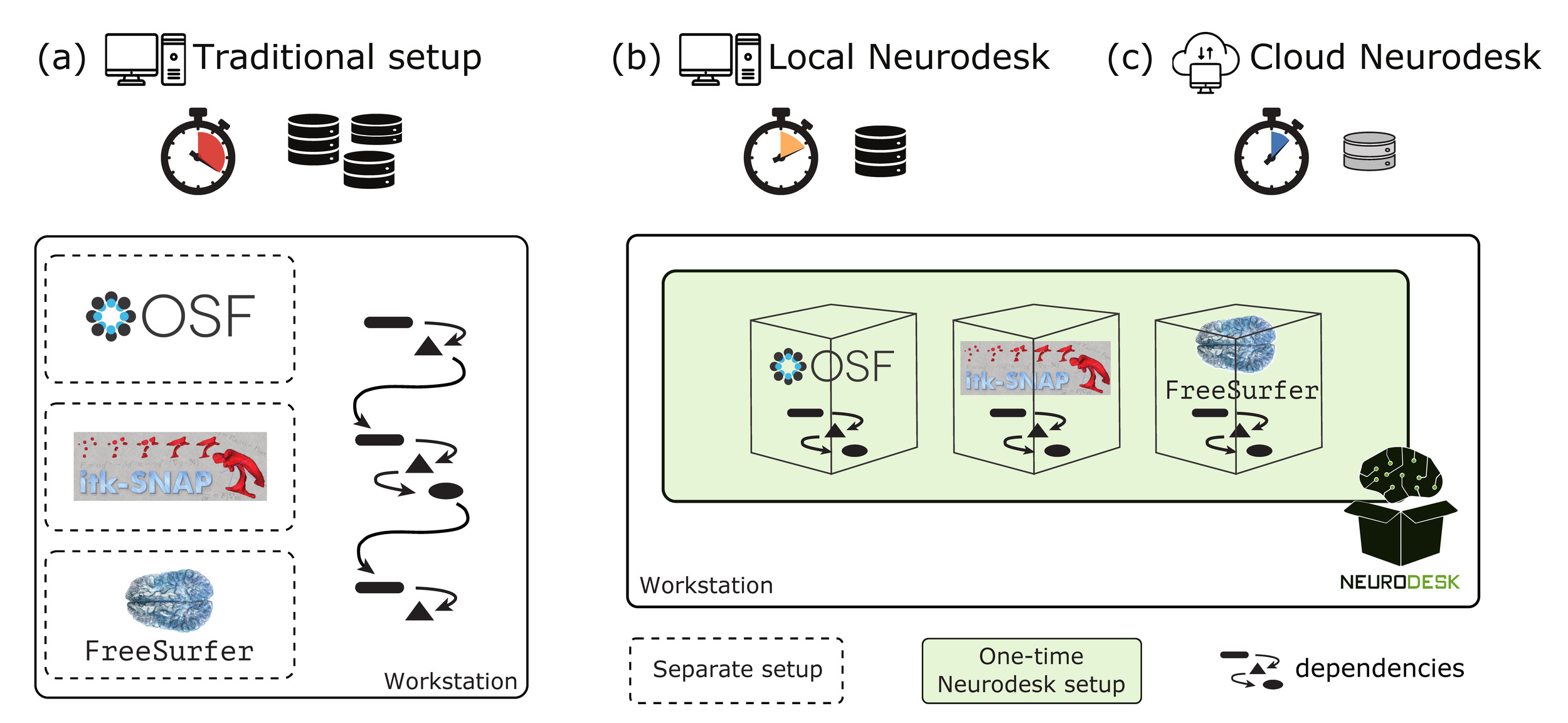
Introduction
Neuroimaging data are crucial for studying brain structure and function and their relationship to human behaviour,1–3 but acquiring high-quality data is costly and demands specialized expertise. To address these challenges and enable the pooling of datasets for larger and more comprehensive studies, two strategies have become common practice: (1) making smaller datasets openly available to the public through data repositories, like OpenNeuro4 and Open Science Framework (OSF)5; and (2) sharing data through large-scale consortium-led initiatives, such as the Human Connectome Project,6 the UKBiobank (UKBB) imaging,7 and the International Consortium for Brain Mapping (ICBM).8 Although it takes a great amount of effort to prepare these datasets, they enable the application of statistical models to derive biomarkers of neuropathologies with higher accuracy, reliability, and generalizability9–13 as they help control for confounding variables such as scanner type and preprocessing methods.
Beyond improving statistical model accuracy and generalizability, large neuroimaging datasets have also been used to create average templates, such as the MNI152 atlas,14–16 which serve as a common reference in many processing tools. Despite efforts made to include diverse ethnicities, genders, and age groups, these large-scale datasets often lack balanced demographic representation,14,15 leading to suboptimal performance for underrepresented populations.17 This highlights the potential of pooling smaller, more diverse datasets to complement large consortia efforts, ultimately making neuroimaging research more inclusive and equitable.
Accordingly, addressing demographic imbalances in neuroimaging studies requires greater international collaboration, but data sharing across borders comes with regulatory challenges. Many open data initiatives aim to protect personal information while enabling public access and compliance with diverse regulatory frameworks. These efforts typically involve removing personal identifiers and obtaining adequate consent from participants. Specifically, Open Brain Consent18 provides sample consent forms, template data user agreements tailored to specific regulations — such as the Health Insurance Portability and Accountability Act of 1996 (HIPAA) in the USA or the European General Data Protection Regulation (GDPR) in the EU — and recommended de-identification tools. Besides federal regulation compliance, there have been attempts to establish an international cross-border policy to govern data more efficiently to encourage more geographically diverse datasets.19 However, reaching a global consensus on principles that address legal, ethical, infrastructural, and financial issues requires significant effort and time. In the absence of such an agreement, researchers and their institutions are responsible for navigating these complexities, often limiting the scope and inclusivity of a shared dataset.
