



1. Introduction
The pursuit of causality is a central objective in scientific inquiry, typically achieved through well-designed experiments or observational studies. Causal relationships manifest when one variable exerts an influence on another.1 Experiments aim to explore the impact of explanatory variables (exposures or treatments) on the response (or outcome) variable under diverse conditions.
A causal effect denotes the influence that an explanatory variable exerts on the response variable. It signifies the alteration in the response that can be attributed to the manipulation or change in the explanatory variable while keeping all other factors constant. In statistical analysis, the causal effect is quantified as the observed change in the response corresponding to variations in the explanatory variable while keeping all other covariates in the model constant.2,3 This analytical approach enables researchers to disentangle the specific contribution of the explanatory variable to changes in the response, while controlling for potential confounding factors. Understanding causal effects is fundamental to unraveling the underlying mechanisms of diverse phenomena and interventions.
In this context, a covariate is defined as a variable accompanying the explanatory variable in a statistical model. This explicit definition ensures consistency and clarity, avoiding the varied and sometimes offhand or pejorative terminologies such as control/adjustment variables, regressors/variables of no interest, nuisance regressors/variables, and extraneous covariates. Though often termed confounds in neuroimaging, it is crucial to note that confounds carry a distinct technical meaning, which we will explore further. Neuroimaging data analysis routinely involves covariates such as task conditions, participants, groups, estimated head motion, outliers, physiological recordings, age, sex, reaction time, global signal, and gray matter volume. Common practices, like excluding data points or participants due to outliers (e.g., excessive head motion), can be conceptually understood as a form of covariate integration. Sometimes, an explanatory variable assumes dual roles, serving as both a variable of interest and a covariate for another explanatory variable.
Neuroimaging studies exhibit various levels and degrees of variability, some meticulously controlled by the researcher, such as manipulated tasks in a factorial within-individual structure. However, uncontrollable incidents, including head motion and signals unrelated to neuronal activities, also influence the data. Between-individual variations, such as demographic factors (age, race, education, socioeconomic status), behavioral traits (reaction time), and physiological characteristics (head size), further contribute to the complexity. Faced with such diversity, the essential question for researchers is, Which covariates should be included in the model to effectively address the study question at hand?
1.1. Model considerations: a motivating example
The following presents a practical example from a neuroimaging study focusing on population-level modeling with data collected from participants spanning a wide age range. Assume that T1-weighted structural fMRI images are obtained when participants lay still in the scanner with no tasks involved. The behavior measure of short-term memory (STM) serves as the response variable. Additionally, six potential covariates are considered: voxel-level gray matter density (GMD) estimated with T1-weighted images, sex, age, intracranial volume (ICV), APOE genotype, and body weight. The primary objective of the study is to assess the causal relationship between GMD and STM. This scenario prompts several critical questions we address in this paper:
-
Explanatory variable versus response variable. While it is biologically plausible to consider GMD as an explanatory variable and STM as the response variable, conventional neuroimaging tools often assume a response variable at the spatial-unit (e.g., voxel) level, with covariates that remain constant across spatial units. Is it justifiable, for the sake of tool convenience, to designate GMD as the response variable and STM as the explanatory variable?
-
Covariates. When assessing the association between GMD and STM, should all other five covariates be included in the model? Indiscriminately incorporating all available variables can lead to misleading inferences. How does one determine which covariates should or should not be incorporated? Can the importance of a covariate or model comparisons using step-up/down procedures guide its inclusion?
-
Result interpretability/reporting. Typically, a single model (e.g., GLM) is used for a given dataset, producing an array of parameter estimates for all relevant covariates. However, is it appropriate to present all these estimates (e.g., sex differences in STM and the relationship between age and STM)?
-
Experimental design. In hindsight, could the experiment have been designed more efficiently? Which variables could have been omitted to prevent unnecessary data collection effort and resource wastage? Alternatively, what other variables might have been included to enhance effect estimation?
This example is to some extent an observational study. In biology and neuroscience, it is widely accepted that brain structure determines its function and behavior, as encapsulated by the phrase “structure determines function”.4 Therefore, it is logical to explore the causal relationship between gray matter density (GMD) and short-term memory (STM). However, GMD, estimated solely from structural data, lacks the manipulability of variables in randomized controlled experiments. This raises questions about the feasibility of estimating the GMD-STM causal relationship based on observational data.
1.2. Covariate selection in models
Covariate selection is an essential process in statistical modeling, yet it is frequently underappreciated and prone to improper guidelines. For example, head size or brain volume is frequently used as a covariate. The question arises: is the adoption of such a quantity justified? In fact, the consideration of covariates often receives insufficient attention, with their impact sometimes regarded as a mere conventional practice or perhaps simply that “more is always better.” For instance, a survey on structural MRI analysis revealed a wide range in the number of covariates, varying from 0 to 14, with 37 unique ones employed across 68 models,5 and the reasoning behind collection and inclusion was seldom provided. This issue becomes particularly pronounced when a multitude of covariates, including demographic information, are readily available from large consortium datasets (e.g., ABCD, UK Biobank). This abundance can lead to the daunting choice among hundreds or thousands of covariates,6–9 and readers should understand the potential consequences of such extreme cases.
The following are some common reasons that covariates are often included:
-
Availability. A measure was acquired, and it might be related to the effects under study.
-
Precedence. The variable has been widely used as a covariate previously, or within a particularly relevant prior study.
-
Intention. The investigator intends to control for the variable.
-
Statistical evidence. The inclusion of a variable is driven by statistical metrics such as -value, coefficient of determination variance inflation factor, and information criteria. Additionally, a variable may be incorporated due to the extent of its association with other variables. In some cases, the percentage of variance explained by each of the considered covariates has been utilized and ranked to assess their “worthiness” in the employed model. Stepwise procedures are taught in some textbooks as a means of automating variable selection based on the statistical strength of each variable in a data-driven manner.
However, it is essential to critically evaluate such strategies. For instance, can the inclusion of a covariate be justified solely based on its statistical strength? Moreover, adding a covariate may either strengthen or weaken the statistical evidence for the effect of interest. By what principle could we differentiate what is more reasonable?
These considerations give rise to three questions. First, do all covariates impact the effect of interest (or estimand) in the same way (and if not, how do we categorize their impacts)? Second, can a model be solely evaluated based on its own output? Third, how does the inclusion of a covariate affect interpretation of the model results? As we discuss further below, including a covariate without accounting for its underlying causal relations with the explanatory variable and response variables may lead to erroneous interpretations.
2. A toy example
We present a toy example to illustrate and gain insights into the influence of a covariate. Readers are encouraged to modify the values and explore different scenarios using the publicly available code.[1] Here, we consistently refer to the relationship between a covariate and the impact of the explanatory variable on the response as “conditioning on ” Various terms are used in the literature to describe this process, including “adjust for,” “control for,” “covariate out,” “regress out,” “fix,” “remove,” and “partial out.” For clarity and consistency, we use the term “condition on,” aligning with the concept of conditional probability. This implies that when conditioning the analysis on a covariate, we assume that the covariate takes one of its specific values.
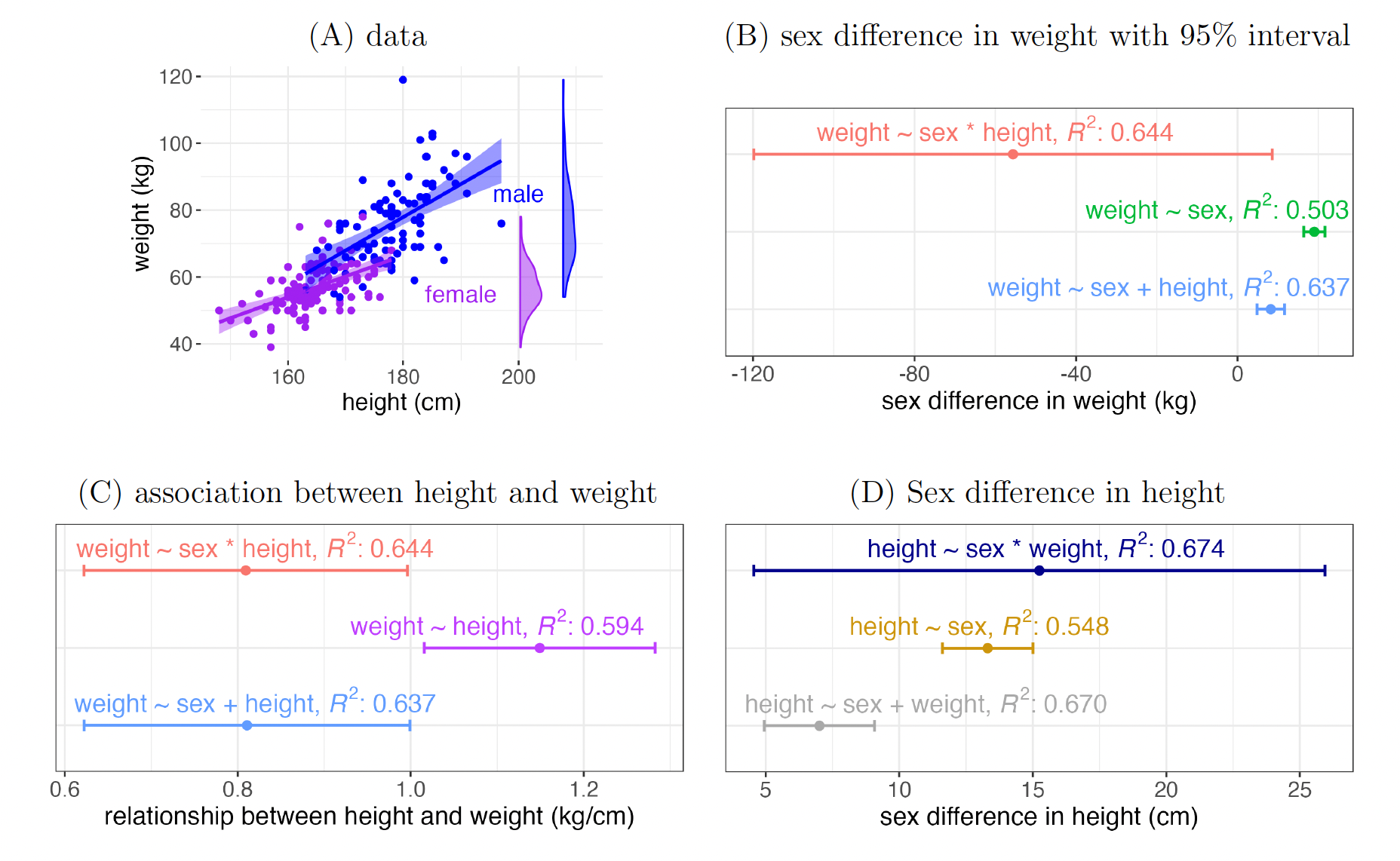
This example explores the relationships among height, weight, and sex in the adult population using a publicly available dataset10 consisting of 199 adults, including 111 females (Fig. 1A). The dataset serves as a platform for us to investigate the intricacies of different modeling approaches when examining three effects of interest: the disparity in weight between sexes, the overall relationship between height and weight, and the difference in height between sexes.
