Introduction
Magnetic resonance imaging (MRI) is an indispensable tool in medical diagnostics, offering detailed images of the human brain’s internal structures. However, the acquisition of high-quality MR images is often constrained by the trade-off between scan time and image resolution. High-resolution imaging in particular requires large k-space acquisition matrices, which in turn depend on the collection of vast data.
Parallel Imaging (PI) techniques like generalised autocalibrating partially parallel acquisitions (GRAPPA)1 and sensitivity encoding (SENSE)2 are routinely used in multichannel receive coil setups to decrease scan time by undersampling k-space acquisition. Promising reconstruction techniques have been demonstrated relying on low-rank matrix completion, like low-rank matrix modelling of local k-space neighbourhoods (LORAKS).3 LORAKS exploits the low-rank properties of specific operator matrices built from small neighbourhoods around each k-space point to facilitate reconstruction. The neighbourhoods can be extended by combining available channels to reconstruct multichannel data.4
Many MRI acquisitions depend on sequence variations to produce different contrasts, such as multi-echo temporal signal weighting5–8 or diffusion gradient weighting.9,10 Algorithms to handle reconstruction jointly across contrasts have already been demonstrated.11,12 In particular, joint-echo reconstruction using a Joint-LORAKS (J-LORAKS) framework has been shown to outperform GRAPPA-based variants in image reconstruction quality.13
Despite its effectiveness and improvements to the original algorithm,14 such as AC-LORAKS using an autocalibration (AC) region to speed up computations,15 the computational demands of J-LORAKS pose significant challenges. Commonly, a singular value decomposition (SVD) operation is used to enforce low-rank structure. SVD scales quadratically in time and linearly in memory computation complexity.16,17
The structured matrices used in LORAKS scale linearly with the number of receive channels and contrasts (in modern scan settings: receive channels, contrasts), hindering reconstruction optimisation by high computational time and restricting high-resolution reconstruction by infeasible memory requirements. For example, we carried out the joint-reconstruction of an MRI scan with an acquisition matrix of in plane, 100 slices, 32 receive channels, and three echoes on a modern compute server with the recent LORAKS software implementation.18 The time consumed is > 3 d to process the whole dataset, while the requirement on the available system memory (RAM) is around 170 GB. Similarly, in comparison to other reconstruction techniques, LORAKS required the longer reconstruction times, without even including its computationally extensive phase constraint formalism or joint-reconstruction capabilities.19
Another challenge of LORAKS is the choice of the algorithm parameters (regularisation weighting and rank which are not known a priori and require careful balancing. Influence of the rank parameter is commonly gained empirically by visual data assessment after reconstruction.14,20,21 Especially for J-LORAKS, inherent high computational cost and slow computation speed hinder brute force methods or manual user selection. Automation of the parameter choices has been proposed using Stein’s unbiased risk estimator (SURE),22 in conjunction with coil sensitivity map estimation for a SENSE-based PI reconstruction.23 Similarly, the LORAKS rank parameter has been subjected to SURE optimisation using compressed-sensing, total variation, and wavelet regularisation,24 which further increases the computational needs upon reconstruction, with the time feasibility depending on the J-LORAKS reconstruction performance.
Multiple reconstruction frameworks and LORAKS extensions have been suggested to address its poor scaling and computational performance, utilising specific optimisation formulations or additional constraints.
A fast convolutional procedure (HICU) tailored to low-rank matrix completion introduced computational optimisations regarding gradient computation and precise step size estimation in its iterative solving.25 Furthermore, randomised SVD (rSVD) was used to approximate low-rank deficiency,25 offering improved stability and parallel computing.26
Despite speedup and memory reduction, HICU only extends the LORAKS compact support constraint, not using the additional phase-constraint, which was found to be superior in a number of applications.27 Nevertheless, substituting the core matrix-decomposition with rSVD proves beneficial,17,28 and recent variants like subspace-orbit rSVD16 or randomised nullspace approximation (RAND-NS)29 may yield further efficiency gains for large matrices encountered in J-LORAKS.
Efficient parallelised computations, specifically accessing GPUs, were used in a plethora of variations either replacing or mimicking the regularisation term through deep-learning algorithms.30–32 In this context the iterative and convolutional nature of LORAKS operators, AC-LORAKS in particular, allows viewing LORAKS itself as an autoregressive network. Thus, AC-LORAKS was implemented as a network building block in an autoregressive ensemble approach for k-space interpolation.33 Although implemented in PyTorch,34 graphics processing unit (GPU)-specific details were not provided, computation times were not reported, and the achieved fidelity comes at the expense of computational overhead by adding multiple other ensemble blocks.
LORAKI replaced the explicit computationally demanding low-rank enforcement by a parametric recurring neural network (RNN).35 The LORAKS prior thus is encoded in the RNN weights rather than using an explicit mathematical formulation. Furthermore, the RNN needs to be trained, which was reported with runtimes of 1 h for rather small slice dimensions and channels.35 Usually, for inference, the computation time of the trained model is much faster and the process might be subject to similar optimisations shown for the original RAKI implementation,36 but to the authors’ knowledge, no such implementation was made available at the time of this study.