Moreover, publishing open datasets remains challenging in practice. To support the growing demand for data sharing, various repositories have emerged, each catering to different requirements. General-purpose repositories like OSF5 and Zenodo20 offer flexible storage solutions for public and private datasets without enforcing strict data formats. Meanwhile, neuroimaging-specific repositories — such as OpenNeuro,4 BrainLife,21 The Image and Data Archive,22 the Canadian Open Neuroscience Platform,23 and Neurobagel24 — incorporate confidentiality safeguards, including privacy policies and secure data governance techniques. These systems facilitate responsible data sharing, but each repository is designed with different priorities, such as security, flexibility, interoperability, or accessibility. As a result, researchers must navigate varying data preparation requirements and carefully evaluate which repository aligns with their research needs and complies with institutional or national regulations.
Finally, even when datasets are openly available and pooled for larger studies, ensuring reproducible results when using them remains a critical challenge. Differences in the processing steps can introduce unintended biases for downstream analyses.25 Such variability can compromise comparability across datasets and potentially undermine the benefits of data aggregation.
Altogether, these challenges complicate data sharing, hinder collaboration across research groups and raise compliance concerns with regulatory frameworks. To overcome these issues, Neurodesk25 was developed as an open-source community-driven platform that offers a containerized data analysis environment to facilitate reproducible analysis of neuroimaging data. Here, we discuss and demonstrate how Neurodesk addresses these issues. Through real-world data usage and sharing scenarios, we highlight its role in improving collaboration and reproducibility in neuroimaging research:
-
By supporting the entire open data lifecycle — from preprocessing to data wrangling to publishing — Neurodesk ensures interoperability with different open data repositories and standardized tools in compliance with widely adopted standards like the Brain Imaging Data Structure (BIDS).