_real_data_from_199_participants_are_presented__.png)
2.1. Q1: What is the sex difference in weight?
First, we simultaneously estimate the effects of sex and height on weight and also account for their interaction,[2]
\[ \begin{align} \text{weight}_i &\sim \mathcal{N}( \alpha + \beta_{s}\,{\text{sex}}_i \\ &\quad + \beta_{h}\,\text{height}_{i} \\ &\quad + \beta_{X}\,{\text{sex}}_i:\text{height}_{i},~\sigma^{2} ); \\ ~i &= 1,2,...,199. \tag{1} \end{align} \]
With dummy-coded as 0.5 for a male and -0.5 for a female, the weight difference between sexes under the model 1 is estimated with a point estimate of -56 kg, a 95% interval (-120, 8) kg, and Such a mostly negative estimate seems to contradict the common sense as well as the data visualization in Fig. 1.
As an alternative, we could use a straightforward model that corresponds to a conventional two-sample -test,
\[ \begin{align} &\text{weight}_i\sim \mathcal{N}(\alpha+\beta_{s}\,{\text{sex}}_i,~\sigma^{2})\,. \end{align} \tag{2}\]
This yields a point estimate for of 19.0 kg with a 95% interval (16.4, 22.6), which is more consistent with the data (Fig. 1B); the overall goodness of fit is lower than the previous model:
Finally, we include height as a covariate but not the interaction between sex and height:
\[ \begin{align} &\text{weight}_i\sim \mathcal{N}(\alpha+\beta_{s}\,{\text{sex}}_i+\beta_{h} \,\text{height}_{i},~\sigma^{2}). \end{align}\tag{3}\]
In this case, has a point estimate of 8.2 kg, a 95% interval (4.8, 12.6), and (Fig. 1B).
How can we evaluate each of these three models? The two-sample -test 2 excludes height as a covariate and aligns with our intuitive expectations, although it produces the lowest coefficient of determination While the most complex model 1 boasts the highest its estimate contradicts common sense and the data. Model 3, which includes height as a covariate without an interaction, explains nearly the same proportion of data variability as model 1, but its estimate falls below that of the two-sample -test 2. Common sense cannot help us differentiate the adequacy between the two, leaving a potentially inconclusive situation.
2.2. Q2: What is the association between height and weight?
We adopt three distinct models to estimate the overall relationship between weight and height. Recycling the two models 1 and 3 leads to a virtually identical point estimate for : 0.81 kg/cm, with a 95% interval (0.62, 1.00) kg/cm and values provided above. However, opting for a straightforward linear regression,
\[ \begin{align} &\text{weight}_i\sim \mathcal{N}(\alpha+\beta_{h}{\text{height}}_i,~\sigma^{2}), \tag{4} \end{align}\]
yields a different estimate for : 1.15 kg/cm, with a 95% interval (1.02, 1.28) kg/cm and (Fig. 1C).
Again, some outcomes are similar and some are different, we do not have a straightforward means to critically differentiate between the three models 1, 3 and 4. As a consequence, the choice among these models remains unresolved. As displayed, perhaps the additional statistical evidence of the would be the leading contender for guiding the decision-making process, but we have already seen issues with that criterion.
2.3. Q3: What is the sex difference in height?
The estimation of the sex difference in height parallels the process applied to the sex difference in weight, as detailed in Section 2.1. We explore three distinct models, as follows:
\[ \begin{align} \text{height}_i \sim \mathcal{N}( \alpha &+ \beta_{s}{\text{sex}}_i \\ \quad &+ \beta_{w}{\text{weight}}_i \\ \quad &+ \beta_{{X}}{\text{sex:weight}}_i,~\sigma^{2} ) \end{align}\tag{5a} \]
\[ \begin{align} &\text{height}_i\sim \mathcal{N}(\alpha+\beta_{s}{\text{sex}}_i,~\sigma^{2})\end{align}\tag{5b}\]
\[ \begin{align} &\text{height}_i\sim \mathcal{N}(\alpha+\beta_{s}{\text{sex}}_i+\beta_{w}{\text{weight}}_i,~\sigma^{2}) \end{align} \tag{5c}\]
These models produce distinct outcomes (Fig. 1D). Their respective estimates for are 15.25, 13.31, and 7.01 cm, with respectively accompanying 95% intervals (4.55, 25.94), (11.61, 15.01), and (4.95, 9.07), and corresponding values 0.674, 0.548, and 0.670. Selecting the most appropriate model remains unclear.
2.4. Three implications
This illustrative example unveils three pivotal insights. First, the inclusion of a covariate can be detrimental and result in biased estimation (Fig. 1B,D). Second, statistical evidence based on a model alone cannot be used to determine its adequacy. In both sex difference in weight and height, the most complex models, 1 and 5a, have the highest but the corresponding effect estimation is quite different and less precise than alternative models. Third, one cannot rely on a single complex model to estimate all relevant effects. Instead, separate models may be required for individual effects, as shown in the two-sample -test models of 2 and 5b.
A fundamental question remains even in this simple toy model: how can we effectively evaluate the adequacy of a model? The example vividly illustrates that conventional statistical metrics alone are inadequate for this task. Simply comparing models based on their ability to explain variability falls short of guaranteeing a meaningful answer. Instead, we need a principled way to determine when it is beneficial or detrimental to include a covariate. In the next section, we will discover that a more robust approach to differentiating models relies on external information. Specifically, it involves leveraging prior knowledge about the relationships among the explanatory variable, the response variable, and possible covariates.
3. Causal inference and directed acyclic graphs (DAGs)
One fundamental aspect of covariate selection relies on a comprehensive grasp of causal relationships, a concept extensively explored through causal inference.2 This understanding provides a logical and consistent framework for addressing questions related to model structures, covariates, and interpretation. In this context, we apply causal inference to the toy example, demonstrating how it resolves issues and apparent discrepancies. Moreover, we posit that causal inference offers a valuable framework to assist researchers in experimental design and analyses, thereby enhancing study interpretability and reproducibility.
Unlike mere associations, causal relationships inherently possess directionality, indicating that influence flows from the cause to the effect, not vice versa. The directed acyclic graph (DAG) representation is central to illustrating the relationship between an explanatory variable and a response Thus, when establishing a causal connection between and it is visually represented as signifying that exerts influence on In dealing with multiple variables, a DAG, like a flowchart-style structure,12 can be employed. This graphical tool serves to depict prior knowledge or hypothesized relationships among variables, offering an intuitive yet rigorously precise means to assess and present model constructions with conceptual clarity. DAGs can then be heuristically translated into model formulations, serving a similar graphical and organizational purpose to Feynman Diagrams in particle physics.
3.1. Basic DAG terminology: causal relationships, path types and more
We note some of the most widely concepts in DAGs.
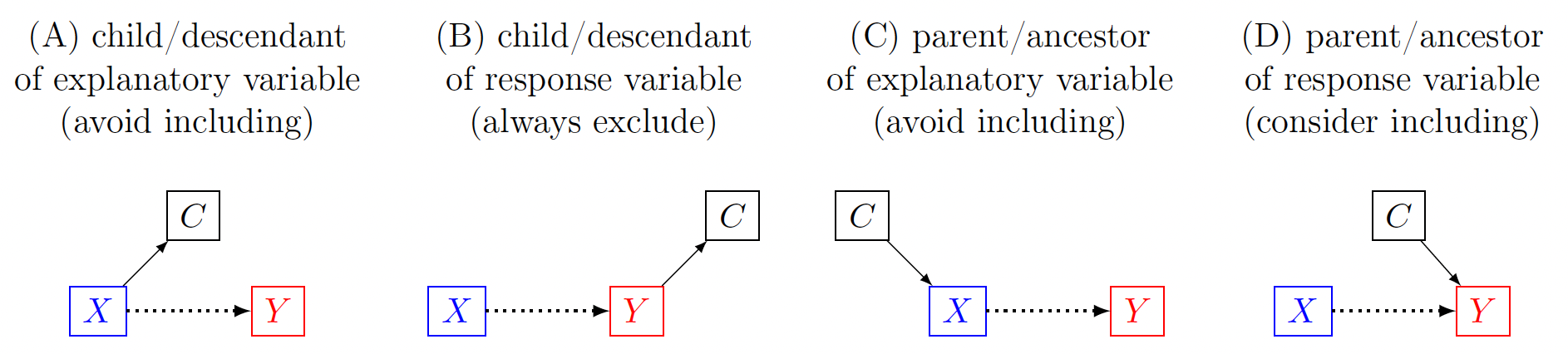
Components. Three components are associated with a DAG: nodes, arrows, and paths. Nodes (or vertices) represent the variables under investigation, while arrows (or arcs) symbolize the directional causal connections between these variables. By convention, the arrows are typically arranged in a consistent visual direction (e.g., left to right). A path is formed by a sequence of arrows, regardless of their direction, connecting the explanatory variable to the response variable (e.g., Fig. 2A).
_types._the_relationship_under_study_is_between_an.png)
Relationships. There are three principal categories of covariate relationships, which are demonstrated in Fig. 2. The covariate is a:
-
confounder (or fork) if it influences both and (Fig. 2A) as a common cause (or common parent).
-
collider if it is influenced by both and (Fig. 2B); that is, it is a common effect (or common child).