Our implementation uses PyTorch for parallel execution on GPUs, previously used to accelerate MRI reconstruction.37–39 PyTorch’s automatic differentiation engine40 enables efficient gradient computation through the entire reconstruction pipeline. It allows treating the LORAKS reconstruction itself as a differentiable computational graph. Such a traceable LORAKS constraint can be combined with other regularisation terms,41 or as a building block for physics-informed deep learning42,43 or generative AI models44 and allows novel optimisation approaches.
However, in our implementation, we intended to keep the inherent mathematical rigour of the low-rank mechanism building a learning-free framework, as the black-box character of deep-learning methods poses challenges in interpretability and evaluation of the models.45
In this paper, we present an enhanced LORAKS implementation designed to overcome computational limitations, enabling efficient joint-reconstruction of undersampled, multichannel, multi-contrast MRI images. We develop PyLORAKS, a Python-based LORAKS algorithm using PyTorch, enabling GPU utilisation. Further, we changed the operator construction in order to enable efficient linear memory access, and ensured PyLORAKS reconstruction similarity to, and benchmarked against the latest publicly available LORAKS MATLAB46 version.18
To extend the LORAKS mechanism, we incorporated and tested recent rSVD methods and introduced an automatic backpropagation feature. Additionally, we introduce batching strategies for efficient leveraging of multichannel, multi-contrast data redundancy to enable joint-reconstruction of high-resolution data with feasible time and computational constraints.
Furthermore, we demonstrate a number of exemplary implications of our framework for MRI research. For a specific 2D multi-echo acquisition, we evaluate the choices of LORAKS parameters and on joint-reconstruction to optimise the reconstruction and provide general recommendations for the parameter settings in PyLORAKS. Additionally, we demonstrate the ability for acquisition optimisation using our framework by computing an optimised sampling scheme and showing increased reconstruction quality, which is transferable to reduced scan time in high-resolution MRI acquisitions.
