
Correlation, covariance and distance matrices are among the most commonly used data types in network neuroscience.1–4 These matrices are typically built via pairwise comparisons of functional and/or structural neuroimaging data. In these matrices, one entry stores a numerical value quantifying the similarity between two spatial locations (i.e., brain voxels, vertices, regions, channels) and the pattern of these entries reflects an estimate of brain network organization.
In network neuroscience, matrices—also called here data tables—are typically obtained from sets of variables collected on the same individuals (e.g., multiple scans or sessions, multiple imaging modalities),5–9 or from the same variables collected on different individuals (e.g., one type of imaging scan on several participants).10–13 Data tables are then compared to one another to assess temporal network structure,14–17 multi-modal network organization,4,18,19 individual differences,20–25 and group or population effects.26–30 Data tables are also contrasted with one another to investigate the statistical reliability of patterns derived from network neuroscience methods.31,32 Similarity analyses among multiple data tables thus constitute the cornerstone of network neuroscience research.
In network neuroscience, similarity analyses are most often conducted via mass univariate approaches contrasting one edge at a time, or on aggregate information within data tables (e.g., graph theory analyses33) or across (e.g., categorical groupings), or on single tables with reduced dimensions.34 While these approaches reduce the high dimensionality of network neuroscience data and simplify the analytic landscape, they may limit the statistical robustness of network neuroscience findings and obscure important properties of brain function that could be revealed from the use of multivariate methods applied to full data tables. Multivariate approaches able to align and compare relational information from full data tables across multiple observations can augment the utility, precision, and applicability of network neuroscience data and advance our understanding of brain network organization in health and disease.
Statistical methods exist—called multi-table methods35–43—explicitly designed for multivariate similarity analyses of full data tables. Their goal is to identify structured patterns within preserved high-dimensional multi-table data, and explain and visualize their statistical dependencies. Multi-table methods serve as the basis of network investigations across scientific disciplines,44 yet they are not well known in network neuroscience and therefore remain underused.
Network neuroscience presently counts a few multi-table methods, including machine learning and deep learning tools,45,46 graph neural networks,47,48 multi-layer and multiplex network approaches,18,49 similarity network fusion techniques50 and non-linear matrix decomposition algorithms.51–53 These approaches have been applied to a variety of research questions about brain network organization both in health and disease.54–61 Yet, they often yield complex results challenging to interpret, potentially because these methods rely on complex mathematical implementations62,63 and supervised analytical frameworks51 that do not allow results to be traced back to the original data. There is therefore a pressing need in network neuroscience for multi-table methods that preserve data fidelity and enhance interpretability. CovSTATIS solves this problem by analyzing intact data tables in a linear, unsupervised manner, thus allowing for the simultaneous extraction and interpretation of both individual and group-level features.
The covSTATIS method (and its variant DISTATIS) is a three-way extension of multidimensional scaling and Principal Component Analysis.64–66 The name, covSTATIS, combines “covariance” with “STATIS” (a French acronym for “structuring three-way statistical tables”). CovSTATIS takes as input symmetric, positive semi-definite matrices (i.e. symmetric matrices such as cross-product, covariance and correlation matrices, with non-negative eigenvalues) and assesses their similarity.67–69 While covSTATIS is specifically designed for correlation/covariance matrices, there exists an equivalent approach for distance matrices called DISTATIS.64 CovSTATIS and DISTATIS belong to the STATIS family of multi-table approaches.