-
mediator (or pipe/chain) if it is influenced by while it also influences (Fig. 2C).
These three types provide a transparent way to convey the analyst’s prior information, theoretical constructs, and assumptions. The impact of each on the interpretation for the relationship between and will be discussed in the next three subsections.
Path categories. Causal inference relies on the categorization of paths between and This can be done in two distinct ways, by distinguishing: between causal and noncausal paths, or between open and closed paths. A path is called causal when all arrows point away from and towards (e.g., as in Fig. 2C); otherwise, it is considered noncausal (e.g., in Fig. 2A; in Fig. 2B). Furthermore, a causal path can be either direct (i.e., or indirect (e.g., Fig. 2C). Paths within a DAG are categorized as open or closed depending on their impact on the response variable. An open path permits the response variable to vary freely, operating independently of other variables in the DAG. It lacks colliders and signifies potential causal relationships. Conversely, a closed path restricts the response variable from varying independently; it includes one or more colliders. A backdoor path is a non-causal path or one with an arrow entering the explanatory variable, while a front-door path is characterized by all arrows pointing away from the explanatory variable. A minimally sufficient set refers to the smallest set of variables that, when conditioned upon, effectively closes all open non-causal paths. This classification has a direct link to interpretation: open paths represent statistical association, while closed paths indicate the absence of statistical association. In essence, identifying a causal relationship involves closing (or blocking) all noncausal paths.
Parent/child relations. Four auxiliary cases are worth discussing. When a covariate is connected with either the explanatory variable or the response is a child (or descendant, or proxy; Fig. 3A-B) or a parent (or ancestor; Fig. 3C-D). In each of these four cases, is referred to as neutral in the sense that it is not on a causal path between and Subtleties abound among these four cases. As a child of (Fig. 3A), is sometimes referred to as a post-treatment variable, and it is generally not recommended to use as a covariate because it typically leads to reduced precision13–15 or to biases, especially when the explanatory variable contains measurement errors.16 When is a child of (Fig. 3B), conditioning on would incur biases.17 When is a parent of (Fig. 3C), it is a precision parasite because conditioning on may lead to degraded precision. In contrast, as a parent of (Fig. 3D) may help improve precision.17 For this reason, it is termed as a precision variable,18 additive exogenous covariate, or competing exposure.

Causal effects. The value of a DAG rests in its direct representation of the underlying processes that generate the data. Causal relationships are characterized by paths via arrows that are always in the direction from the explanatory variable to the response variable (e.g., a path through a mediator in Fig. 2C). The total causal effect encompasses the combined influence over all causal paths. A direct causal effect signifies an impact that does not flow through any mediator.
3.2. Variable type: confounder
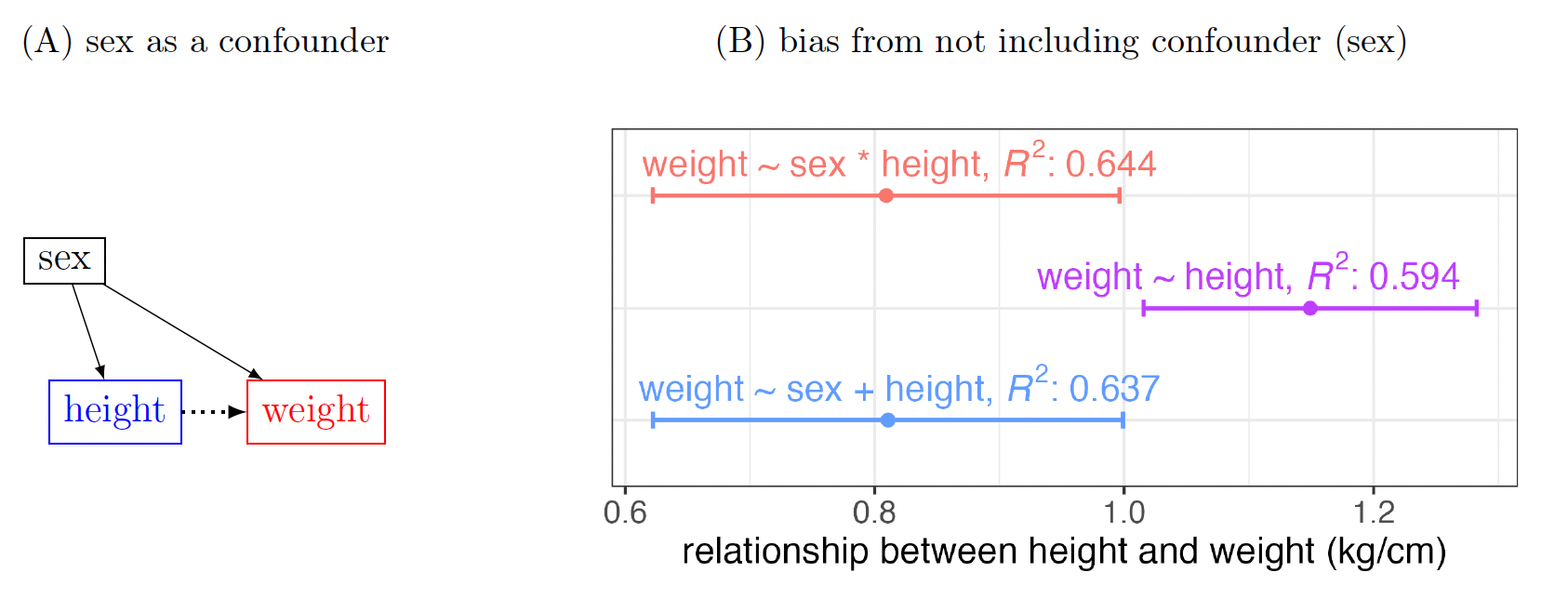
As a general rule, a confounder should always be conditioned on. A confounder serves as a common cause for both and As such, apart from the direct causal path the presence of the confounder means there is also a noncausal, open path If is not conditioned on, this noncausal path is not closed, and when interpreting the model results we cannot distinguish whether any observed association is a result of the direct causal path or of the influence of the noncausal path. This ambiguity will harm the accuracy and precision of effect estimation. Thus, it is essential to close the noncausal path by conditioning on the confounder, enabling one to adequately establish the causal effect of on
Understanding the role of a confounder is crucial for elucidating key aspects of model construction. Take, for instance, the classic phenomenon of spurious correlation in ratios19 in compositional data analysis. When three variables– and –are mutually independent, the correlation between and is essentially zero. However, the correlation between the ratios and can be remarkably high (e.g., 0.5 in cases with uniform distributions for each variable). What might seem like “spurious” correlation in the latter scenario arises due to the confounding role of Another popular instance of overlooking a confounder is illustrated by Simpson’s paradox.1 In general, biased estimation due to the failure of conditioning on a confounder can occur in various directions such as overestimation, underestimation, masking a true effect, sign reversal, and spurious effect.
The relationship between height and weight in Q2 of the toy example also illustrates the consequences of not conditioning on a confounder. Previously, it was uncertain regarding which estimation among the three models in Fig. 1 (also shown in Fig. 4B) was more accurate. However, as depicted in the DAG in Fig. 4A, sex is a confounder, so it should be included as a covariate. If it is not conditioned on, the estimation from the simple regression 4, weight height, will be biased. We will later discuss the subtle differences between the other two models that include sex as a covariate, one with and the other without the interaction.
_the_dag_portrays_sex_as_a_confou.png)
3.3. Variable type: collider
It is essential to avoid conditioning on a collider. From the DAG perspective, a path with a collider is noncausal and closed Fig. 2C). Conditioning on collider effectively adds the noncausal path between and leading to biased estimation. Selection bias is actually one common manifestation of inappropriately including a collider as a covariate, and this may produce a counterintuitive association between and also known as Berkson’s paradox.1 In general, biases may occur in various directions such as overestimation, underestimation, masking a true effect, sign flipping, and spurious effect.
We emphasize that the presence of colliders often affect the accuracy, as well as the generalizability, of results; simply increasing sample sizes will not remove their effects and or decrease the likelihood of misinterpretation. Within neuroimaging, generalizability based on consortium data gathered from prospective studies (e.g., UK Biobank, ABCD) will still be susceptible to collider bias, such as from uneven representativeness and attritions (e.g., missing data) across different groups.20–23 It is important to note that studies based on these large datasets can certainly avoid collider bias, but merely that explicit care should be taken when filtering subjects and dealing with large numbers of potential covariates.
In Q3 of the toy example, we examined sex differences in height with three possible models, each of which dealt differently with including weight as a possible covariate. We can draw a DAG for these variables to provide a principled perspective. Since weight is influenced by both sex and height, it is a collider (Fig. 5A), and should not be conditioned on. Fig. 5B shows the estimates for the sex difference of height in the various scenarios. These findings aptly showcase the biases and compromised precision when a collider is included as a covariate.