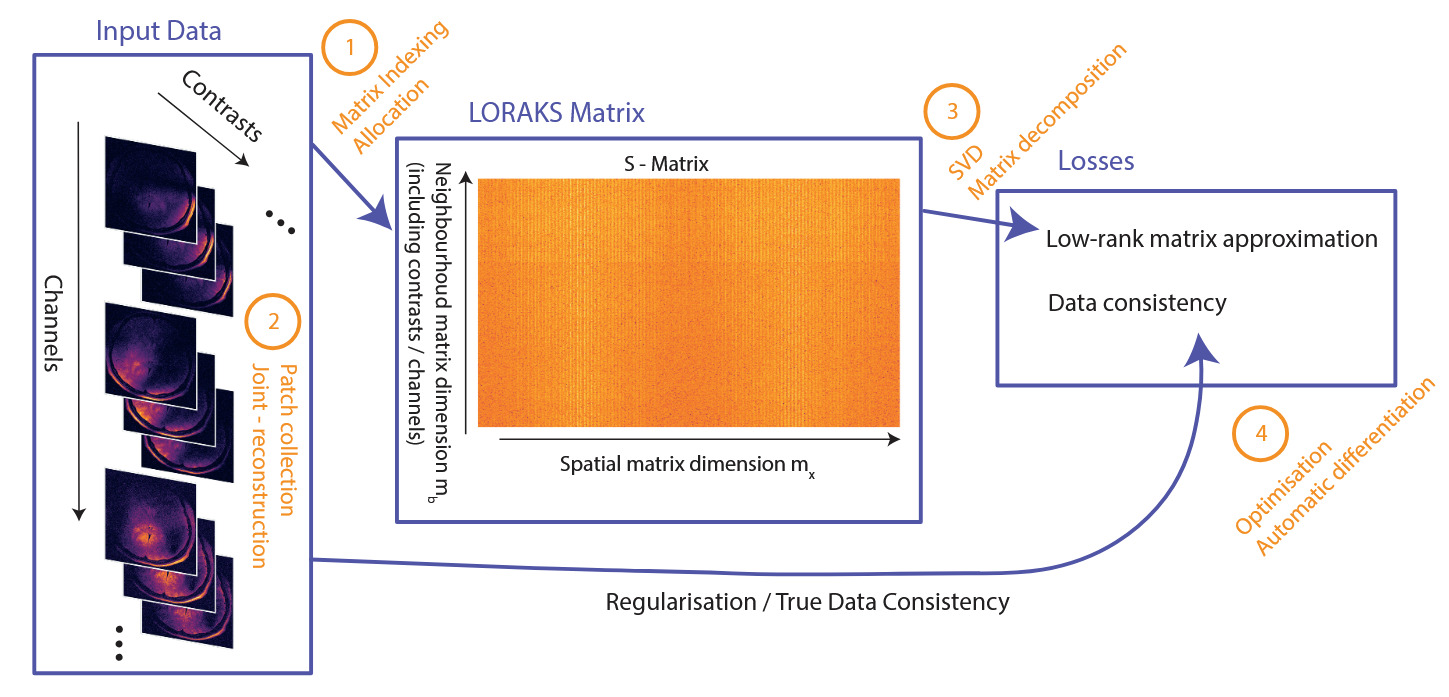
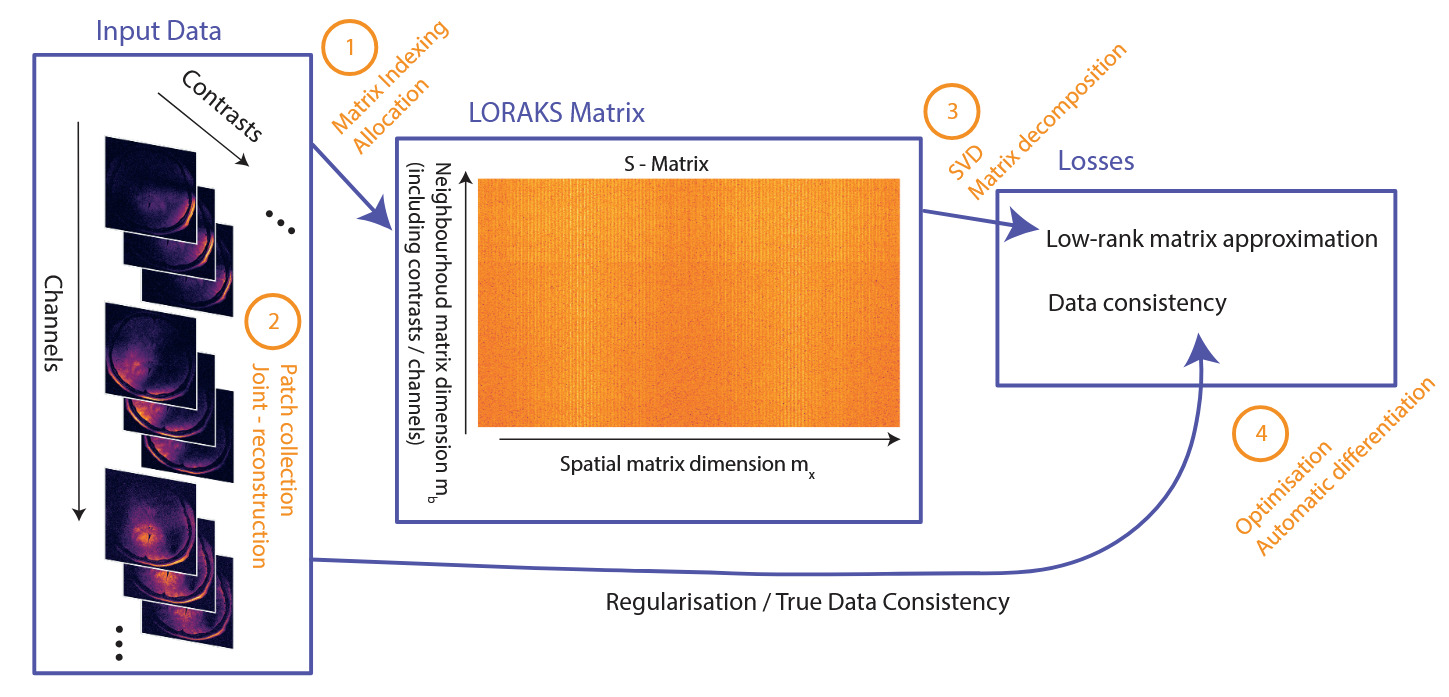
The steps involved in LORAKS reconstruction, together with modifications and additional features presented in this study, are sketched in Figure 1 for reference.
Materials & Methods
LORAKS can be regarded as a two-fold process: (1) building the LORAKS neighbourhood matrix (from k-space data and (2) optimising a loss function to drive a low-rank matrix constraint and ensure data fidelity. The reconstruction of the 5D k-space data consisting of three spatial dimensions multichannel and multi-contrast data with missing and zero-filled entries, becomes the following minimisation problem3:
\[ \boldsymbol{\hat{k}} = \min_{\boldsymbol{k} \in \mathbb{C}^{R}} ||{\boldsymbol{F}\boldsymbol{k} - \boldsymbol{d}}||_{2}^2 + \lambda J_r(\boldsymbol{P}(\boldsymbol{k}))\tag{1}\]
Here, is the sampling operator, which neglects missing entries and is the actual acquired k-space samples. is a nonconvex regularisation penalty that enforces rank on its argument. is the LORAKS matrix operator, which constructs the LORAKS matrix from the k-space input by collecting neighbourhood patches around each spatial position in LORAKS employs distinct types of neighbourhood matrix operators which impose different restrictions on k-space. For example, the C-operator requires limited support, and the S-operator imposes a smooth phase. We restrict the study to LORAKS reconstruction using the S-operator, since empirical findings suggest superior results across a range of applications.27 However, all methods can be applied to the C-operator as well.3 Without loss of generality, assuming to be 2D slices of k-space data, we denote the matrix dimensions where the factor of two arises from the S-operator’s conjugate-symmetry construction.