-
By providing a flexible infrastructure that supports both centralized and decentralized collaboration models to enable more publicly available datasets.
-
By enabling researchers to run analysis pipelines on any computing environment, it ensures that researchers can access and analyze datasets in a reproducible manner.
The Neurodesk platform
Neurodesk - A scalable platform for data consumption and production
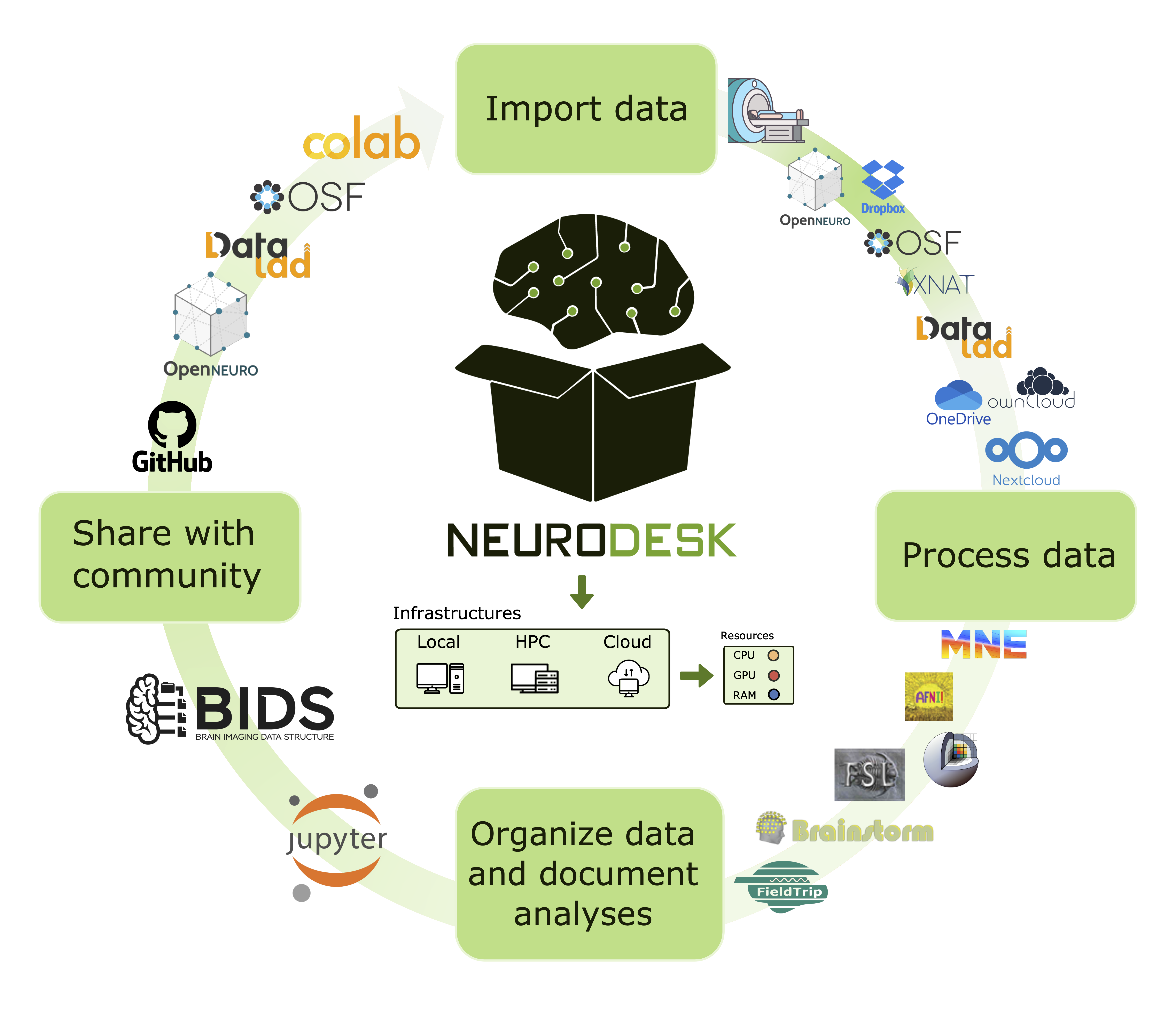
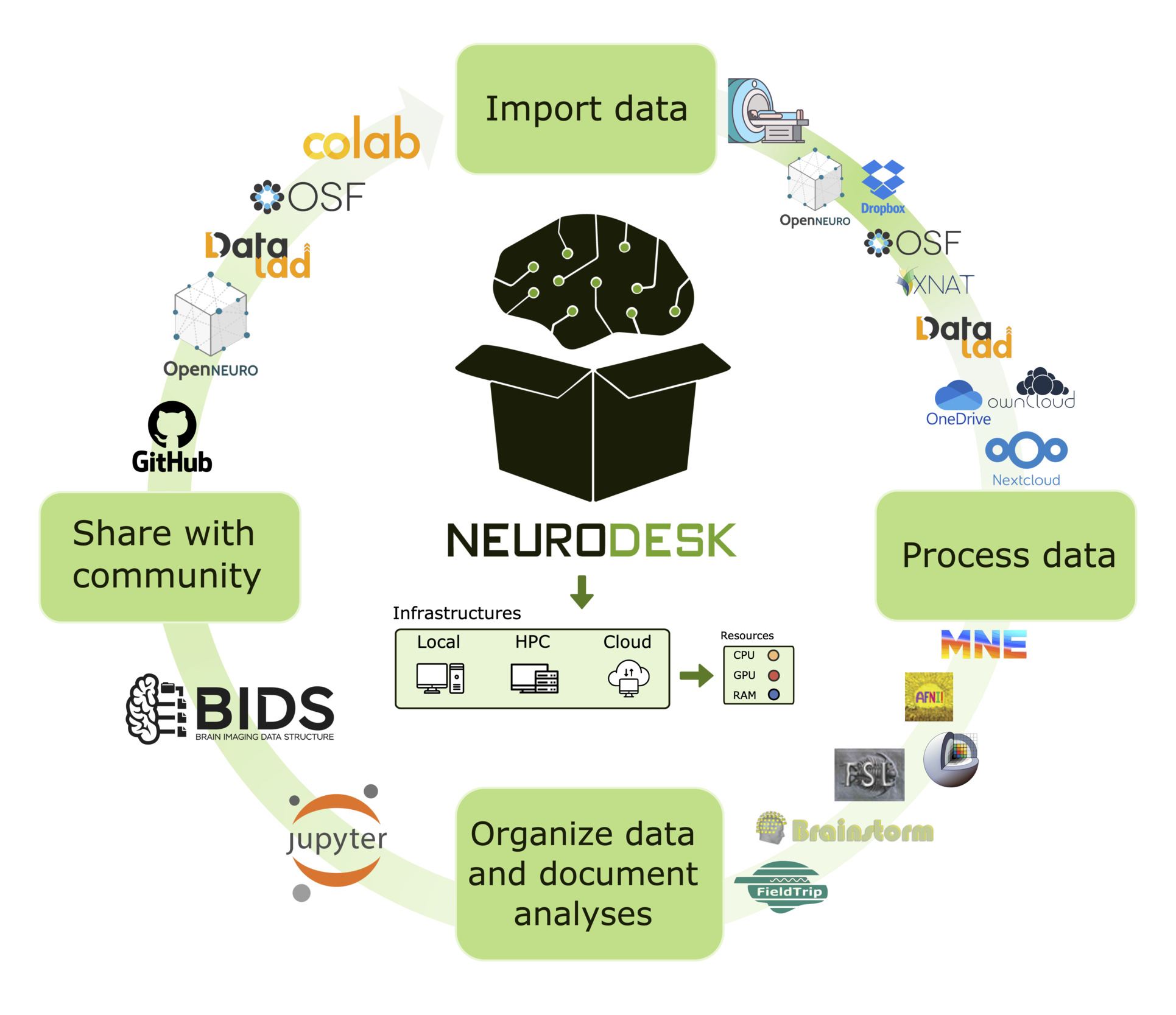
Neuroimaging workflows require integrating multiple tools that often lead to compatibility and resource constraints. Neurodesk25 addresses this challenge by providing a modular, lightweight, and scalable platform. Built on software containers, Neurodesk enables on-demand access to a comprehensive suite of neuroimaging tools, facilitating seamless processing, sharing, and access to datasets in an efficient and flexible environment (Figure 1).
To help with data preparation for open data repositories, Neurodesk brings tools to aid standardization, a critical step for facilitating collaboration across institutions. Neurodesk offers tools like dcm2niix,26 heudiconv,27 bidscoin,28 and sovabids29 to standardize data into the BIDS format30 to avoid manual organization, which is both time-consuming and error-prone. Once standardized, datasets can be seamlessly processed using BIDS-compatible tools such as QSMxT,31 BIDSApps,32 MRIQC,33 fMRIPrep,34 ASLprep35 and many more. These pipelines ensure researchers can process and analyze data consistently and adhere to best practices.
Beyond neuroimaging software, Neurodesk also provides a range of tools to interface with various data sources — such as scanners, cloud storage solutions, and open data repositories. This simplifies data retrieval, ensuring that researchers can access datasets with minimal technical overhead.
Finally, Neurodesk simplifies open data sharing by integrating DataLad,36 which enables data transfer to and from public repositories, like OSF5 or OpenNeuro.4 Additionally, Neurodesk supports various data transfer and cloud storage solutions, including Globus, OneDrive, Nextcloud, and ownCloud, allowing for secure and scalable collaboration across research institutions.