_the_dag_portrays_weight_as_a_collider_between.png)
3.4. Variable type: mediator
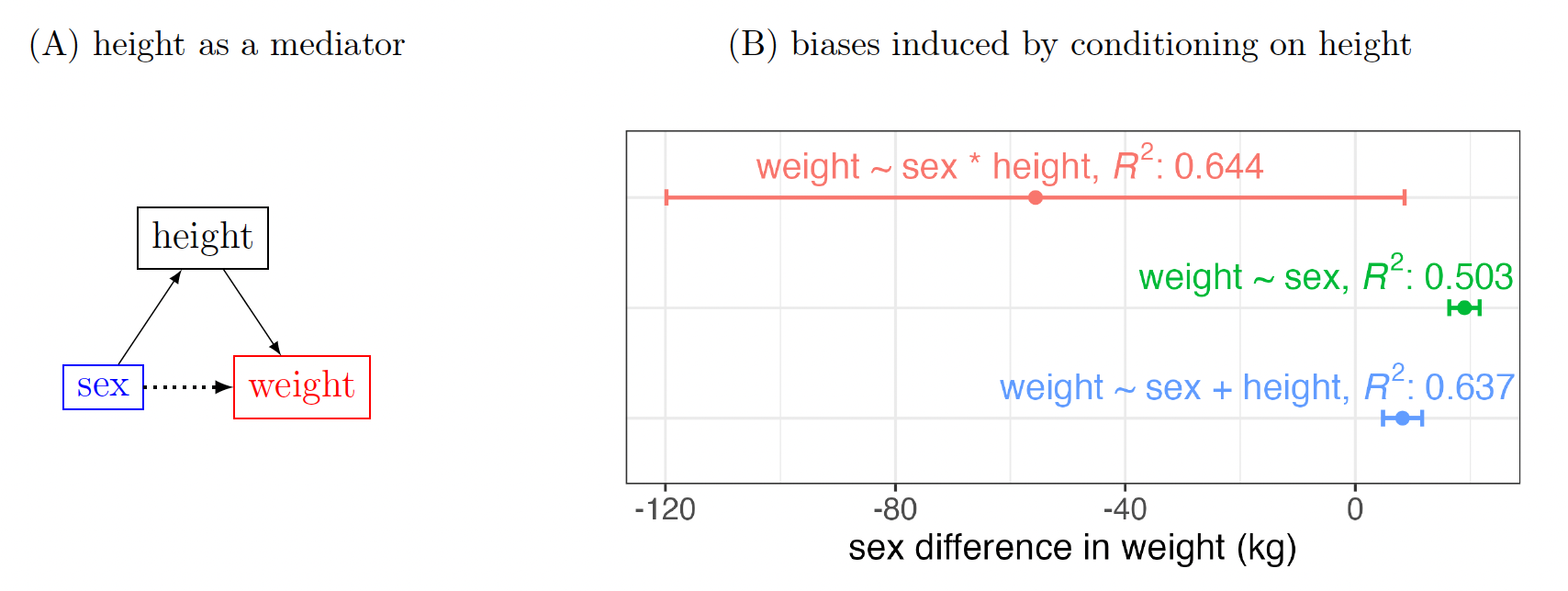
The impact of a mediator is subtle, affecting result interpretability, and should be treated with extreme caution. When a mediator is present, at most two causal paths allow information flow from to : the direct causal path and the indirect causal path where is the mediator. In the case of full mediation, only the indirect path remains, as the direct path is absent. One may be interested in the total effect, which contains the contribution of both causal paths, or in the direct effect, which contains only the direct causal path and excludes the indirect path. If the total effect of on is desired, the covariate should not be conditioned on; otherwise, the indirect causal path would be closed, and part of the causal effect would be missing from the estimation. On the other hand, if the direct effect of on is desired, one should close off the indirect causal path by conditioning on otherwise, information would be contaminated by the indirect causal path. In general, biased estimation of the total effect from conditioning on a mediator may occur in various directions such as overestimation, underestimation, masking a true effect, sign reversal, and spurious effect.
Q1 in the toy example investigates the weight difference between sexes, serving as a prototypical case of a mediator. Figure 6A illustrates the DAG that encapsulates our prior knowledge, indicating that sex influences height when considering the impact of sex on weight. This scenario naturally gives rise to two distinct types of inquiries. Firstly, one can explore the total effect: What is the weight disparity between sexes? Secondly, one could address a counterfactual question by focusing on just the direct effect: Assuming we know an individual’s height, what would be the weight difference if that individual is male as opposed to female?
In the presence of a mediator, researchers often seek to understand the total effect. For instance, when comparing weight between sexes, a straightforward approach is to construct a basic model of a two-sample -test: weight sex. In contrast, introducing height as a covariate would lead to biased estimation (Fig. 6B). In the DAG language, this action effectively closes off the indirect causal path (sex height weight, Fig. 6A), adversely affecting what we would view as the total effect.
_the_dag_portrays_height_as_a_mediator_between.png)
There are times when researchers may focus on the direct effect in the presence of a mediator. For example, one might be interested in understanding the influence of sex on weight when both sexes share the same height. This scenario is often framed as a counterfactual inference: given the prior knowledge of an individual’s height, what additional insight does knowing their sex provide? Estimating such a direct effect typically may require employing an analytical technique known as centering, a topic we will elaborate in the next section.
4. DAG applications
The preceding discussion provided a basic background for causal inference. This commentary does not aim to comprehensively cover all aspects. Extensive discussions can be found in the literature.2,16,17,24–26 In typical analyses, DAGs involve numerous variables with intricate paths that are more complex than what are represented in Figures 2 and 3. In other words, constructing a comprehensive DAG that captures all potentially relevant causal relationships could easily result in an overwhelming number of variables, including latent ones. In such cases, one may have to be realistic about the model complexity and manageability, while still avoiding modeling pitfalls. Focusing on causal relationships facilitates not only the formulation of accurate models but also the evaluation of model results. Below, we apply the concept of DAGs to a few modeling scenarios, including the motivating example in the Introduction, and demonstrate the importance of contextual knowledge in understanding the interrelationships among the variables and in model building.
4.1. Impact of reversing explanatory variable and response variable
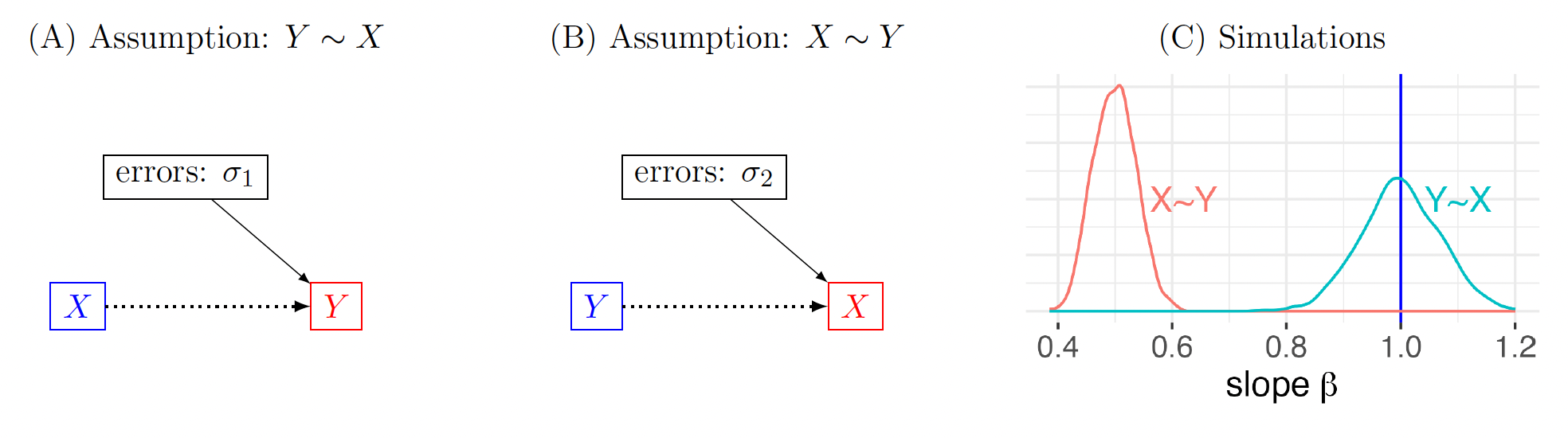
The position and the labeling of variables in a model reflect the analyst’s prior knowledge about their relationships. This is directly relevant to the first item in the motivational example list in Sec. 1.1: What is the consequence of switching an explanatory variable with the response variable in a model? Consider a simple relationship with only two variables, in which an explanatory variable is assumed to influence the response variable : If linear, this relationship can be expressed as a simple regression:
\[ Y \sim \mathcal{N}(\alpha_{1}+\beta_{1} X,~\sigma_{1}^2),\tag{6}\]
where and are the model intercept, slope, and standard deviation, respectively.
For comparison, we construct another model by reversing the two variables, which introduces a different set of parameters and :
\[ \begin{align} & X \sim \mathcal{N}(\alpha_{2}+\beta_{2} Y,~\sigma_{2}^2). \end{align}\tag{7}\]
When analyzing a dataset, we have the option to adopt either model and estimate the corresponding parameters. It can be argued that the sample Pearson correlation between the two variables of and remains the same regardless of the adopted model. Furthermore, if one solely focuses on statistical evidence, the two models provide the same - or -statistic values. However, even seemingly immutable correlation and statistic values may vary between the two models, particularly when covariates are introduced into the analysis. Moreover, the numerical algorithm of ordinary least squares minimization, as commonly used in conventional statistics, yields different estimates for the two slopes,
\[ \begin{align} & \widehat{\beta}_{1}=r\frac{S_Y}{S_X}, & \widehat{\beta}_{2}=r\frac{S_X}{S_Y}, \end{align}\tag{8}\]
where and are the sample standard deviations of and respectively. As these estimates are not reciprocally related, except in a very special case: we only have equivalence if and only if For all other cases, the effect estimate would differ due to the opposite labeling of variables.
What causes this observed asymmetry? The dissimilarities between these two models 6 and 7 run deeper than their surface dissimilarities. By taking the algebraic perspective of their respective optimization procedures, we can unearth these distinctions. Alternatively, one can approach a regression model as a prediction challenge, where ordinary least squares plays a role as a type of regularization or penalty. Put it in another way, the biased estimation in the model 7 can be attributed to being an endogenous variable.
Here, we examine the two models from the lens of causal inference. A statistical model should be constructed based on its underlying causal assumptions, rather than solely on its output. Both models 6 and 7 can technically offer an estimate of the relationship between variables and However, neither of these models can independently justify their own output. Instead, model choice is guided by the effect of interest and the causal relationships associated with it. The first model, where we regress on implies an information flow from to with an error term that represents a stochastic process, encapsulating the data variability that cannot be entirely accounted for by From the DAG perspective, this error term can be considered as a parent of (Fig. 7A). In contrast, the regression of on assumes an information flow from to with an error term as a parent of (Fig. 7B). As a result, these two models imply distinct data generating processes, and the appropriate one should be that which most closely represents our prior knowledge. The special case in which the coefficients of and are symmetric occurs only when with no measurement error in the response variable In addition, the distortion in effect estimation by the second model would be exacerbated in the presence of covariates.
_the_regressio.png)
Simulations prove to be a valuable tool in highlighting the distinction between the two models. As depicted in Fig. 7C, it is evident that an incorrectly specified model, characterized by swapping the explanatory variable and the response variable, may introduce a bias towards zero in effect estimation. This underestimation is closely associated with the concept of “regression dilution” or “regression attenuation,” stemming from inaccuracies in the explanatory variable.27 This observation serves as a poignant reminder of a fundamental principle: a model, by itself, cannot rectify an unsuitable specification or affirm its validity. Instead, constructing an appropriate model requires the domain knowledge about variable relationships.