The spatial dimension includes all patches fully contained within the slice, where are the slice dimensions. The neighbourhood dimension depends on the square neighbourhood patch of size For the multichannel formulation, the channels are concatenated along this dimension, as are the contrasts for a joint-reconstruction setup.13 Thus where are the numbers of channels and contrasts, respectively. In a typical clinical setting is around or and can be as high as depending on the acquisition method. Thus, with a multi-echo acquisition of echoes and 32 receive channels We set for convenience throughout this manuscript. The matrix can be seen in Figure 1, outlining the steps of the approach.
Several methods have been proposed in conjunction with least-square solvers3 to find solutions to the minimisation problem in equation 1. Further computational improvements were made using the approximation15
\[ J_r(\boldsymbol{P}(\boldsymbol{k})) \sim\|\boldsymbol{P}(\boldsymbol{k}) \boldsymbol{V}\|_F^2, \tag{2}\]
that uses the Frobenius norm for an appropriate choice of the matrix When the subsampled k-space contains autocalibration (AC) data, can be extracted from the nullspace of the LORAKS matrix built from the AC region 15 The properties of the LORAKS matrix and the convolutional structure ingrained in the matrix norm in equation 2 allow for further computational gains by fast fourier transforms (FFT) to find the solution.14
We restrict this study to the fast AC-LORAKS reconstruction method, focusing on its practical applicability rather than providing an exhaustive comparison. The assumption of available AC data is well justified, since it underlies the majority of parallel imaging strategies, including widely used approaches such as SENSE2 and GRAPPA,1 for which a number of autocalibration methods like FLEET47,48 exist. However, original loss-solving methods, LORAKS matrix operators (C and S - matrix) and calibrationless P-LORAKS have been included in PyLORAKS. Our motivation for PyLORAKS was its use for sampling optimisation and sequence development in our research, requiring low computation time to enable fast development cycles. Similar results can be achieved using PyLORAKS with other algorithmic variations as the improvements presented are not specific to the particular algorithmic choice.
Data & Hardware
For evaluation of the algorithm and its features, we used different virtual data and in vivo MRI high-resolution data scans.
Virtual data
Random matrices
To simulate different S-matrix sizes in our experiments testing randomised matrix decomposition methods, we used torch.randn() to create random matrices We set as representative spatial LORAKS S-matrix axis for an image slice. The LORAKS neighbourhood dimension (representing concatenated channels and/or contrast) was varied from using 20 equally spaced values.
Shepp-Logan
For memory and speed benchmarks of the PyLORAKS framework, we used a Shepp-Logan virtual data phantom49 to simulate one slice of imaging data.
To vary the neighbourhood dimension of the LORAKS matrix, we simulated different receive channel coil-sensitivities by placing 2D Gaussian windows at random points within the imaging slice with a standard deviation of where is the respective image dimension. The number of receive channels was set to be
Additionally, we assigned randomised decay rates to the different intensity classes in the Shepp-Logan phantom to generate a Shepp-Logan decay rate map which was used to simulate additional relaxation contrasts. Thus, decay images were created multiplying the phantom by the factor varying
Random Gaussian noise was added to the k-space data of each contrast and channel, respectively, using the torch.randn() function setting torch.manual_seed(0).
The neighbourhood patch size was chosen to be in PyLORAKS and a radius of in Matlab for an equal number of patch elements. For the neighbourhood dimension defined by we get with varying and The spatial dimension of the LORAKS matrix was varied with from to increasing by at each step, and, therefore,
MRI data
For data-driven optimisations regarding the joint-reconstruction data combination and parameter and sampling optimisations, we used high-resolution in vivo data.
Acquisition
All data were acquired on a Magnetom Terra 7 T MRI scanner (Siemens Healthineers, Erlangen, Germany). We used an 8Tx/32Rx channel phased array RF head coil (Nova Medical, Wilmington, MA, USA). Note that the number of transmit (Tx) channels is irrelevant for the reconstruction considerations in this study. The transmit mode was set to Siemens “True Form” to produce a circularly polarized (CP) transmit field. For in vivo data, three participants (two females ages 20 y and 24 y, one male age 37 y) were scanned. The study was approved by the Ethics Commission at the Faculty of Medicine of Leipzig University and written informed consent was obtained.
We acquired a 2D multi-echo spin-echo (MESE) sequence designed using PyPulseq.50,51 PyPulseq delivered a well-defined raw data stream, and the particular sequence was chosen for convenience to demonstrate multi-echo reconstruction. Additionally, PyPulseq enabled fast manipulation of sampling-scheme routines within the sequence.