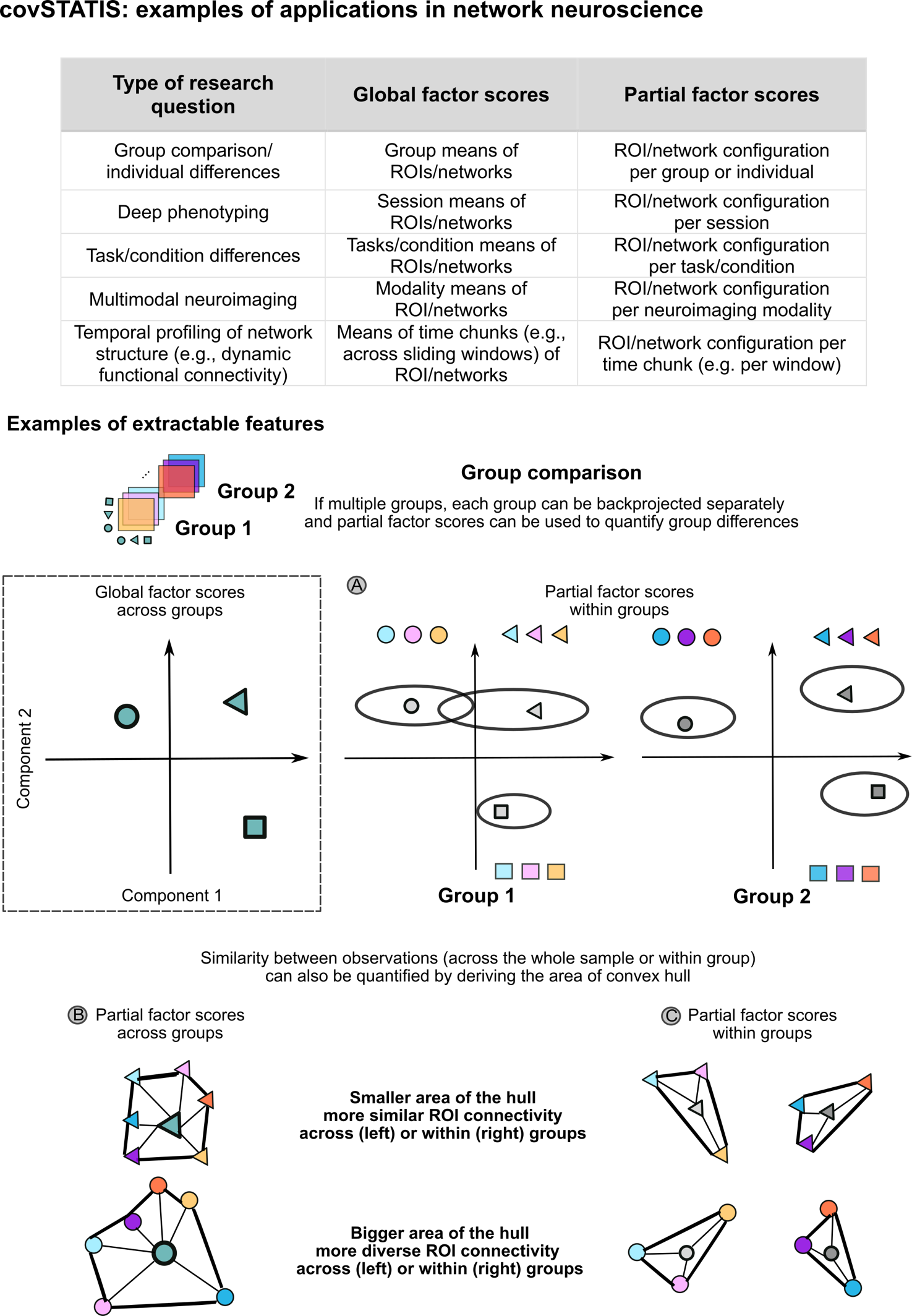
In covSTATIS, the pair-wise similarity among I correlation/covariance matrices of dimension J × J (with J being the number of variables) is quantified by the RV coefficient – a measure analogous to a squared Product-Moment correlation coefficient with values in the interval [0,1].67,70 Given I correlation/covariance matrices, the RV coefficients are stored in an I × I similarity matrix C, where the rows/columns correspond to the I data tables (Figure 1, step 1). Next, covSTATIS performs an eigenvalue decomposition (EVD) on the C matrix and takes its first eigenvector (of dimension I × 1) to derive weights for each data table. Note that because the RV is always positive all the entries for the first eigenvector of C are positive—a consequence of the Perron-Frobenius theorem. The first eigenvector maximally explains the variance in C and quantifies how similar each table is to the common pattern. Weights for each data table are derived by scaling the first eigenvector to sum to 1. Higher weights identify tables that are more similar to the common pattern, whereas lower weights identify tables less similar to the common pattern. These weights are then used to linearly combine the data tables by multiplying each table by its weight and summing across all the weighted tables. This step generates a J × J weighted group matrix—called the compromise matrix (Figure 1, step 2)—which is next decomposed by EVD. Orthogonal components are extracted from this second EVD and serve as the main output of covSTATIS (Figure 1, step 3). Components reveal the similarity between J variables with regards to the compromise—the ensemble of the similarity patterns across all I data tables. For each component, global factor scores of dimension J × L (with L being the number of components) capture the relationship between variables with respect to such compromise. For each component and each of the I correlation/covariance matrices, J × L partial factor scores can be obtained to project table-specific relationships between variables onto the same component space (Figure 1, step 4). By quantifying the deviation of each partial factor score from its corresponding global factor scores, we can assess differences between each table and the compromise.