In Q2 of the toy example, the association between height and weight also showcases the importance of differentiating the explanatory variable and the response variable. It is reasonable to assume that height influences the weight, and not the other way around. When modeled as such, the association is estimated as 0.81 kg/cm with a 95% interval (0.62, 1.00) (Fig. 1C) based on the model 1, weight sex height sex:height. On the other hand, if we switch height and weight, the alternative model 5a, height sex weight sex:weight, would lead to an effect estimate of 0.36 cm/kg with a 95% interval (0.27, 0.44), which equates to 2.78 kg/cm and 95% interval (2.27, 3.70). This is a substantial overestimation compared to the estimate of 0.81 kg/cm with a 95% interval (0.62, 1.00) (Fig. 1C) based on the model 1.
The comparison between the two models can be framed as a sensitivity analysis. To assess the robustness of causal conclusions to changes in assumptions, model specifications, or data perturbations, sensitivity analysis evaluates the extent to which the results of a causal analysis are influenced by various factors and to identify potential sources of bias or uncertainty. In general, the analyst may modify the DAG under study, comparing the effect estimates to gauge sensitivity to alterations in underlying assumptions. This approach aids in comprehending how varying assumptions affect conclusions about causal relationships. In this specific scenario involving the causal relationships of and where the former represents the assumed causal relationship, the model comparison illuminates the consequences of adopting an incorrect causal relationship.
4.2. Enhancing intepretability through covariate centering
Covariate centering is a crucial analytical technique in data analysis. Rather than directly using the values of a quantitative covariate, this method involves subtracting a specific number from the covariate values before incorporating them into the model. This number can be the mean, mode, median, or a value of particular interest to the analyst. With a rich history,14,28,29 this technique offers at least two distinct advantages. First, it enhances conceptual interpretability. Without centering, the intercept is linked to the covariate at 0, often lacking practical utility. But with centering, the intercept becomes associated with a covariate value that holds practical meaning. This convenience of interpretability extends even to categorical variables, as seen in our coding strategy for sex, with -0.5 and 0.5 assigned to females and males in models such as 1-3. In general, for a factor with two or more levels, deviation coding can be adopted to achieve the interpretation convenience. Second, centering addresses concerns related to multicollinearity. For example, product interactions typically exhibit high correlation with their main effects. Centering also provides the added benefit of enhanced numerical stability by reducing the extent of collinearity.
4.2.1. Covariate centering through the lens of causal inference
To illustrate the crucial role of centering, consider the sex difference in weight in Q1 of the toy example, where height is included as a covariate. The challenge with the model 1, is the following. It effectively estimates the sex difference in weight at an extrapolated point where both sexes have a height of 0 cm. Consequently, the resulting estimate of -56 kg, with a 95% interval of (-120, 8) (Fig. 8A,E) lacks practical interpretability. This interpretation issue can be technically resolved through centering. Specifically, we refine the original model by introducing a centering parameter:
\[ \begin{align} \text{weight}_i&\sim \mathcal{N}(\alpha+\beta_{s}{\text{sex}}_i+\beta_{h} (\text{height}_{i}-\text{h}[\text{sex}_i]) \\ &\quad + \beta_{X} {\text{sex}}_i:(\text{height}_{i}-\text{h}[\text{sex}_i]),~\sigma^{2}), \tag{9} \end{align}\]
where is the center value for each sex. This height-centered model allows one to make two types of inference. First, when we set to the within-group mean, then is interpreted as the sex difference in weight at each group’s mean height (Fig. 8B), resulting in an estimate of 19.0 kg with a 95% interval (16.7, 21.3), close to the result from the two-sample -test (Fig. 8E). Alternatively, if we choose a common center (e.g., the overall mean or a specific height), represents the sex difference in weight, assuming that both sexes share the same height at this center value. This second centering method addresses a counterfactual question: when the height is known, what extra information could sex provide about weight difference? For instance, at a common height of 190 cm, the sex difference in weight is estimated as 15.2 kg with a 95% interval (7.5, 22.9) (Fig. 8E).
_the_estimated_difference_between_sexes_base.png)
Causal inference offers a fresh perspective into the centering technique. When the explanatory variable is a categorical variable, centering artificially shifts and aligns the original data to the center value. In the toy example’s Q1 with height as a mediator (Fig. 8C), one should not include height as a covariate when focusing on the total effect. However, we know a priori that males are on average taller than females (as shown in the relationship of sex height in the DAG). Centering effectively removes the causal arrow from sex to height (and blocks the indirect causal path sex height weight in the DAG). Thus, this process changes the original role of height from a mediator to just a parent of the response variable (Fig. 8D). More specifically, the total effect can be obtained through within-group centering, because the new height variable has zero mean for both groups. On the other hand, with height is a mediator, the direct effect can be estimated through cross-group centering, wherein a common center is removed from both groups. In other words, centering can convert the originally inappropriate model for total effect to one that can estimate either total effect or direct effect. When dealing with multiple covariates, it is essential to individually justify the inclusion of each one, as well as the decision to adopt a centering strategy.
Centering can be conceptualized as a process of resolving collinearity issues. A mediator is typically correlated with the explanatory variable because the latter influences the former. Centering effectively reparameterizes the model and reduces the level of correlation. Covariate effect is often parameterized as an additive effect in common practice, without considering potential interactions and nonlinearity. In the case of the sex difference in weight, if the interaction between sex and height is not considered, the model leads to a substantial effect underestimation, with an estimated weight difference of 8.2 kg and a 95% interval (4.8, 11.6) (Fig. 8E). From the causal inference perspective, this underestimation is due to the inclusion of a mediator when the total effect is the focus. On the other hand, we consider the following model through within-group centering,
\[ \begin{align} \text{weight}_i \sim \mathcal{N}( \alpha &+ \beta_{s}\text{sex}_i \\ &+ \beta_{h} (\text{height}_{i} - \text{h}[\text{sex}_i]),~\sigma^{2} ) \tag{10} \end{align} \]
where is set as the average height for each sex. Estimation improvements become evident. First, centering removes the arrow from sex to height and legitimizes the inclusion of height as a covariate. Moreover, this height-centered model yields an estimate of 19.0 kg with a 95% interval (16.7, 21.3), which is comparable to the result of the two-sample -test as well as that of the height-centered model with interaction (Fig. 8E). That is, while effectively reducing the correlation between sex and height, centering enhances estimation accuracy.
A caveat regarding centering should be noted. When a mediator is present, the approach of within-group centering, illustrated in Fig. 8D, remains valid if the relationship between the mediator and the response variable is linear. However, if nonlinearity is present, within-group centering may become inappropriate. In such cases, the model must be aligned directly with the structure outlined in the corresponding DAG to ensure validity.
4.2.2. Different modeling strategies
An effect of interest can typically be estimated using various models. Consider the total effect of sex difference in weight in Q1 of the toy example. We have discussed three different models: two-sample -test 2, the height-centered GLM 9 with interaction, and the height-centered GLM 10 without interaction. Since uncentered height is a mediator, we do not include it as a covariate, adopting the most straightforward approach for total effect, the two-sample -test. On the other hand, centering converts height from a mediator to a parent of the response variable (weight). Both GLMs, as alternative approaches, offer estimations that are similar but slightly more precise–though the improvement is negligible–when compared to the two-sample -test (Fig. 8E). The difference between the two GLMs hinges on whether the interaction should be included, a subtlety we will address in a sequel of this commentary.
Model selection also occurs in estimating the association between height and weight in Q2 of the toy example. Sex is a confounder (Fig. 4A); thus, it should be included as a covariate. However, we still need to decide whether to incorporate the interaction between sex and weight.[3] The decision regarding the inclusion of the interaction between sex and height revolves around model parameterization. This choice hinges on the additional research interest in exploring potential differences in the slope effect of height between the two sexes. In this particular case, both approaches yield nearly identical estimations (Fig. 4B). Nevertheless, the inclusion of the interaction lends to more informative inference about the interaction: the sex difference in the association between height and weight.
Centering may also help simplify the modeling process. Suppose that we are interested in three effects: the total effect between sex and weight, the association between height and weight, and the interaction between sex and height. For the first effect, since height is a mediator, we would normally avoid it as a covariate, adopting a simple model such as a two-sample -test. For the association between height and weight, considering sex as a confounder, we would simply adopt a GLM such as weight sex height or weight sex height sex:height. For the interaction, we would choose the second model. However, through centering we can merge these three separate processes into a common model 9, estimating all three effects under a unified modeling framework.
The conventional mediation analysis may help dissect the total effect into direct and indirect (mediation) effects. In the toy example, the estimated total effect for the sex difference in weight is 19.0 kg with a 95% interval (16.7, 21.3) (Fig. 8E). Mediation analysis reveals a direct effect (via the direct causal path sex weight, Fig. 8C) of 7.9 kg with a 95% interval (4.2, 11.0) at the cross-group mean height of 170.6 cm and an indirect effect (via the indirect causal path sex height weight, Fig. 8C) of 10.9 kg with a 95% interval (7.97, 14.1). In essence, when both males and females share an identical height of 170.6 cm, males weigh approximately 7.9 kg more than females. This weight difference slightly varies when their height is smaller or larger (Fig. 8B). An additional 10.9 kg in the total weight difference of 19.0 kg is attributed to the mediation effect of height (i.e., males being taller than females). However, caveats exist regarding mediation analysis.31 For example, a confounder between the mediator and the response variable may bias the estimation of direct and indirect effects.
4.2.3. Subtleties of centering
Some cautions should be practiced in centering. One subtlety pertains to the selection of center values. For the toy example, to directly compare with the two-sample -test result, mean-centering can be adopted in the GLM 9. In this case, the height distributions are approximately symmetric for both sexes (Fig. 1A), making mean-centering a suitable choice. However, in other scenarios, data could be skewed, and it might be more appropriate to choose a center based on the mode, median, or a particularly meaningful value. Adaptivity in centering is crucial for accurately representing the characteristics of the data under investigation.