We used an echo-train length of 8, an echo-spacing of 7.73 ms and a of 4.5 s. Fully sampled data was acquired in 17m 15s with an FOV of and a matrix size of
Sampling
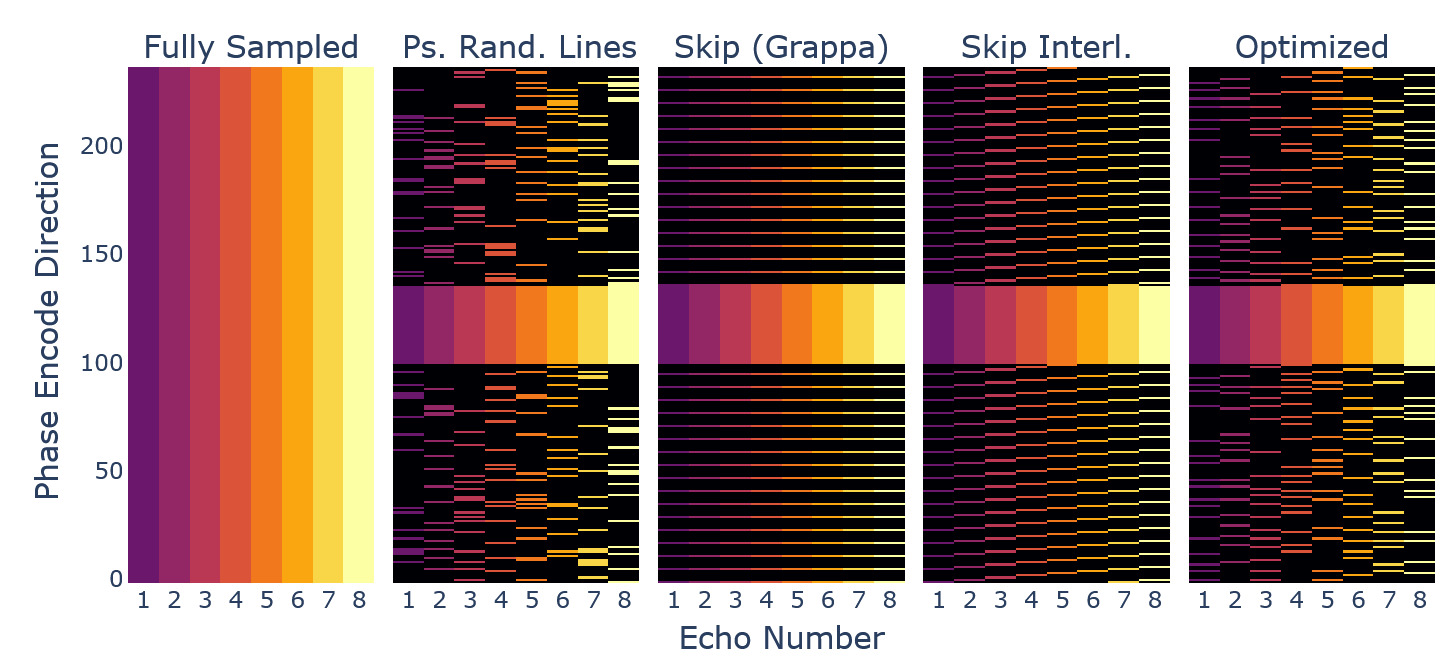
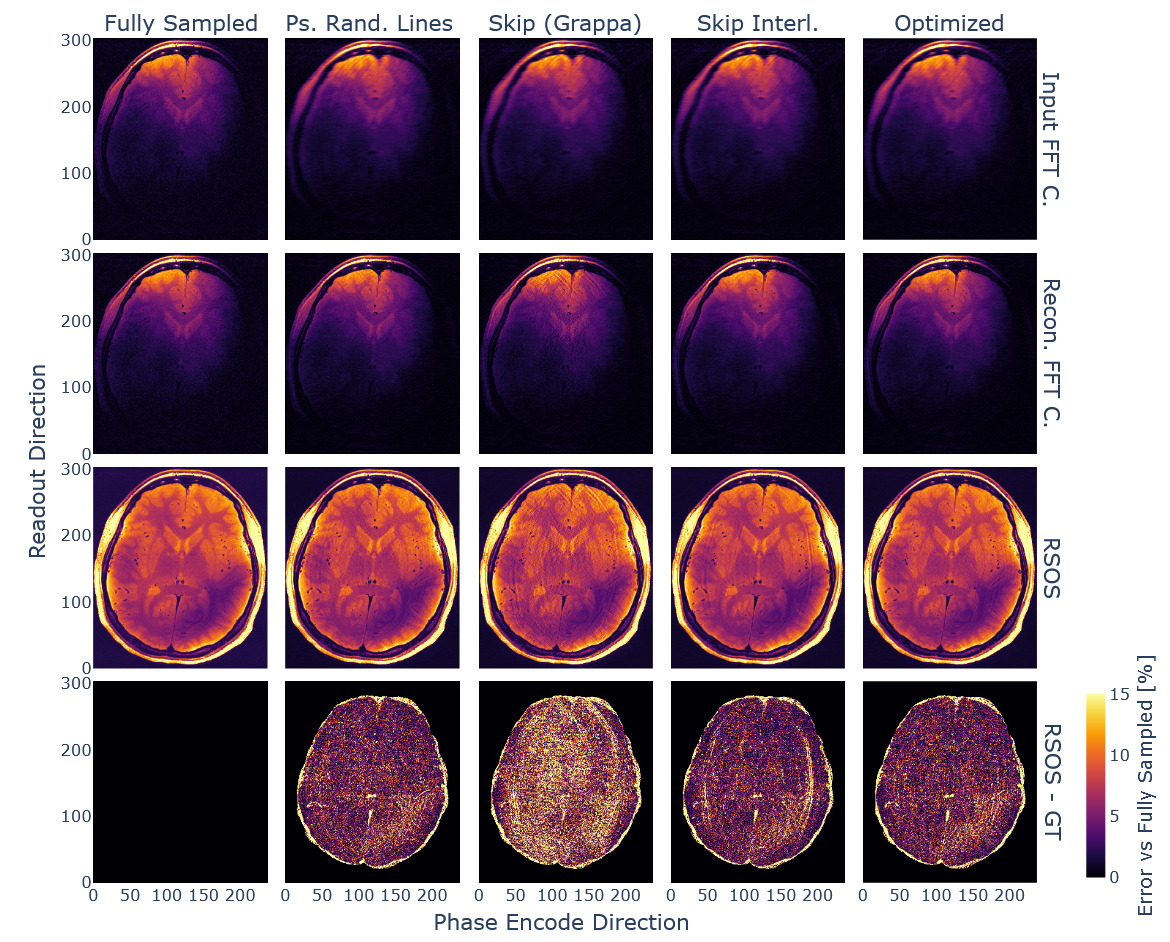
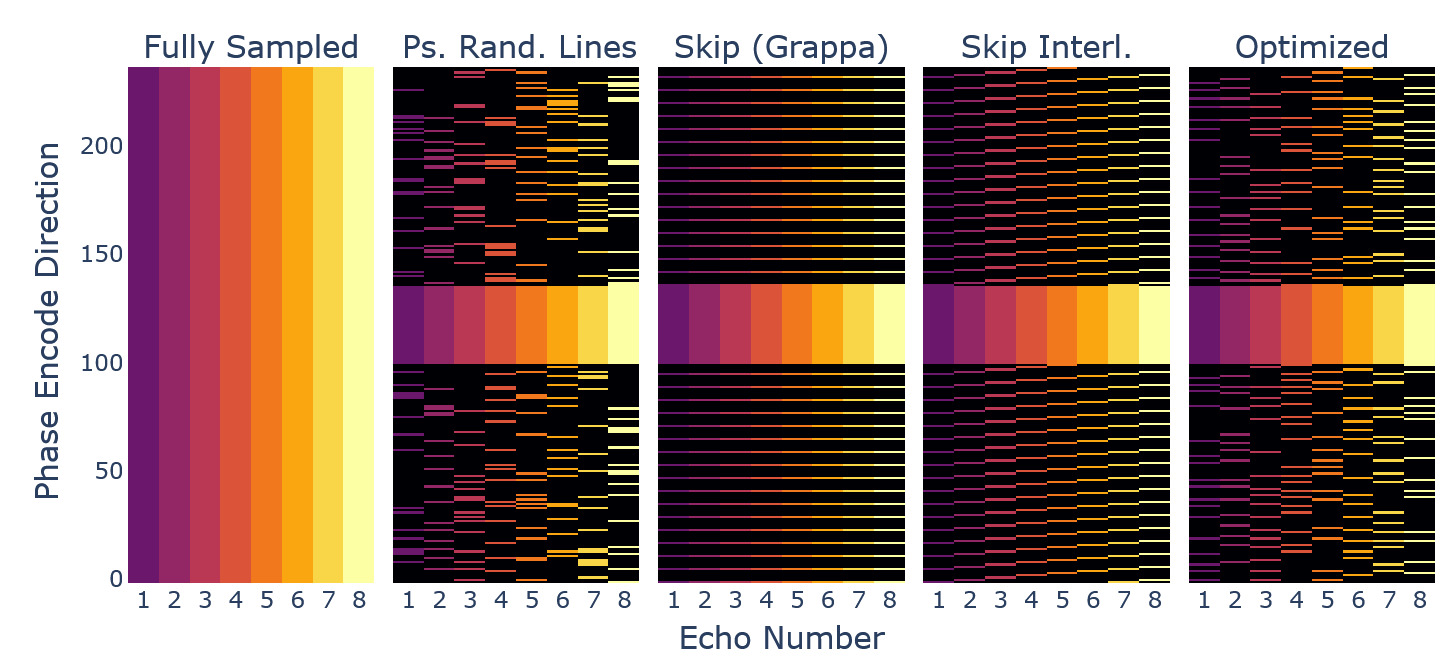
Retrospective undersampling was achieved using different masking of k-space data and zero-filling. The fully sampled dataset served as a reference. We used the following sampling patterns, which can be appreciated in Figure 12:
-
Pseudo-randomised sampling of points from a uniform distribution outside a central spherical AC region, without replacement.
-
Pseudo-randomised sampling of lines along one dimension from a uniform distribution outside the AC region, without replacement.
-
GRAPPA1 sampling, i.e. skipping of lines outside the AC region.
-
Interleaved skipping of lines outside the AC region with respect to the echo dimension, a GRAPPA-style pattern with a more homogenous coverage across echoes.52
Only the GRAPPA method does not provide complementary sampling across echoes. The other methods capture different k-space lines across the various echoes in coherent or randomised fashion, as it was found beneficial in joint-reconstruction settings.13,52
For each pattern we created an AC region with 36 central lines. We used an acceleration factor of in the data combination experiments. In our parameter optimisation experiments, acceleration factors were evaluated. For the sampling optimisation experiments we used a factor of such that, due to the data size, each echo was sampled using 76 lines.