For example, given a covSTATIS analysis of multiple functional connectivity matrices where only positive connectivity values are considered, global factor scores represent the brain regions on the component space and illustrate the associations in their connectivity profiles across the whole sample. Partial factor scores represent the brain regions of each individual’s connectivity matrix and illustrate how regions are associated with each other in relation to the group pattern. Factor scores of any two components can be used as coordinates to draw scatter plots in the component space, where the distance between two scores represents their similarity. Two global factor scores close to each other indicate high similarity in their respective connectivity patterns across the whole sample, while a partial factor score close to its corresponding global factor score represents high similarity between an individual’s regional connectivity profile and the regional profile from the whole sample. In sum, covSTATIS provides an unsupervised, linear framework to characterize the similarity among sets of correlation/covariance matrices, and it allows for a one-to-one mapping between input (i.e., whole set of tables and single tables) and output (i.e., global and partial factor scores). This approach can both identify group-level patterns as well as provide individual-specific expressions of the patterns.
CovSTATIS has both commonalities and differences compared with other dimensionality reduction methods used in neuroscience: (1) Principal Component Analysis (PCA)71,72 and Multidimensional Scaling (MDS)73—these two techniques incorporate a single data table; PCA is performed on an observation-by-variable table, and MDS on a dissimilarity matrix between observations. They rely on the same dimensionality reduction technique as covSTATIS, but covSTATIS extends MDS by analyzing multiple similarity matrices; (2) Multiple Factor Analysis (MFA)74,75 and STATIS64—these are other component-based methods that incorporate multiple data tables, and they are particularly suitable for rectangular data structures. Such data structures are less common in network neuroscience, making MFA and STATIS less desirable methods than covSTATIS. CovSTATIS combines MDS and STATIS to deal with multiple squared, symmetric, correlation/covariance matrices–the standard format of network neuroscience data; (3) Representation Similarity Analysis (RSA)76—this method computes a dissimilarity matrix, akin to the matrix of RV coefficients in covSTATIS, from a set of correlation/covariance matrices. RSA extracts components from this dissimilarity matrix to characterize differences between the correlation/covariance matrices. These components are the main output of RSA. CovSTATIS, on the other hand, derives weights from these components to compute the compromise—the linear combination of all correlation/covariance matrices—and further extracts components from it. These components are the main outputs of covSTATIS; (4) Graph Theory approaches33—while used as meaningful statistical descriptors of network neuroscience data, they operate on aggregated pairwise information (e.g., connectivity), not on full data tables; and (5) Gradient Analysis51–53—this method is the most similar to covSTATIS in terms of functionality and implementation. It offers complementary outputs to covSTATIS, ones that are however further removed from the original data. Gradient Analysis relies on non-linear dimensionality reduction methods of affinity matrices of correlation/covariance profiles. Given that Gradient Analysis does not construct a compromise-like space, each correlation/covariance matrix needs to be projected onto the affinity-derived component space to infer similarity/differences in the data. CovSTATIS, instead, obtains the component space from a direct decomposition of the compromise–a linear combination of the original correlation/covariance matrices. As such, covSTATIS provides a multivariate framework that promotes more interpretable links between the output and the original data.