Data collaboration models to accommodate varied data privacy policies
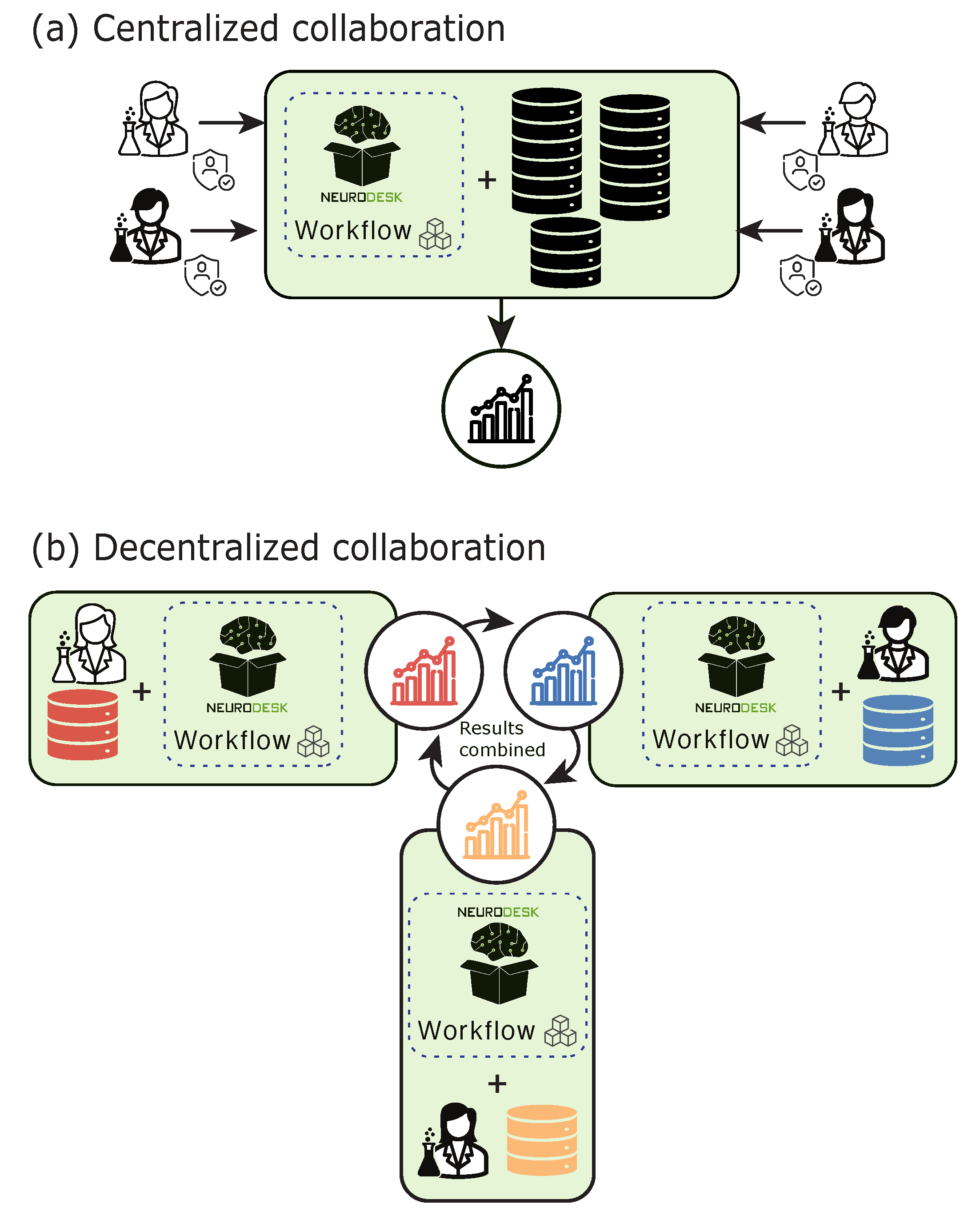
Neurodesk addresses the challenge of balancing openness and responsibility by supporting two models for data collaboration: centralized and decentralized (Figure 2). These collaboration models promote the use of open data and facilitate the legal and ethical sharing of processed derivatives to open repositories for large-scale, inclusive studies.
In the centralized collaboration model (Figure 2a), a Neurodesk-managed cloud instance allows collaborators to access a shared storage environment, avoiding the need for each user to download and manage datasets individually. Data can be centrally retrieved from sources such as open data repositories or institutional storage systems and made available to all authorized users. Customizable disk space can be attached to the instance, allowing teams to allocate resources based on project needs. By centralizing data and tools, Neurodesk streamlines workflows while enforcing access control through authentication. A shared instance reduces entry barriers for users with limited computational resources or technical expertise and supports multi-site projects by synchronizing workflows and data analysis.
In the decentralized model (Figure 2b), separate Neurodesk installations are maintained at each institution, allowing researchers to process sensitive local data without sharing it with collaborators. This approach complies with stricter privacy policies where their data governance does not allow data sharing outside of the institution. Neurodesk’s decentralized deployment allows institutions to maintain local control over sensitive datasets. Researchers can perform analyses on-premises, ensuring that sensitive data never leaves their institution’s secure environment. Appropriately de-identified data can then be shared among collaborators and aggregated. It enables the creation of geographically diverse datasets while ensuring ethical and regulatory compliance for robust and generalizable research.
_centralized_and_(b)_decentralized_collaboration_models_supported_by_neurodesk_offe.png)
Neurodesk’s infrastructure facilitates data and tool access from any computing environment and reproducible analysis
Neurodesk provides a containerized and modular computing environment that enables seamless access to neuroimaging tools and datasets across different computing platforms. Leveraging Docker37/Podman38 and Singularity39/Apptainer,40 it offers an all-in-one solution where each tool is packaged with its dependencies to ensure portability and reproducibility. This setup eliminates compatibility issues and ensures consistent, reproducible analysis of open datasets across personal computers, high-performance computing (HPC) clusters, and cloud systems. This versatility supports both small-scale and large-scale computation, enabling research teams to collaborate across different infrastructures.
Practical Applications of Neurodesk: From open data to scalable, privacy-aware workflows
To demonstrate how Neurodesk addresses key challenges in using open neuroimaging data — complex data processing workflows, cross-institutional collaboration, reproducibility, and accessibility — we present several example use cases demonstrating its impact on promoting the use and sharing of open datasets. These examples illustrate how researchers leverage Neurodesk to streamline complex data processing pipelines, collaborate securely across institutions, and scale reproducible analyses from local machines to HPC environments. Through these use cases, we highlight the platform’s ability to facilitate the use and sharing of open datasets, enabling transparent and collaborative neuroimaging research.