Evaluation metrics
In all comparison or optimisation experiments involving the in vivo data, we calculated evaluation metrics with respect to the fully sampled data reference. We used normalised mean squared error (NMSE) 53 peak signal-to-noise ratio (PSNR) 54 and the structural similarity coefficient (SSIM) 54
Compute System
We used a dedicated Linux compute server with a 72-core Xeon Platinum 2.4 GHz CPU (4800 bMIPS) with 1 TB RAM and an NVIDIA l40S GPU with 46 GB RAM in all computational experiments.
Note, computation speed is dependent on used floating point precision (we used 32-bit precision) and the compute system, as well as underlying library implementations and backends. Thus, the presented results might not be directly transferable to other systems or software versions.
Algorithm innovations & technical implementation
We used PyTorch34 (version 2.4.1) and Python (version 3.10) to implement the PyLORAKS MRI reconstruction framework.55
We will refer to the original algorithm3,14 implemented in Matlab46 as M-LORAKS. Compared to M-LORAKS, a number of improvements were implemented, which will be outlined in the following sections. Additionally, the reconstruction result was tested against M-LORAKS to ensure comparable results.
Efficient computation and GPUs
In modern computing multiple factors lead to an immense increase in efficiency for vectorised or parallel computations.56–58 Hence, whenever possible, iterative or sequential loops should be avoided in favour of batched or vectorised operations, which are available in most modern scientific computing libraries. Additionally, using PyTorch, data and most computations can be transferred to GPUs (graphical processor units) for efficient and fast parallel computations. We used CUDA59 (version 12.4) and associated libraries (libcublas, libcufft, libcusolver, libcusparse) including vectorised functions for all presented matrix decomposition methods and other linear algebra operations.
Linear indexing for LORAKS matrix operators
M-LORAKS collects the LORAKS neighbourhoods of each k-space position within a circular neighbourhood by sequential iteration through all spatial k-space dimensions. This approach splits an indexing operation, i.e. the neighbourhood collection and rearrangement into a matrix form, into two steps. (A) the circular design necessitates a masking operation, and (B) the iterative collection uses a memory pre-allocation, which effectively is creating a copy of the input.
In our implementation, we used a linear indexing strategy to construct the neighbourhood matrix efficiently without excessive memory overhead, treating multidimensional array indices as offsets in the array’s flat (linear) memory space. Our implementation leverages this by first computing the linear offsets for a rectangular single patch and then broadcasting those offsets across all valid patch positions.
Thus, LORAKS matrix operators can be implemented as a single indexing operation into the image-tensor, yielding the desired neighbourhood matrix of shape (number of patches) (patch size). Vectorised counterparts are available to implement the back-projection equally efficiently. We create such linear index tensors once for the specific matrix operator using the mathematical formalisms detailed in Haldar.3 A single copy of these indices is moved to the GPU device, together with a k-space reconstruction candidate and the measured k-space data (in condensed form, i.e. only sampled points), yielding a simple indexing operation on the GPU to create the LORAKS matrix operator.
Effective reconstruction has been demonstrated with M-LORAKS use of a circular radius of which limits the matrix size.14,18 Hence, we used in the PyLORAKS framework to ensure similar neighbourhood sizes with rectangular patches. No effect on reconstruction performance was observable with the neighbourhood shape change. An example for the testing and validation is provided in the supplementary material.
Joint-Reconstruction
LORAKS reliably reconstructs multichannel data,4 if available using AC data for computational speedup (AC-LORAKS).15 Beyond coil redundancy, joint reconstruction across contrasts further increases data fidelity.13,52 We implemented PyLORAKS to use joint reconstruction capability by default and support contrast - and slice - dependent sampling masks, opposed to the original M-LORAKS implementation, where sampling was assumed to be equal across the input. Using the indexing scheme above, channels/contrasts were concatenated via reshaping (torch.Tensor.view()) without the creation of memory copies. In practice, iterative loops and masking were effectively avoided, the neighbourhood sampling is defined by the linear indexing method outlined above, while the channel and contrast combination is set using broadcasting and reshaping of the indexed data.
Computational speed and memory benchmark
The tests were set up on the same machine (see data & hardware section) using the PyLORAKS framework with CPU and GPU processing and AC_LORAKS (version 2.1)14,18 as M-LORAKS in Matlab46 aligning the algorithmic details (using the FFT approximation, alg=4, in M-LORAKS). We used a convergence tolerance of 1e-6 and maximum number of iterations of 5 in both cases to ensure speed benchmarks are not biased by early termination. Algorithmic performance was ensured to be similar to M-LORAKS in various test scenarios (up to numerical offsets expected with different software and due to the patch shape change). An exemplary test is provided in the supplementary material.
The timing was collected using Python timeit module and Matlab native functionality tic - toc with two warmup runs, and the results of three consecutive timed runs were averaged. Memory was measured using PyTorch functionality and the NVIDIA CUDA framework59 in the case of GPU computations.