There are numerous other dimensionality reduction techniques, each having its particular strengths and weaknesses. Though almost any dimensionality reduction approach can be applied to neural data, we believe that covSTATIS is particularly well suited for the specific structure and format of network neuroscience data for its flexibility to linearly handle multiple symmetric correlation/covariance tables.
Applications of covSTATIS in network neuroscience
In neuroimaging, STATIS-based methods have been applied in a limited capacity.77–83 As such, the potential of covSTATIS as a tool for network neuroscience remains largely untapped. Recent work from our group applied covSTATIS to compare spatial patterns of fMRI connectivity across task states,84 and to estimate resting-state fMRI connectivity dynamics.85 Here, we guide the reader through the former application and provide a step-by-step tutorial with data86 and code. The tutorial can be accessed here: https://giuliabaracc.github.io/covSTATIS_netneuro/pages/tutorial.html.
Briefly, in this application of covSTATIS, we used task-based fMRI functional connectivity data from a healthy adult lifespan sample of 144 individuals, to examine how fMRI-derived functional connectivity reconfigures across task conditions with different cognitive load. Note that in the original paper we had 3 different tasks,84 but here and in the tutorial, we focus on only one (i.e., n-back with 0-, 1-, 2-back conditions).
Individual-specific functional connectivity matrices were calculated for each task condition. These tables were weighted based on their respective RV similarity coefficients, and linearly combined to create the compromise matrix—the optimum weighted average of all connectivity tables across task conditions and individuals. The compromise was then submitted to an eigenvalue decomposition to assess the similarity of the connectivity patterns across task conditions and subjects. Global factor scores represented the average connectivity profile of single brain regions across task conditions and individuals, and partial factor scores represented how the regional connectivity profile for each individual and task condition mapped onto the group average. In sum, covSTATIS allowed us to estimate (1) regional differences in functional connectivity patterns across all tasks and individuals, and (2) individual differences in functional connectivity patterns across task conditions. A more detailed breakdown of all steps involved in covSTATIS can be found in our tutorial, including guidelines in the choice of covSTATIS’ parameters based on the type of input data.
Other examples of potential applications of covSTATIS include investigations of individual and group differences in spatial and/or temporal network structure in health and disease (Figure 2, bottom panel), deep phenotyping of connectivity metrics, and multimodal assessments of network measures within and across individuals (Figure 2, top panel). Another promising avenue for covSTATIS is the exploration of brain-behavior relationships within a single framework. Through covSTATIS, participants’ correlations—computed from high dimensional brain and behavioral data tables—can be integrated in a unified compromise space from which the shared variance between tables can be extracted.

Importantly, as covSTATIS only requires symmetric positive semi-definite matrices, it provides a general framework to assess shared and distinct patterns across many type of similarity matrices, beyond functional connectivity. With proper matrix preprocessing steps (e.g., taking the Laplacian of a connectivity graph), covSTATIS can analyze other network matrices, such as structural connectivity, similarly to other methods (e.g., network portrait divergence,87 netsimile,88 and others, see this paper89 for a comprehensive list).
While not exhaustive, these applications of covSTATIS highlight the versatility of the method. We hope that the network neuroscience community will benefit from covSTATIS and collectively further refine and expand the approach. Ongoing developments of covSTATIS can be found on our website: https://giuliabaracc.github.io/covSTATIS_netneuro/.
Conclusions
CovSTATIS serves as a theoretically and computationally accessible tool for similarity analyses, capable of preserving and integrating high dimensional, complex multi-table data typical of network neuroscience. Its linear, unsupervised, user-independent implementation makes covSTATIS a more interpretable and versatile tool compared to other commonly used approaches, ultimately paving the path for new discoveries in network neuroscience.
Methods
Notations
A matrix is denoted by a bold, uppercase letter (e.g., X), a vector is denoted by a bold, lowercase letter (e.g., x), and an element of a matrix is denoted by a lowercase italic letter (e.g., x). The cardinal of a set is denoted by an uppercase italic letter (e.g., I). Given I data tables, we used the subscript i to identify individual data tables (e.g., The boldface capital letter I denotes the identity matrix. The transpose of a matrix is denoted by the superscript T (e.g., XT).
