-source MVComp toolbox we propose makes its implementation accessible for flexibly assessing a wide variety of research questions (see Fig. 1).
One of the novelties of this work is that it provides the option to extract the contributions of all features within the D2 measure, similar to extracting loadings in PCA.26 This addresses one of the main limitations of some multivariate frameworks, allowing researchers to develop more mechanistic interpretations. In previous work using the D2 approach, the loadings (or weights) of the elements combined in the multivariate measure (i.e., either WM tracts or MRI measures) were not extracted, which has been a significant limitation.6 Characterizing the extent by which each feature contributes to D2 can provide important insights into the physiological underpinnings of the differences observed and/or their localization. To our knowledge, MVComp is the only available toolbox for computing D2 on imaging data. In this paper, we detailed the usage of MVComp through 4 example cases (see Supplementary material) covering a wide range of applications and presented the results of 2 experiments.
4.1. D2 reflects the underlying microstructure of WM
To provide specific examples of how MVComp can be used, the D2 framework was applied to the assessment of WM microstructure. We found the approach to be particularly suitable for the study of WM because of the number of modeling methods available for dMRI data. However, it is important to note that other types of tissues and imaging techniques can also be used within the MVComp framework. By applying K-Means clustering to D2 in the corpus callosum, we observed a clear segmentation along the anterior-posterior axis (Fig. 3), consistent with known topography from ex-vivo anatomical studies and tractography-based connectivity.69–71 This high correspondence between clustered D2 and previously described CC topography suggests that the microstructural score obtained by combining several WM neuroimaging measures through D2 provides a useful index of microstructure.
At the individual level, D2 can capture the amount of (dis)similarity between voxels and, through the extraction of features’ contributions (i.e., loadings), the specific microstructural properties underlying regional differences can be inferred. For example, in our within-subject experiment (Fig. 4) we found high spatial heterogeneity in the relative contributions of different features to D2. The voxel with the highest loading on the first latent component (PC1) was primarily dominated by one metric (sumFDC) while the voxel with the lowest loading was characterized by similar weightings across all features. In the voxel with the highest PC1 score, sumFDC (combined metric of fiber cross-section and density, indicative of the amount of information-carrying capacity) contributed most to D2, meaning sumFDC had higher variability across CC voxels than other measures. This is consistent with the known microstructural properties of the CC, which shows regional variations in densities of fibers of different sizes along the CC.69,71 Further, given that the CC is composed of tightly packed fiber tracts, MD would likely be very low in all those CC voxels (i.e., low variability), which would explain its low contribution. Overall, this supports the relevance of D2 in assessing variability in WM microstructure properties and showcases the use of the features contribution option (i.e., return_raw) included in MVComp.
4.2. D2 in the study of pathologies
Given the complexity of underlying pathological changes in various brain conditions, multiparametric approaches are a promising avenue to capture the combination of multiple changes in brain properties.6,7,9,13,16,42 For instance, D2 incorporating fractional anisotropy (FA) in multiple WM tracts in epileptic patients was found to show stronger associations with epilepsy duration than any univariate measure (e.g., mean FA in a single WM tract).16 Another study reported better performance using D2 encompassing FA in several WM tracts, vs using FA in a single tract, in discriminating between controls and individuals with TBI.9 The multivariate D2 measure allowed for the discrimination of even mild TBI cases from controls and correlated significantly with cognitive scores. Similarly, using D2 combining both spatial (i.e., WM regions) and feature (i.e., different DTI measures) dimensions led to improved detection between autistic and typically developing individuals compared to univariate approaches or to D2 computed by combining brain regions only.6 Associations between D2 and autism symptom severity were also reported in this study, providing additional evidence that D2 can serve as a behaviorally relevant measure of WM abnormality.