Centering may not always be feasible or applicable in the presence of a mediator. When the mediator has a discrete distribution (e.g., binomial) among groups, or when the explanatory variable is a quantitative variable rather than an individual-grouping factor (e.g., sex), centering is inapplicable. For instance, consider a neuroimaging study where sleep quality serves as an explanatory variable for BOLD response, and memory performance acts as a mediator. Since both sleep duration and memory measure are quantitative variables, there is no effective centering method on sleep quality that could justify the incorporation of memory performance as a covariate. In such cases, it is advisable to refrain from including a mediator if the primary interest lies in the total effect.
4.3. Selection biases in neuroimaging
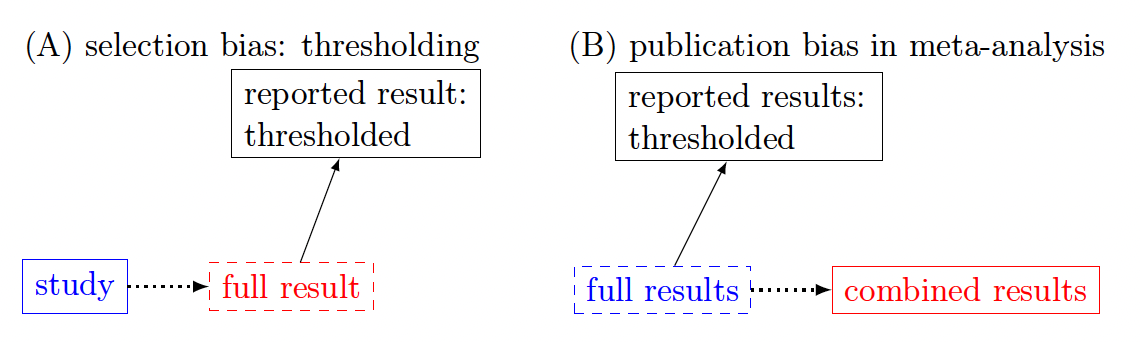
Selection biases do occur in neuroimaging studies. The controversial practice of “double dipping” or the circularity problem is such an example (Fig. 9A). The issue pertains to a scenario in which the same data are utilized for both selecting regions of interest or conducting analyses and later for evaluating the statistical evidence of the findings. This practice can result in inflated estimates, potentially resulting in misleading conclusions.32,33
_the_reported_result_is_a_descendant_of_th.png)
The neuroimaging field has largely been aware of the negative impact. Nevertheless, we can still instructively view it through the causal inference lens. Take a task-based experiment as an example, and picture the task as an explanatory variable and the full analytical results as the response variable. In the primary stage of analysis, one may select a small proportion of the result based on statistical thresholding, and then proceed with a follow-up stage such as correlation analysis with behavioral data or classification. The thresholded result is a descendant of the full result (Fig. 9A). Therefore, this kind of practice contains heavy biasing for the actual relation of interest (typically overestimating the strength of relation).
However, another form of selection bias often lurks within common practices. There has been a strong emphasis in neuroimaging on the strictness of result reporting, particularly due to concerns about the multiple testing issue. As an isomorphic counterpart of the “double dipping” case, the thresholding step in result reporting plays the role of conditioning on a descendant of the response variable (Fig. 9A). Consequently, selection bias resulting from applying stringent thresholding becomes evident from the causal inference perspective, commonly known as publication bias or the file drawer problem.
The consequences of such selective reporting methods lead to severe reproducibility challenges. For instance, subsequent meta-analyses would inherently condition on a descendant of the explanatory variable (Fig. 9B). Thus, summarized results are unavoidably biased and distorted due to the combination of three factors: selection biases due to the filtering process through stringent thresholding, the reduction of the full results to peak voxels, and the absence of effect quantification. As a result, findings that are largely consistent might likely be misperceived as differing, fueling views of a reproducibility crisis. Addressing the issue of selection bias, stemming from the emphasis on stringency and the artificial dichotomization, can be ameliorated through alternative approaches. These include placing a greater focus on model quality and effect estimation rather than decision-making solely based on statistical evidence,34 and adopting a “highlight, don’t hide” reporting strategy for studies, where more information is preserved and thresholding is de-emphasized.35
4.4. Revisiting the motivating example
We now return to the motivating example in Sec. 1.1 and try to address the questions raised within the causal inference framework. The central objective is to explore the relationship between gray matter density (GMD) and short-term memory (STM). Fig. 10 illustrates the DAG representation we conceive for the interrelationships among the seven variables. Through this DAG, the assumptions and domain expertise governing the underlying data-generating process are effectively delineated and communicated. Specifically, we postulate a causal link from GMD to STM, and from intracranial volume (ICV) to GMD. In addition, sex is known to influence ICV, GMD, and weight.36,37 Furthermore, the apolipoprotein E (APOE) genotype’s impact extends to both STM38 and weight.39 Additionally, age is assumed to affect GMD, ICV, and STM.
We now directly address the four questions raised in the Introduction.
-
Explanatory variable versus response variable. The behavioral measure STM yields a single value per individual, while the structural measure GMD is estimated at each spatial element (voxel) within a 3D image of each individual. Conventional analytical software typically operates with 3D images as the response variable, which may lead one to consider constructing a model with GMD as the explanatory variable and STM as the response variable. However, from a cognitive standpoint, it is imperative to recognize that brain structure exerts a causal influence on an individual’s behavior. Therefore, it is more conceptually sound to consider the causal direction of GMD influencing STM (GMD STM). Conversely, estimating the causal relationship of STM influencing GMD (STM GMD) lacks causal plausibility. As discussed in Section 4.1, a model constructed with the causal assumption of STM GMD would result in biased estimation.
-
Covariates. We expound our decision about each variable based on the DAG presented in Fig. 10.
-
Age is in an open noncausal path (GMD age STM). As a confounder, it should be included as a covariate.
-
Sex, similar to age, lies in an open noncausal path (GMD sex STM), and is also a confounder. Thus, it should be conditioned on.
-
APOE only influences the response variable, but not the explanatory variable. As a parent of STM, its inclusion improves estimation precision.
-
Weight is a collider for sex and APOE through a noncausal, closed path (GMD sex weight APOE STM). However, given that sex acts as a confounder and should be conditioned on, incorporating weight as a covariate would neither introduce bias nor offer any benefit.
-
ICV only influences GMD, but not STM; thus, it is not on any causal or noncausal path. As a parent of the explanatory variable GMD, it should not be included as a covariate.
As a result, we may adopt the following model,
\[\begin{align}\text{STM} \sim \mathcal{N}( \alpha &+ \beta_{1}\text{GMD} \\ \quad &+ \beta_{2}\text{age} \\ \quad &+ \beta_{3}\text{sex} \\ \quad &+ \beta_{4}\text{APOE},~\sigma^2).\tag{11}\end{align}\]
-
-
Result interpretability/reporting. Although the model 11 can technically provide assessments for all parameters, not all estimates for sex, GMD, APOE, and age are directly interpretable. Each model is constructed within the framework of a DAG to estimate a specific relationship between the explanatory variable and the response variable. Hence, the parameter estimates for the covariates might not be appropriate due to potential bias. This is because if the focus switches to another explanatory variable or response variable, the causal relationship could undergo changes (e.g., a previous confounder might become a mediator). As a result, it may be necessary to develop a new model with a revised set of covariates to effectively capture these alterations. For instance, when estimating the total effect of sex on STM, we may condition on sex and APOE, but not on GMD (mediator). Consequently, the parameter estimate for age from the model 11 should not be reported unless the direct effect is the focus. The same issue applies to the parameter estimate of age.
-
Experimental design. Since weight neither provides additional benefits nor poses any harm, omitting weight from data collection could result in potential resource savings and model simplification. On the contrary, if the investigator hypothesizes that the hours of sleep before the experiment could impact participants’ STM performance, collecting sleep data may enhance estimation precision. This is because the quality of sleep serves as a parent variable influencing the response variable.
5. Discussion
In this commentary, we began with a motivating scenario and a toy example. The toy example of sex-height-weight offered an intricate array of interrelationships among variables. It aided in understanding three fundamental DAG structures: confounder, collider, and mediator. Specifically, sex has the role of a confounder between height and weight, weight serves as a collider between sex and height, and height acts as a mediator between sex and weight. Importantly, not all parameter estimations derived from each model are necessarily interpretable or meaningful, further underscoring the necessity of constructing a model for each particular effect of interest.
We then applied the DAG perspective to several real-world applications. First, we showed how reversing the relationship between an explanatory variable and the response variable can lead to misestimation. Second, we underscored the role of centering, which enhances interpretability by essentially transforming a mediator into a parent of the response variable. This not only simplifies the modeling process but also enables the derivation of multiple effect estimations from a unified model. Third, we argued that the prevalent practice of strict thresholding in result reporting and preparation for meta-analyses shares the same selection bias problem as the “double dipping” issue. Lastly, we brought our discussion full circle by addressing the initial questions posed in the motivating example.
5.1. DAG: rules for covariate selection
In statistics, the primary objective is to construct a model that most faithfully represents the system being studied. Here, we discuss how the relationships among variables are pivotal in constructing an accurate model that mirrors the underlying data-generating process–this is the underlying raison d’être for causal inference. The model’s validity should rely on our understanding of the data generation process, specifically the causal relationships among relevant variables. This critical information, however, is not entirely encapsulated by the data itself nor inherently embedded within the model. Hence, it is imperative to seamlessly incorporate this essential knowledge as prior information during model construction. In essence, model construction should be guided by domain expertise, allowing this recognized principle to steer the covariate selection process. This approach is preferable to relying solely on statistical metrics. While a DAG provides a framework for illustrating causal relationships among variables based on current knowledge, it does not inherently preclude estimation biases due to two key reasons: 1) domain knowledge may evolve over time, prompting updates to the DAG, and 2) effect estimation involves constructing models with specific parameterizations. However, failing to adhere to this principle carries the inherent risk of constructing a model that is fundamentally flawed, leading to potential misconstructions and misinterpretations of the underlying data-generating process.