The jth column of matrix X is denoted by and the value on the kth row and the jth column is denoted by For an I × J matrix, the minimum of I and J is the largest possible rank, denoted by L, of X. The trace(X) operator gives the sum of the diagonal elements of the square matrix X.
CovSTATIS
To generate the compromise space that best represents the common pattern across all data tables (e.g., correlation/covariance matrices), covSTATIS first derives weights from a pairwise similarity matrix, called the RV matrix, which quantifies the similarity between data tables via the RV coefficient. Formally, given two J × J data tables and (e.g., two connectivity matrices with J ROIs from the 2 observations i and i’, e.g., participants or tasks), the RV coefficient between these two matrices is computed as:
RV=trace(X⊤iXi′)√trace(X⊤iXi)trace(X⊤i′Xi′)=∑Jj∑Jj′xj,j′,ixj,j′,i′√(∑Jj∑Jj′x2j,j′,i)(∑Jj∑Jj′x2j,j′,i′)
Akin to a squared correlation coefficient, the RV coefficient takes values in the interval [0 1]. The RV coefficients between all matrices are then stored in an matrix, denoted by C, where the cell stores the value of the RV coefficient between and As C stores the similarity between data tables, the first component of C best represents the common pattern across tables, and the first eigenvector of C (u1) quantifies how similar each table is to this common pattern. As a result, to build the compromise space, weights for each data table are derived by u1, rescaled to sum to 1. Formally, C undergoes an eigenvalue decomposition (EVD):
C=UΩU⊤ such that U⊤U=I,
where Ω is an R × R diagonal matrix of eigenvalues of C with R denoting the rank of C, and U is a I × R matrix of eigenvectors of C. Next, the weights of (denoted by αi) are obtained as:
αi=√ui,1∑Ii=1ui,1=(ui,1(1⊤u1)−1)12,
where ui,1 is the ith value of u1, a value that corresponds to The compromise (X+) is then computed as the weighted sum of all data matrices, where
X+=I∑i=1αiXi,
and decomposed by an EVD:
X+=PΛP⊤ such that P⊤P=I,
where Λ is an L × L diagonal matrix of eigenvalues of X+ with L denoting the rank of X+, and P is a J × L matrix of eigenvectors of X+. From EVD, the global factor scores F (i.e., factor scores from the compromise) are computed as:
F=X+PΛ−12
and the partial factor scores (i.e., the factor scores derived from the projection of individual tables onto the compromise) are computed as:
Fi=XiPΛ−12.
It is worth noting that these partial factor scores have a barycentric property, that is their weighted sums equate to the global factor scores:
F=I∑iαiFi.
The optimization problem in covSTATIS
Optimization in covSTATIS is a two-part problem. The first part is akin to the optimization problem of principal component analysis, the second part is the same as the optimization problem of eigenvalue decomposition.
First part
First, weights for each data table are obtained to compute the compromise, such that the similarity between the compromise and all input matrices is maximal. Second, components are computed that best explain the compromise’s inertia (i.e., variance in more than two dimensions). Formally, the first optimization problem can be written as the following maximization problem:
argmax
and the sum of squared scalar products can be developed and simplified:
\begin{aligned} \sum_{i=1}^I\left\langle\mathbf{X}_i, \mathbf{X}_{+}\right\rangle^2 & =\sum_{i=1}^I \sum_{i^{\prime}=1}^I \alpha_i \alpha_{i^{\prime}} \sum_{i^{\prime \prime}=1}^I \operatorname{trace}\left\{\mathbf{X}_i \mathbf{X}_{i^{\prime \prime}}\right\}\\ & \quad \times \operatorname{trace}\left\{\mathbf{X}_{i^{\prime \prime}} \mathbf{X}_{i^{\prime}}\right\} \\ & =\sum_{i=1}^I \sum_{i^{\prime}=1}^I \boldsymbol{\alpha}_i \boldsymbol{\alpha}_{i^{\prime}} \sum_{i^{\prime \prime}=1}^I c_{i, i^{\prime \prime}} \times c_{i^{\prime \prime}, i^{\prime}} \\ & =\boldsymbol{\alpha}^{\top} \mathbf{C}^2 \boldsymbol{\alpha} \end{aligned} \tag{10}
Therefore, the solution of the optimization problem defined by Equation 9 is the first eigenvector of C2, which is the same as the first eigenvector of C. According to the Perron-Frobenius theorem, the elements of α will all have the same sign (chosen as positive). These elements are then scaled to sum to 1 to ensure that partial factor scores will be barycentric for their respective global factor scores (cf. Equation 8). Note that we ignored the denominator of the RV in the first line as it is a fixed scalar equal to J2 and has no effect on the maximization problem.