Use case 1: Processing behavioural and neuroimaging data
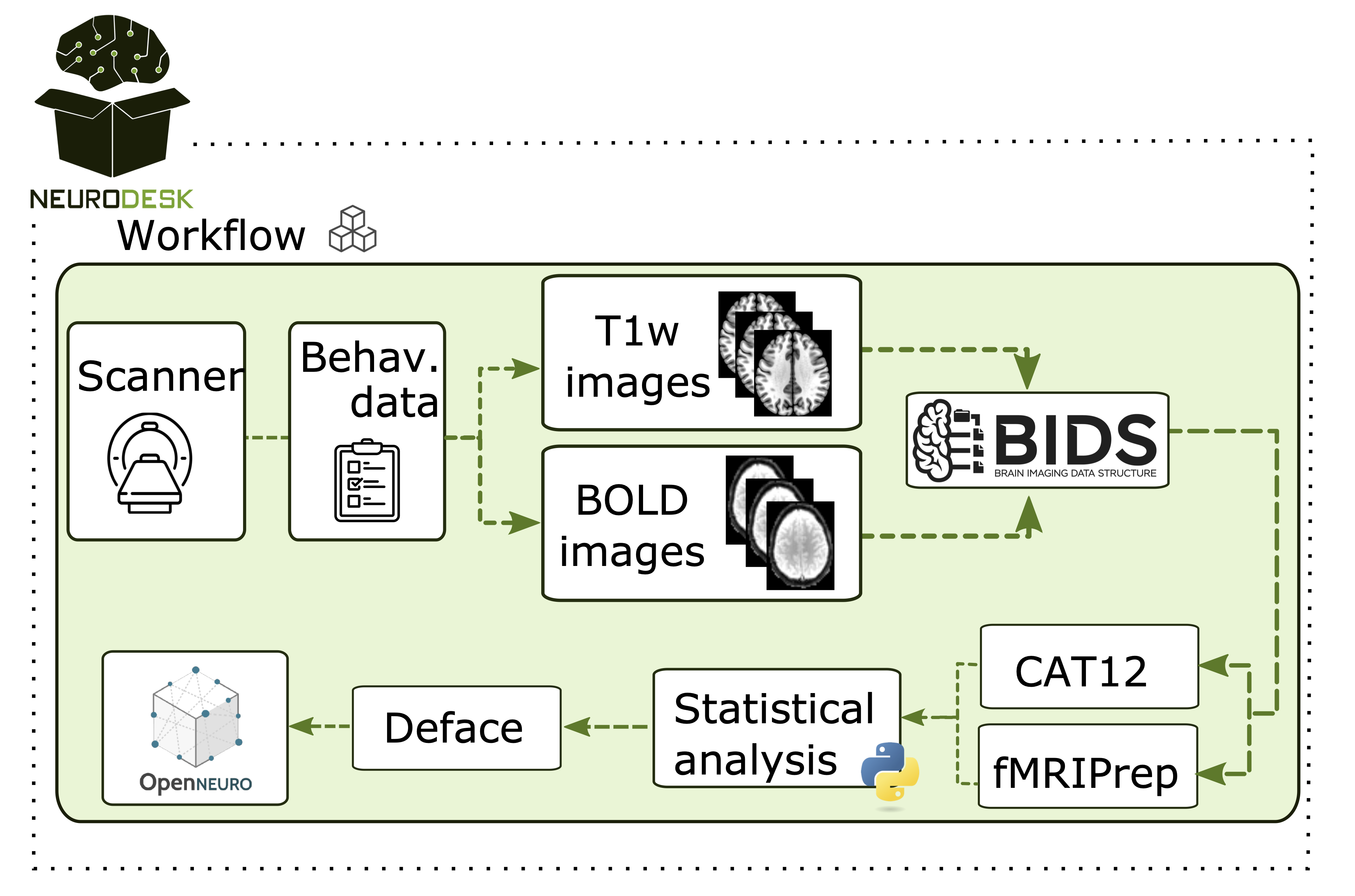
The first use case covers a study investigating relationships between brain structure, function, and behaviour, in which researchers collect behavioural and MRI data. In such studies, typically with smaller sample sizes, researchers handle all steps — from data acquisition at the MRI scanner to data storing, preprocessing, and analysis (Figure 3).