A DAG, serving as a non-parametric graphical depiction of the data-generating process, elucidates the intricate interconnections and assumptions embedded within the considered variables. Much like architectural blueprints provide simple and efficient representations for construction, DAGs serve as a standardized tool that enhances communication by systematically categorizing and classifying diverse relationships among variables, grounded in contextual knowledge. DAGs offer a structured framework for organizing pre-existing knowledge, articulating the investigator’s assumptions, and fostering comprehension for the recipient. The explicit and transparent attributes of DAGs establish a shared foundation for communication, laying the groundwork for constructive debates, critiques, and comparisons of alternative DAGs and models. This clarity and openness not only facilitate a deeper understanding but also encourage a collaborative discourse that refines and advances the overall comprehension of the underlying data structure and relationships.
With DAG representations, guidance on the inclusion or exclusion of a covariate can be simplified to a few principles. The following rules should be adopted when considering variables, in order to generally improve model quality and avoid biased estimation:
-
Confounders should be included.
-
Colliders should not be included.
-
Mediators have an extra consideration, depending on the nature of the effect of interest:
-
Mediators should be included for direct effect.
-
Mediators should not be included for total effect.
-
-
Children/descendants of the response should not be included.
-
Children/descendants of the explanatory variable, when included, may hurt estimation precision.
-
Parents/ancestors of the explanatory variable, when included, may hurt estimation precision.
-
Parents/ancestors of the response variable, when included, improves estimation precision.
The above rules can be further simplified. The distinction between total and direct effects is most relevant when mediators are present. Specifically, the total effect represents the combined influence of all causal pathways, including both direct and indirect effects (via mediators), without distinguishing between specific mechanisms. On the other hand, the direct effect isolates the part of the total effect that occurs independently of any mediators, capturing the impact of the explanatory variable that does not pass through intermediaries. When no mediators are involved, this distinction disappears, leaving only the total effect. With this clarification, we can simplify the rules as follows:
-
For the total effect, include all parents of the response variable except for the descendants of the explanatory variable.
-
For the direct effect, include all parents of the response variable.
The rules outlined above are suitable for relatively simple DAG structures, but may face challenges in more complex cases, particularly when latent variables are involved. For example, if a confounder between the mediator and the response variable is latent between a parent of the explanatory variable and the response variable, that parent should be included as a covariate to account for potential bias. In more complex scenarios, the selection of covariates can vary depending on the specific criterion used (e.g., minimally sufficient adjustment versus necessary and sufficient adjustment). To facilitate accurate causal inference, we recommend using R packages like DAGitty40 or ggdag.41 These tools not only enable the creation, editing, and visualization of DAGs but also help identify which variables should be controlled for to estimate causal effects without bias.
Finally, we list some common varieties of biased estimation that can arise in covariate selection:
-
Confounding bias: a confounder is omitted from the analysis.
-
Mediator bias: a mediator is omitted even though a direct effect is of interest.
-
Spurious mediation bias: a mediator is included even though a total effect is of interest.
-
Collider bias: a collider is included.
It is noteworthy that biases stemming from the first two scenarios align with the concept of “omitted variable bias” in econometrics.42
5.2. Implications of causal inference
Covariate selection should not rely solely on statistical measures. Traditionally, covariates have been evaluated based on their “importance,” quantified by metrics like -values, amount of variance, or correlation with other variables. While it might be tempting to simplify and automate the decision process using a single measure, this approach essentially prioritizes statistical indicators over fundamental causal relationships, akin to allowing the “tail to wag the dog.” In essence, covariate selection should be rooted in the principles of causal inference.
Causal inference based on DAGs holds significant implications not just for model construction but also for experimental design. Using causal inference, the model can be established before any data are collected, and indeed can inform the data selection process. Traditionally, experimental design in neuroimaging encompasses aspects like jittering, randomization, inter-trial intervals, and trial and participant sample sizes. As shown in the motivating example, employing causal thinking through DAGs brings to the forefront potentially involved covariates simultaneously. Furthermore, taking this proactive step before data collection would prevent situations where data for crucial observable variables (e.g., confounders) are not collected, while avoiding the unnecessary allocation of resources to covariates that may not be needed (e.g., colliders).
Causal inference is also pivotal for result interpretation and reporting. The research question influences the role of each variable: a variable may be simultaneously a mediator, a collider or a confounder depending on the effect of interest, and it can play a different role in separate research questions using the same data. These considerations will dictate different analytical strategies, but again these will be established and guided by causal inference principles. In other words, each model centers on a specific relationship between an explanatory variable and the response variable. When a covariate becomes an explanatory variable, an alternative model might be necessary. For instance, the parameter estimate for a confounder may not be causally interpretable due to two primary reasons. First, the explanatory variable (e.g., height in Fig. 2A) acts as a mediator when the confounder (e.g., sex in Fig. 2A) becomes an explanatory variable. Second, when a confounder becomes an explanatory variable, its confounders may be absent in the current model. Consequently, the results obtained from one particular model might not always be inherently interpretable or meaningful; knowing this prevents a researcher from accidentally making claims that have no causal basis. Apart from the primary effect of interest, researchers might feel compelled to present all other parameter estimates along with the associated statistical evidence in a separate table. However, this practice is problematic and has led to the coining of the term “Table 2 Fallacy”.43–45
Causal relationships confer greater interpretive power than simple association analysis. While association analysis focuses on identifying relationships between variables, it does not establish causation nor provide a clear causal direction. Despite the adage “correlation does not imply causation,” association analysis can reveal interesting patterns for further investigation and serve as a precursor to causal inference. However, the lack of a principled approach for covariate selection in association analysis leads to arbitrary and inconsistent practices, undermining the rigor and interpretability of the results. In contrast, explicitly framing association analysis within the causal inference framework ensures that covariate selection is guided by causal principles, leading to a more rigorous and interpretable approach.46 Integrating causal inference principles into association analysis can enhance the overall quality of research by improving rigor and interpretation power, aligning with the idea that addressing causation-related concerns strengthens the research process.
The pivotal role of statistics in scientific investigations necessitates careful reflection. In practice, statistics significantly shapes crucial processes like model construction, result interpretation, and reporting. A delicate balance often emerges between the rigor of statistical models and the insights derived from domain expertise. However, the undue dominance of statistical models, often perceived as quantitative and objective gatekeepers, tends to diminish the importance of domain knowledge. Covariate selection serves as a pertinent example, where conventional practices prioritize a covariate’s accountability of data variability or its correlations with the explanatory and response variables. Similarly, strict thresholding in common practice allows modeling outcomes to unilaterally dictate reporting decisions. Consequently, a blind reliance on statistical evidence can inadvertently overshadow valuable contextual knowledge, leading to substantial biases.
Our demonstration here highlights the necessity for a statistical model to align closely with the underlying data-generating process. Validation of a model’s validity and the credibility of its results should not be independent but rooted in an understanding of the intricate web of causal relationships and underlying mechanisms. Contrary to a binary perspective of “statistical significance,” statistical evidence exists on a continuous spectrum, challenging the common practice of rendering modeling outcomes definitive based solely on arbitrary thresholds. A more informed approach involves considering the continuum of statistical evidence alongside domain-specific knowledge, which includes prior research findings and anatomical structures, to reach robust conclusions.
It is essential to recognize that domain knowledge and statistical models are not antagonistic forces but rather should be viewed as complementary components. Models should not be perceived as independent arbiters relying solely on raw data, where terms like “data-driven” might erroneously equate to reliability, even though data can inherently carry biases. Results generated by models should not be unquestionably accepted, especially when they contradict established prior information. Instead, there should be a collaborative synergy between domain knowledge and statistical models. Contextual insights ought to guide model selection and validate outcomes, while statistical models refine and update existing knowledge. Importantly, a DAG serves to clearly articulate model assumptions and specifications. Including DAGs in publications would significantly facilitate comparisons across studies, ignite intriguing discussions, and contribute broadly to advancing domain understanding.
5.3. Consequences of overlooking causal relationships
The importance of clearly stating the relationships among variables cannot be overstated. Without a causal understanding of the relevant variables, both the investigator and the reader may struggle to properly interpret the subtleties of a model, as well as possible discrepancies between models that use different covariates. The following issues are prevalent in common practice:
-
Lack of justification. Analysts are usually aware of the importance of conditioning on confounders. However, the awareness of categorization and distinctions among the various types of relationships among variables remains largely lacking. Due to conceptual confusions, covariates’ impacts are often simply treated as generically confounding effects without considering causal relationships. Variables like brain size, physiological fluctuations (e.g., breathing rate, heart rate), age, scanning sites, scanners, and software packages are lumped together and termed “confounding effects” without proper context and justifications. This oversight highlights a broader lack of awareness regarding the nuanced interplay among variables.
-
Using model indices as justifications. The term “causal salad” describes thoughtlessly including diverse covariates in a model without thorough consideration.15 This approach purports causal relationships to variables based on their inclusion and strong statistical evidence. Consequently, there is a prevalent tendency to interpret changes in estimates and statistical metrics (e.g., -value, information criteria) as indications of causation. For example, it is common to misinterpret the amount of variance explained by some variables as evidence of confounding or to use it to decide which covariates to include in a model.
-
Covariate mishandling. When variables of no interest are simply added as covariates, it is especially problematic when they act as mediators, collilders, or descendants of the explanatory variable. In the presence of a mediator, mediation analysis47 has been developed through a complex set of steps to parse various effect components. To avoid pitfalls, it is preferable to avoid conditioning on a mediator unless a clear justification for direct–instead of total–effect can be presented.
Many analysis malpractices fall into this bias estimation pitfall. When intuition is largely absent or obscured, misinterpretation due to the inclusion of mediators can easily occur. For instance, consider a study where different groups (e.g., children and adults) and conditions (e.g., congruent and incongruent) exhibit differences in reaction time. Similarly, covariates such as brain volume, head size, cortex surface area, thickness,36,37 weight, height, and body-mass index show differences between sexes. Consequently, simply adding these variables into a model, as commonly practiced, can lead to biased estimation. When not properly justified, the availability of various covariates in large datasets (like ABCD and UK Biobank) further exacerbates the likelihood and severity of this malpractice.