This optimization problem is similar to the optimization problem of Principal Component Analysis (PCA). In PCA, weights are searched for each variable to compute factor scores—which are computed as linear combinations of these variables. In covSTATIS, weights are searched for each data table to compute the compromise—the linear combination of these data tables.
Second part
The second optimization problem is equivalent to the optimization problem of an eigen-decomposition. In the eigen-decomposition, for each component, weights (i.e., loadings) of each row/column are searched to compute factor scores (F). Factor scores are linear combinations of the loadings that have the largest possible variance (as evaluated by their associated eigenvalues). This optimization problem can be written as the minimization problem of approximating the sum of squared factor scores to the compromise:
\small{\begin{array}{rll} \underset{\mathbf{F}}{\arg \min }\left\|\mathbf{X}_{+}-\mathbf{F F}^{\top}\right\|_2^2 & \text {such that} & \mathbf{F}^{\top} \mathbf{F}=\boldsymbol{\Lambda} \\ \Leftrightarrow \underset{\mathbf{P}}{\arg \min }\left\|\mathbf{X}_{+}-\mathbf{P} \boldsymbol{\Lambda} \mathbf{P}^{\top}\right\|_2^2 & \text {such that} & \mathbf{P}^{\top} \mathbf{P}=\mathbf{I} . \end{array}} \tag{11}
Here, P is the matrix of eigenvectors and Λ is the diagonal matrix of eigenvalues.
The detailed proofs and descriptions of the optimization problems of covSTATIS can be found in the Appendix of a previous publication.64
CRediT author statement
Giulia Baracchini: Conceptualization, Software, Formal Analysis, Data Curation, Writing – Original Draft, Writing – Review and Editing, Visualization. Ju-Chi Yu: Conceptualization, Software, Formal Analysis, Writing – Original Draft, Writing – Review and Editing. Jenny Rieck: Software, Formal Analysis, Data Curation, Writing – Review and Editing. Derek Beaton: Software, Writing – Review and Editing. Vincent Guillemot: Software, Writing – Review and Editing. Cheryl Grady: Resources, Writing – Review and Editing. Hervé Abdi: Software, Writing – Review and Editing. R. Nathan Spreng: Writing – Review and Editing, Supervision.
Data availability
Data used in the tutorial are available online (https://osf.io/hnj7s/) and are described in detail in our previous publication.86
Code availability
The original source code for covSTATIS can be found here: https://cran.r-project.org/web/packages/DistatisR/ and its helper file here: https://cran.r-project.org/web/packages/DistatisR/DistatisR.pdf. All code used to apply covSTATIS in network neuroscience and replicate our tutorial, along with all documentation, can be accessed here: https://giuliabaracc.github.io/covSTATIS_netneuro/pages/tutorial.html. For the tutorial, a downloadable qmd file can be accessed here: https://github.com/giuliabaracc/covSTATIS_netneuro/blob/main/pages/tutorial.qmd. The following GitHub (https://github.com/giuliabaracc/covSTATIS_netneuro/tree/main) and website (https://giuliabaracc.github.io/covSTATIS_netneuro/) links serve as centralized resources for covSTATIS’ applications in network neuroscience.
Funding Sources
This research was supported in part by grants from the Canadian Institutes of Health Research (CIHR) the Natural Sciences and Engineering Research Council of Canada (NSERC) and the National Institutes of Health (NIA R01 AG068563). G.B. and R.N.S. are supported in part by Fonds de recherche du Québec (FRQS). J.-C.Y. receives grant support from the Discovery Fund of the Centre for Addiction and Mental Health (CAMH).
Conflicts of Interest
The authors declare no competing interests.