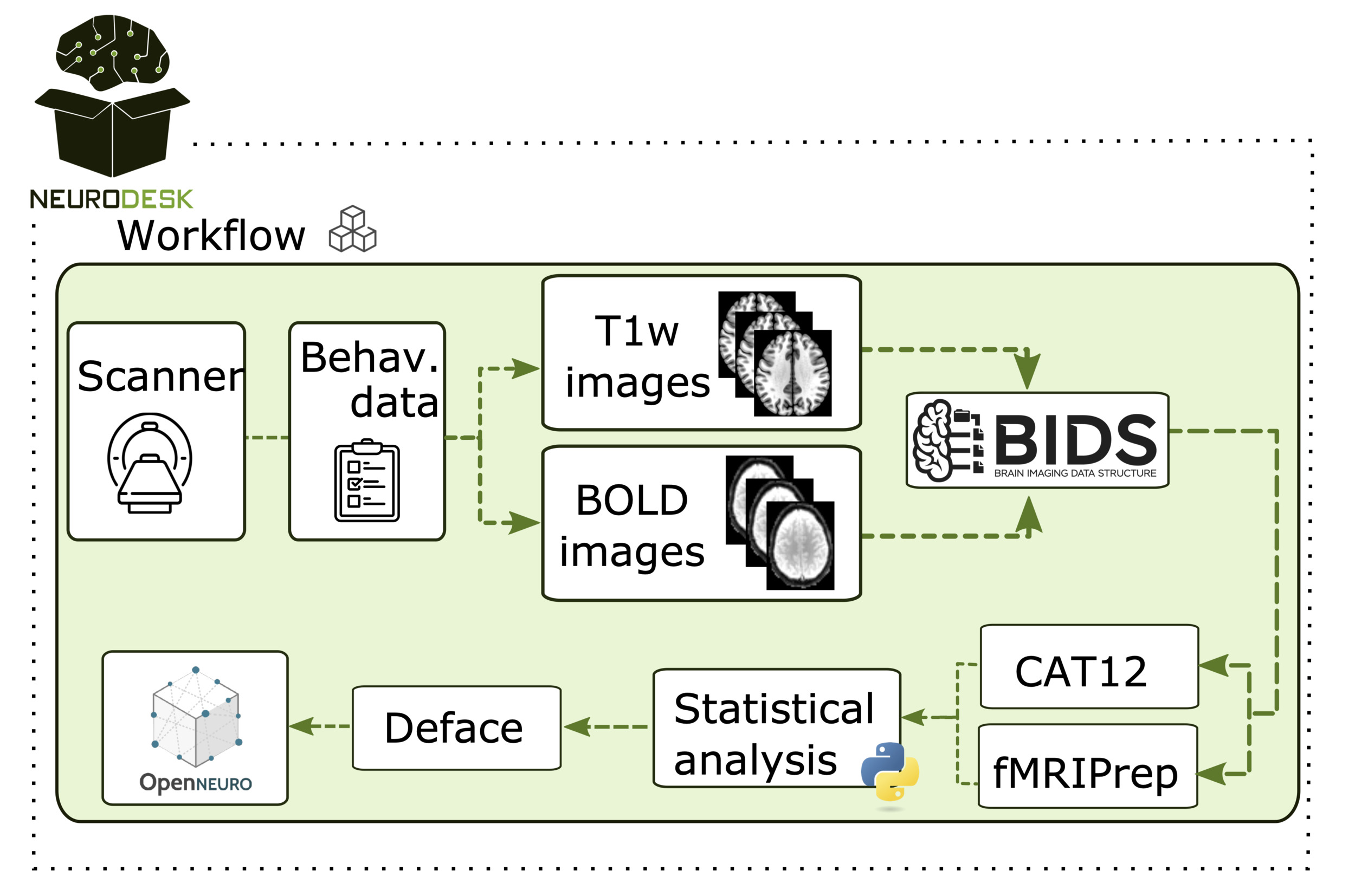
Neurodesk simplifies this process, providing a unified platform where essential neuroimaging tools are readily accessible. Researchers can perform preprocessing, visualization, and BIDS conversion without the burden of installing and configuring multiple tools. During data acquisition, researchers often perform quality checks before recruiting more participants. This involves converting raw DICOM data from the MRI scanner into other formats for visualization. Neurodesk streamlines this process by supporting data conversion tools, like dcm2niix,26 and visualization software, such as MRIcroGL.42 As datasets grow, standardizing data structures becomes increasingly important for efficient processing and sharing. Neurodesk supports this through tools that facilitate BIDS formatting and quality assurance. Additionally, Python-based statistical and correlational analyses can be easily performed within the same environment, enhancing workflow continuity. To support open data sharing, Neurodesk also facilitates data de-identification, such as defacing brain images, prior to sharing datasets with public repositories. By integrating tools across the entire workflow, Neurodesk enables researchers to prepare, analyze, and share open neuroimaging data in a streamlined and reproducible manner.
Use case 2: Open-science education
The second use case is an educational workshop introducing neuroimaging tools. Workshops often require participants to access and analyze shared neuroimaging datasets, but setting up the required tools and downloading such datasets on individual devices can be time-consuming and impractical.
Neurodesk addresses this by enabling a shared cloud instance where all participants can securely access pre-configured neuroimaging tools and datasets in a standardized environment (Figure 4c). This ensures a smooth and consistent experience for running the workshop without delays. Every workshop participant is securely authenticated and works within an identical environment, making it very easy for the workshop demonstrators to guide learners through the material. The cloud-based environment also lowers technical barriers, allowing participants to join from devices that would otherwise be unsuitable for neuroimaging software, including tablets. Workshop demonstrators can access learner sessions via an admin panel, providing real-time guidance and troubleshooting without requiring participants to configure software locally. Importantly, once the workshop is completed, the learners can install Neurodesk on their own computers or their institution’s infrastructure and continue to use the tools they learned about during the workshop (Figure 4b). By centralizing the data and tools, Neurodesk is an ideal platform for education and training in the neuroimaging community.
Use case 3: Processing of sensitive data for multi-site projects
The third use case addresses the challenge of privacy-compliant multi-institutional collaboration, where researchers from different institutes acquire data under similar scan protocols but need to analyze their datasets without sharing sensitive data due to HIPAA or GDPR restrictions. An additional challenge is to ensure that every collaborator runs exactly the same analysis with identical parameters so results can later be aggregated across sites, thereby increasing the generalizability of the methods.
To overcome this, Neurodesk enables a decentralized workflow, where researchers can run identical analyses on their machines while keeping sensitive datasets private (Figure 5). Instead of transferring identifiable or any kind of personal data — which may be legally restricted — collaborators can share only de-identified summary statistics and aggregate them in a meta-analysis. The ENIGMA consortium has exemplified that this approach allows for broader generalization of findings across different populations and sites without violating privacy regulations.