Other interesting implementations have used D2 to detect and characterize lesions. Gyebnár et al. (2019) combined DTI eigenvalues into a voxel-wise D2 measure between epilepsy patients and controls to detect cortical malformations in patients.35 Voxels were identified as belonging to a lesion if their D2 value exceeded a critical value calculated using Wilks’ criterion,45 a criterion used for multivariate statistical outlier detection. In another implementation, D2 was employed to characterize the heterogeneity within WM lesions by computing the multivariate distance (combining T1-w, T2-w and PD-w signal intensities) between voxels in WM hyperintensities and those in normal appearing WM (NAWM).41 D2 in WM hyperintensities progressed at a quicker rate in individuals who converted from mild cognitive impairment to Alzheimer’s disease (AD) compared to those who did not convert. Interestingly, the rate of change of WM hyperintensities volume (i.e., lesion load), a metric more commonly used,73,74 did not differentiate converters from non-converters cross-sectionally and longitudinally, suggesting that a characterization of WM lesion heterogeneity through a multivariate framework was more informative than the volume of WM lesions.41
4.3. Limitations
There are some limitations of D2 computation as presented in MVComp. First, D2 itself is a squared measure, thus the directionality of the difference is non-specific. As it is currently implemented, it is not possible to determine whether a given subject’s features are higher or lower than the average, although this information can be easily extracted by comparing the subject’s voxel values or ROI means to the mean of the group average on a per-metric basis. Future studies could potentially address this limitation indirectly by integrating with studies that model ground-truth biophysical properties to better interpret differences and/or splitting groups based on expected direction of change. Then, the directions of deviations from the average could be hypothesized a priori.
D2 is a sensitive multivariate distance measure that has since found applications in various fields, such as classification, cluster analysis, and outlier detection. Our implementation makes use of the sensitivity of D2 to detect multivariate deviations in WM microstructure. This high sensitivity also means the method can be affected by registration inaccuracies and partial voluming (PV). Therefore, special attention must be paid to ensure optimal alignment across subjects and modalities (e.g., using directional information from dMRI to align WM tracts). Strict tissue type masking (e.g., using a high threshold on probabilistic segmentation images) can also be used to limit the amount of PV. However, this may result in a large number of excluded voxels, especially for low resolution images. Alternatively, the PV effect can be quantified and accounted for.35,75 The latter option would be preferable if the D2 framework was used to detect tumors and estimate their volume, for instance.
Another limitation of D2 as presented in MVComp is that its use is restricted to continuous variables. However, more recent formulations of D2 allow for nominal and ordinal variables to be incorporated in the model, in addition to continuous variables.76,77 Future developments of MVComp could thus allow generalization of D2 to include mixed data types (e.g. WM, sex, or other grouping variable).
5. Conclusion
We introduce a new open-source tool for the computation of the Mahalanobis distance (D2), the MVComp (MultiVariate Comparisons) toolbox.44 D2 is a multivariate distance measure relative to a reference that inherently accounts for covariance between features. MVComp can be used in a wide range of neuroimaging implementations, at both the group and subject levels. In line with the current shift towards precision medicine, MVComp can be used to obtain personalized assessments of brain structure and function, which is essential in the study of brain conditions with high heterogeneity.
Data and Code Availability
The data is openly available from the Human Connectome Project (https://www.humanconnectome.org/study/hcp-young-adult/document/1200-subjects-data-release) and the code of the MVComp toolbox is available at https://github.com/neuralabc/mvcomp.44
Author Contributions
Stefanie A Tremblay: Writing - Original Draft, Conceptualization, Data Curation, Methodology, Software, Validation, Visualization
Zaki Alasmar: Methodology, Software, Formal analysis, Validation, Conceptualization, Data Curation, Writing - Original Draft, Visualization
Amir Pirhadi: Methodology, Software, Validation, Data Curation
Felix Carbonell: Methodology, Writing - Review & Editing
Yasser Iturria-Medina: Methodology, Writing - Review & Editing, Conceptualization, Funding acquisition
Claudine J Gauthier: Supervision, Conceptualization, Writing - Review & Editing
Christopher J Steele: Supervision, Conceptualization, Methodology, Writing - Review & Editing, Software, Funding acquisition
Funding Sources
This study was supported by the Canadian Institutes of Health Research (FRN: 175862, to Stefanie A. Tremblay), the Canadian Natural Sciences and Engineering Research Council (RGPIN-2015-04665, to Claudine J. Gauthier), the Michal and Renata Hornstein Chair in Cardiovascular Imaging (to Claudine J. Gauthier). Christopher J. Steele has received funding from the Natural Sciences and Engineering Research Council of Canada (DGECR-2020-00146), the Canada Foundation for Innovation (CFI-JELF Project number 43722) and Heart and Stroke Foundation of Canada (National New Investigator), and the Canadian Institutes of Health Research (HNC 170723). Christopher J. Steele and Yasser Iturria-Medina were also supported by the Quebec Bioimaging Network.
Data were provided by the Human Connectome Project, WU-Minn Consortium (Principal Investigators: David Van Essen and Kamil Ugurbil; 1U54MH091657) funded by the 16 NIH Institutes and Centers that support the NIH Blueprint for Neuroscience Research; and by the McDonnell Center for Systems Neuroscience at Washington University.
Declaration of Competing Interests
The authors have no competing interests to declare.