The potential pitfalls of mishandling mediators apply to both within-individual and between-individual covariates. It is generally easier to recognize the subtleties of a between-individual covariate acting as a mediator (e.g., head size in the context of the relationship between sex and BOLD response). However, similar nuances also come into play with within-individual covariates. Take the example of two conditions of easy and difficult tasks that are associated with short and long durations (or reaction times) at both the trial and condition levels. In this scenario, caution is warranted when dealing with duration (or reaction time) as a covariate. If the primary focus is on contrasting the two conditions (i.e., total effect), one should either omit the covariate from the model or employ appropriate centering strategies (e.g., within-condition centering) when incorporating the covariate. Adding the covariate in the model without proper centering would address a counterfactual and likely unintended question: What is the BOLD response difference when easy and difficult tasks have the same duration (or reaction time)? These subtleties substantially affect analyses at both the individual and population levels, even if they often go unnoticed in the field.
-
Result reporting. Parameter estimates from a model are frequently reported without adequate justification. In a model involving more than one explanatory variable, it is possible to simultaneously derive estimation for all parameters. Consequently, various estimates are often reported from a single model that encompasses multiple covariates. As illustrated here, each effect of interest is associated with a specific model, whose design considerations are tailored to the specific pair of explanatory and response variables, potentially making the estimation for another parameter estimated from the same model unsuitable. In simpler terms, different effects may necessitate distinct models.
-
Artificial dichotomization. In data analysis, a pervasive practice involves subjecting results to stringent thresholding. This artificial dichotomization introduces a substantial reproducibility challenge. The widespread insistence on strict thresholding in result reporting within neuroimaging stems from concerns about multiple testing. Paradoxically, this dichotomization approach shares a common bias issue with the well-acknowledged problems associated with “double dipping”. That is, dichotomization contributes to a reproducibility crisis, leading to distorted meta-analyses influenced by publication bias. Discarding sub-threshold voxels before meta-analysis is akin to excluding low-significance individuals before conducting group analysis–a practice that can be likened to estimating an iceberg based solely on its tip. While researchers are typically wary of the latter practice due to its potential to skew results, the same caution should be exercised in the former case.
The issue of reproducibility is poignantly illustrated by looking at the NARPS project. About 70 teams analyzed the same dataset, and when strict thresholding was applied before comparisons, conclusions were judged to be inconsistent across a large fraction of teams.48 Even though this conclusion of inconsistency has been most widely cited and broadcast in literature and social media, we can recognize that thresholding actually plays the role of filtering, and conditioning on stringent thresholding produces a strong selection bias, strongly distorting interpretation. In fact, without inserting dichotomization, the very same results were evaluated as being predominantly consistent.35,48 Moreover, instead of solely reporting statistical values through artificial dichotomization, greater information can be conveyed by emphasizing the quantification of effect magnitude and its associated uncertainty, as demonstrated in the toy example here (Fig. 1).
Some may contend that biases are an inevitable trade-off essential for effectively controlling false positives. However, this price is disproportionately inflated, primarily due to the oversight of anatomical hierarchies within the brain in the conventional mass univariate approach.34,49 Consequently, the overemphasis on controlling for false positives leads to excessively high false negatives. In addition, given that studies with results falling short of excessively stringent thresholding remain concealed from the literature, the level of bias can be insidiously high. Nevertheless, addressing this issue is possible by reporting effect estimates (e.g., percent signal change),50 and embracing a slightly modified approach — adopting a “highlight, don’t hide” strategy. This entails maintaining a certain level of rigor through soft thresholding while visually presenting the remaining data with some degradation.34,35 This nuanced approach not only acknowledges the need for evidence stringency but also mitigates the potential distortion introduced by hiding full results. Relying solely on single studies for certainty is rarely effective. Promoting information integrity and transparency, rather than black-and-white thinking through stringent gatekeeping, is key to fostering reproducibility.
Common practices in neuroimaging association analyses should be approached with caution from a causal inference perspective. Statistical modeling typically falls into two categories: prediction and causal inference. While they share some similarities, their goals are distinct. Prediction aims to forecast outcomes, focusing on minimizing error rather than uncovering underlying mechanisms. In contrast, causal inference seeks to identify cause-and-effect relationships. For instance, correlations are commonly used to capture synchronization between brain regions, and brain-wide association studies are a widely employed approach to identify correlations between brain features (such as MRI measures and cross-region correlations) and behavioral or clinical phenotypes. Though better suited for prediction, these methods are often adopted to find region-specific associations, but they face challenges due to the high dimensionality of neuroimaging data. In particular, they are highly vulnerable to confounding factors, and even large datasets (e.g., UK Biobank) can produce spurious associations without theory-driven guidance, leading to poor reproducibility or inaccurate associations. Since these methods are purely correlational, they cannot establish causality, which requires more rigorous designs, such as longitudinal studies or interventional approaches. These limitations have led to challenges in interpretation and issues with reproducibility in neuroimaging.
5.4. Suggestions
Causal inference demands a departure from conventional modeling methodologies. The adoption of DAGs proves invaluable in organizing existing knowledge and establishing a rationale for the inclusion of covariates. This approach encourages researchers to meticulously contemplate the interconnections among variables, visually articulate the reasoning behind their model selection, and contribute to the ethos of open science and research reproducibility. Here, we summarize our recommendations for the modeling process:
-
Clear research hypotheses. Explicitly define research questions and effects of interest. Identify explanatory and response variables for each effect, listing all relevant observable or latent variables. Consider potential constraints on data collection.
-
DAG presentation. Integrate DAGs into both experimental design and model construction. Apply causal thinking to experimental design to optimize data collection, avoiding unnecessary resource allocation. Include latent variables in DAGs for better interpretation and future guidance. Recognize that the absence of an arrow signifies a strong assumption of no meaningful causal relationship between variables.
-
Variable selection. Justify adopted models by presenting DAGs based on domain knowledge and theory. Follow principles of conditioning on confounders, avoiding conditioning on colliders. Exercise caution with mediators, explicitly choosing whether to investigate total or direct effects. Adopt conventional mediation analysis when comparing total and direct effects.51 Only condition on parents of the response variable among parent and child variables.
-
Modeling techniques. Construct models consistent with DAG representations for each effect. Properly center quantitative variables, especially when estimating total effects in the presence of a mediator. Consider interactions and nonlinearity52 when relevant.
-
Result interpretability. Not all parameter estimates from a model are causally interpretable. Acknowledge that a single model might be insufficient for a given dataset. Guard against the “Table 2 Fallacy” by reporting only results suitable for the model.
-
Transparent reporting. Enhance meta-analysis accuracy and reproducibility by avoiding strict thresholding. Report results containing both estimate magnitude and uncertainty.
5.5. Limitations
In typical data analysis, the intricacies of the actual data-generating process often elude complete understanding. Consequently, this process must be inferred through contextual knowledge, relevant theory, and plausible assumptions. The accuracy and precision of effect estimation hinge on the alignment of the proposed DAG with the true data-generating process. Creating and sharing a DAG serves to make underlying assumptions explicit, opening them to public scrutiny. While DAG assumptions may vary in active research domains, a consensus on key features may evolve over time. However, several limitations are associated with DAG representations:
-
Dependence on domain knowledge. Research domains such as neuroimaging are inherently complex, involving numerous covariates and intricate influence patterns. A DAG serves as an abstracted representation at the research focus level, relying on the quality of prior information for its creation. The accuracy of the DAG is paramount for a causal interpretation, and while a model derived from the DAG does not guarantee precise estimation of a causal effect, it explicitly represents existing knowledge and underlying assumptions. Incorporating prior knowledge into the modeling process with a DAG helps mitigate biases, facilitating the attainment of reasonably accurate estimates with adequate precision.
-
Qualitative nature. DAGs solely represent hypothesized causal relationships between variables, remaining qualitative in nature. While they aid in conceptualizing interrelationships, they do not specify how these relationships should be parameterized. The specific functional forms (linear or nonlinear), the presence or absence of interactions, and distribution assumptions must be informed by additional sources of knowledge.
-
Difficulty in estimating direct effects. Estimating direct effects becomes challenging when a confounder between a mediator and the response variable is influenced by the explanatory variable. In such cases, alternative approaches must be adopted.53 Conversely, when a confounder between the mediator and the response variable is latent, the estimation for the direct effect becomes biased.15 This complexity underscores the need for careful consideration in estimating direct effects.
Causal inference has flourished as a field for several decades. While our discussion here focuses primarily on covariate selection and result reporting, numerous other methodologies have emerged in recent years. For example, causal discovery aims to use statistical algorithms to infer associations in observed data that are potentially causal,54,55 while local causal discovery focuses on finding causal relationships for a specific target variable, rather than learning the entire causal structure.56,57 Other advanced methods include instrumental variable analysis, inverse probability weighting, matching, and more.58,59 Readers interested in these advanced topics can explore the relevant literature for comprehensive coverage.
6. Conclusions
DAGs emerge as potent tools for intuitively and efficiently communicate complex relationships in data analysis. Through a toy example, we offer a primary introduction to DAGs. Recognizing the pivotal role of categorizing covariates in variable selection, we argue that a firm grasp of causal inference profoundly influences the critical stages of statistical modeling: designing experiments, constructing models based on these relationships, interpreting results, and reporting outcomes. Causal thinking aids researchers in designing experiments more efficiently, discerning underlying assumptions, and formulating theoretical hypotheses, thereby fostering analytical rigor and reproducibility. From the perspective of causal inference, the current practice of emphasizing stringent thresholding in neuroimaging is particularly problematic, as it undermines open science and transparency. Improving reproducibility in the field requires maintaining information continuity.
Code and Data Availability Statement
All data and code used in this study are publicly available on GitHub at the following repository: https://github.com/afni/apaper_DAG1. This repository includes the scripts, data processing pipelines, and relevant datasets to reproduce the analyses presented in the paper.
Acknowledgments
The research and writing of the article were supported by the NIMH Intramural Research Program (GC and PAT, ZICMH002888), USA, and Fonds de recherche du Québec – Santé Postdoctoral Fellowship (ZC).
Conflicts of Interest
The authors declare that they have no competing interests.
For the sake of intuitive and concise presentation, we adopt the Wilkinson notation for model formulas,11 which is also widely used in R. Specifically, the compact notation indicates that both the main effects of and and their interaction are present in the model, i.e.:
The interaction between sex and height can be conceptualized within the framework of the conventional moderation analysis where sex acts as a moderator between height and weight. Alternatively, this interaction can be seen as an additional cause influencing the response variable in the DAG.30