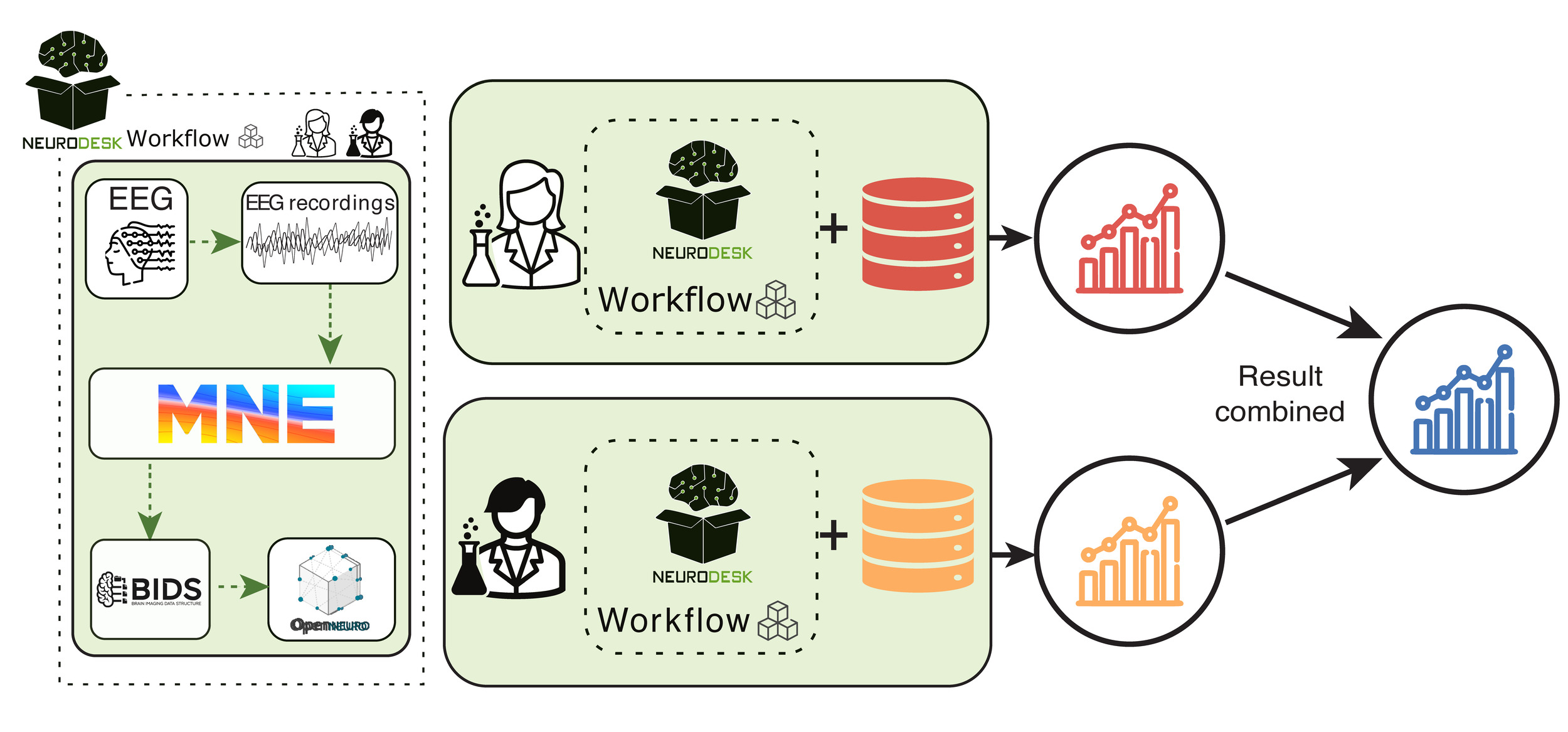
Without Neurodesk, ensuring consistency across institutions would be highly complex, as differences in software environments, dependencies, and computational setups could introduce variability in results.43 This variability can undermine the statistical power of the analysis, leading to potentially unreliable conclusions. By providing a standardized and privacy-aware framework, Neurodesk removes these barriers, allowing institutions to collaborate securely while upholding strict data governance policies and ensuring the reproducibility and statistical integrity of their analyses.
Use case 4: Scaling analysis from PCs to high-performance computing clusters
The fourth use case highlights the challenge of developing a neuroimaging deep learning model that requires extensive preprocessing and access to large datasets, which often cannot be easily transferred due to data scale. In such experiments, researchers often begin by prototyping on local sample data before transitioning to running full-scale analyses on HPC or cloud-based resources where the complete dataset resides (Figure 6). Migrating analysis pipelines across environments introduces software compatibility issues and dependency conflicts, which hinder reproducibility.
Neurodesk provides a portable platform enabling flexible data access — either an open data repository or private storage — across multiple infrastructures. Researchers can begin their work using Neurodesk Play, a browser-based environment requiring no installation, and later transition to running the same analysis pipeline on a local machine, an HPC cluster, or a hosted Jupyter Notebook service. By enabling flexible data access and portable processing across infrastructures, Neurodesk facilitates collaboration and ensures that neuroimaging workflows remain scalable and efficient.
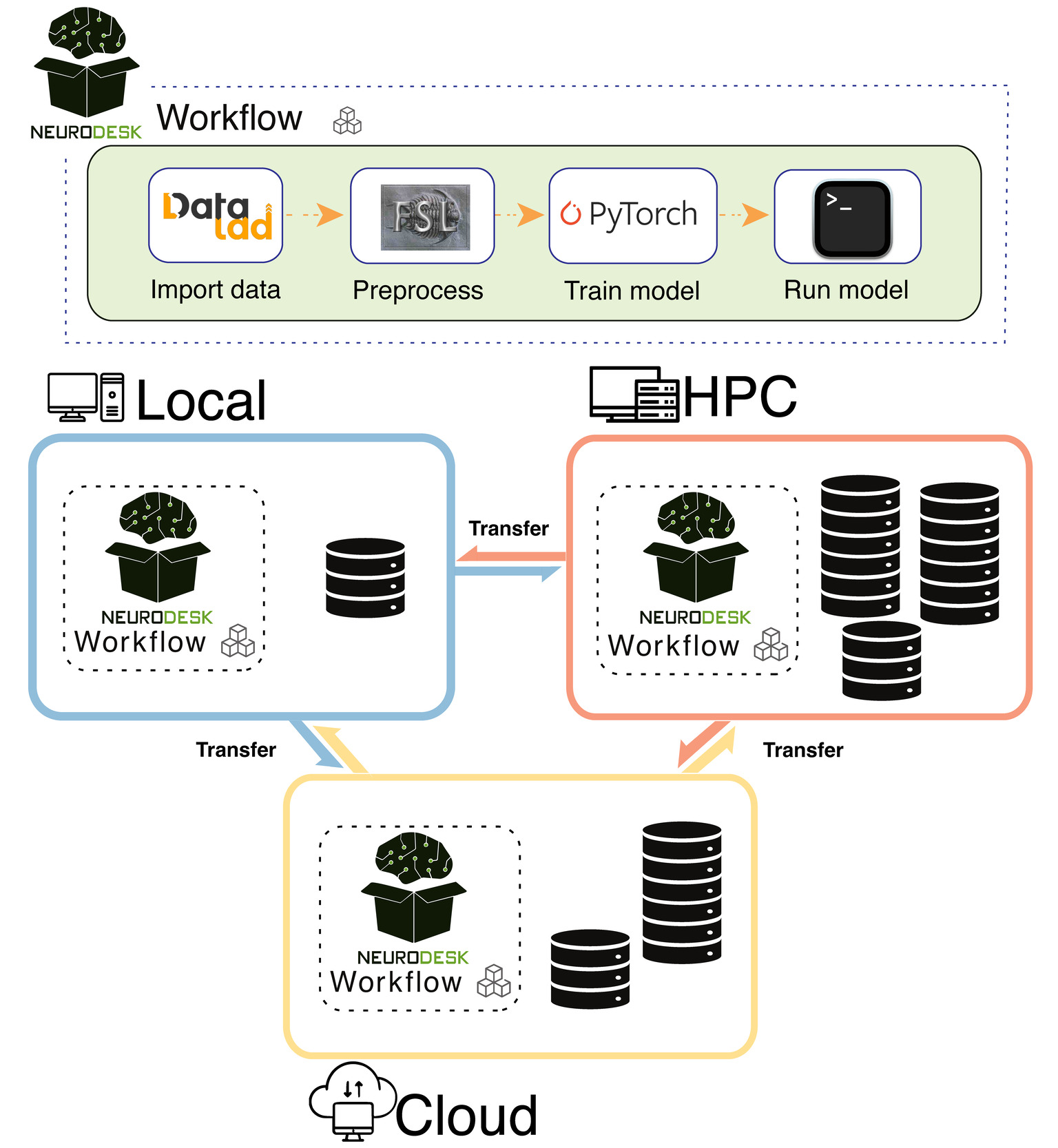
Discussion
Here, we showcased how Neurodesk provides a portable, flexible, accessible platform that enhances open neuroimaging data sharing and usage. We provided guided examples on how researchers can work with and collaborate on different data sources, whether using open datasets or processing data locally. These use cases show that Neurodesk empowers researchers to prepare and publish standardized, shareable outputs to public or private repositories. We summarize the key advantages of using Neurodesk for neuroimaging experiments as follows:
-
Standardized data processing: Neurodesk streamlines neuroimaging workflows by fully supporting BIDS-compliant data structuring and conversion tools, enabling researchers to organize datasets according to standardized community practices.
-
Secure and flexible data sharing: Neurodesk provides both centralized and decentralized data-sharing models, ensuring compliance with international data protection regulations. By facilitating responsible data sharing, Neurodesk supports the development of more robust and generalizable statistical models, advancing neuroimaging research.
-
Portable analysis: Neurodesk’s modular design ensures a consistent environment across platforms for seamless dataset access and reproducible analysis. This makes collaborative projects, hackathons, and workshops more efficient by providing consistent execution environments to all participants.
Neurodesk has had a significant impact on workshops, training programs, and research projects worldwide, particularly for researchers with limited resources or those with limited permissions on institutional workstations. By providing a portable, ready-to-use platform, Neurodesk lowers technical barriers, enabling more equitable access to advanced neuroimaging tools. In the rapidly evolving neuroimaging research field, Neurodesk stands out by swiftly integrating new tools and adapting to emerging research needs. Its commitment to open science and technological innovation makes it a crucial resource for the global neuroimaging community.
Beyond facilitating collaboration, Neurodesk is actively advancing its development to address the challenges associated with data security and regulatory compliance in neuroimaging research. Recognizing the need for faster translation of research pipelines to clinical questions, Neurodesk is expanding its toolset to be accessible directly on imaging scanners. This is currently already possible on Siemens scanners through the Open Recon framework.44 By leveraging Open Recon, a platform that allows image processing containers to run directly on the scanner, Neurodesk containers can be run on the scanner and fully integrate scientific processing workflows into clinical workflows. This innovative approach allows researchers to execute the entire workflow — from data collection to processing — on the scanner itself, ensuring that sensitive data never leaves the secure environment. As Neurodesk continues to evolve, these efforts exemplify its commitment to creating a seamless platform for open collaboration, ultimately enabling clinical translation.
Data and Code Availability
Open-source code for the development of Neurodesk infrastructure is available on GitHub (https://github.com/neurodesk).
Funding Sources
The authors acknowledge funding through an ARC Linkage grant (LP200301393). This research was supported by the use of the ARDC Nectar Research Cloud, a collaborative Australian research platform supported by the NCRIS-funded Australian Research Data Commons (ARDC), the EGI Federation with support from CESNET-MCC and Indiana University’s Jetstream2 Cloud. This work is supported by the Wellcome Trust with a Discretionary Award as part of the Chan Zuckerberg Initiative (CZI), The Kavli Foundation, and Wellcome’s Essential Open Source Software for Science (Cycle 6) Program (Grant Ref: [313306/Z/24/Z]). FLR acknowledges support through the European Union’s Horizon Europe research and innovation funding program under the Marie Skłodowska-Curie Actions project ID 101146996.
Conflicts of Interest
The authors have no competing interests to declare that are relevant to the content of this article.