CPU memory allocation tracking was implemented using a subprocess tracking for both M-LORAKS and PyLORAKS CPU computations based on Linux /proc - reads and a child process collection to extract the combined virtual memory high-water mark (VmHWM) value across all subprocesses.
Virtual data was created using a Shepp-Logan phantom (see data & hardware section). The details of the subsampling and acquisition did not influence the optimisation process and performance benchmark, as those are only dependent on data sizes and the settings of the weighing factor and the rank, which was set to
To keep the implementations as comparable as possible, the torch.linalg.eigh function was used to extract similar to the M-LORAKS code. Hence, the benchmarks did not include possible speedup by different rSVD variants (see fast SVD methods subsection) but showcased implementation improvements and GPU capabilities. We adapted the M-LORAKS code to allow for joint-reconstruction by concatenating channel and contrast dimensions and allowing non-uniform sampling schemes throughout the contrast dimension.
Loss estimation and automatic differentiation
We implemented the minimisation of equation 1, subject to the approximation given in equation 2, using a nullspace estimated from the LORAKS matrix built from AC data Here, the LORAKS constraint is approximated by projection of the operator matrix against which is obtained by computing the nullspace of the LORAKS operator matrix using only AC data as outlined in 15. The nullspace is regarded to be identical to the eigenvectors associated with the lowest eigenvalues. To compute the operator matrix was computed on the GPU device as outlined above (linear indexing subsection) using AC-data, before proceeding in two different ways:
-
We implemented a gradient descent solver relying on PyTorch’s automatic differentiation function40,60 for backpropagating the gradients through the loss function. A k-space candidate (copy of the zero-filled input, and PyTorch gradients attached) was initialised on the GPU device, and direct minimisation of the loss function in equation 2 using gradient descent was used. For the descent we used a learning rate (from 0.1 to 0.001) decreasing linearly across the iteration steps.
-
We mirrored the default algorithm of M-LORAKS subject to the available performance optimisations.3,14 That is, a fast approximation of equation 1 using FFTs was used and the backpropagation feature was not employed. This effectively reduced the optimisation to a least-squares problem for which an effective conjugate gradient descent (CGD) solver was used.
We present details on the advantages of both implementations.
Data combination and batching
Additional to achieving computational performance increases by careful allocation and implementation with PyTorch, PyLORAKS memory demands need to be reduced. Especially limited GPU memory restricts feasible use in high-resolution joint-reconstruction. We favoured joint-contrast over multichannel reconstruction, since complementary sampling patterns allow for more homogenous k-space coverage.52 I.e. we preferred batching the data in channel dimension when using joint-reconstruction if the available (GPU) memory was limited. That is, data was combined using all available contrasts and subsets of the available channels in batches.
Note, this is different from channel compression approaches, as all individual dimensions are reconstructed. We present the framework in this way for two reasons: (1) we use individual channel data in subsequent processing steps in our research, (2) adding coil compression can be regarded as a simple pre-processing step not impeding the results shown but rather facilitating further computational speedup. Coil compression was shown to be effective in conjunction with LORAKS reconstruction,3,13,14,33,41 and a respective module is included in the PyLORAKS framework.
The batched channel dimension was maximised to meet memory limitations, such that fast GPU computation performance was possible, but the data batches need to be reconstructed sequentially.
This is profitable, as data post-processing is possible after reconstruction without the necessity to correct data alternation by the respective channel compression method. As such, dedicated magnitude or channel combination methods, or denoising methods like LCPCA61,62 or NORDIC63 can be applied to the reconstructed complex-valued data. However, the expense is that bigger data sizes need to be accommodated compared to using channel-compression algorithms.
To maximise the leveraged data redundancy, we implemented channel-batching based on coil-sensitivity correlations. The undersampled AC data, composed of k-spaces points across channels, was used to calculate a distance using the channel correlation coefficients matrix :
\[ \boldsymbol{R}_{i j}=\frac{\boldsymbol{C}_{i j}}{\sqrt{C_{i i} C_{j j}}}, \text { with } \boldsymbol{C}=\operatorname{Cov}\left(\boldsymbol{k}_c^H, \boldsymbol{k}_c\right) \tag{3}\]
\[ \tilde{\Sigma}_c=1-\boldsymbol{R}\tag{4} \]
Based on this, clusters were calculated to maximise mutual channel correlations within each batch using a KMeans clustering algorithm64,65 and a pre-calculated cluster size depending on memory considerations. Thus, we obtained clusters (ensuring integer division) using: \[\mathcal{C} = \min_{\mathcal{\hat{C}}} \sum_{i=1}^{n_{b}} \sum_{j=1}^{n_{bc}} \|\boldsymbol{v}_j - \boldsymbol{\mu}_i\|^2\ ,\tag{5}\] where is the j-th row of and, is the centroid of cluster i:
\[\boldsymbol{\mu}_i = \frac{1}{\lvert \mathcal{\hat{C}}_i \rvert} \sum_j^{n_{bc}} v_j\tag{6}\]
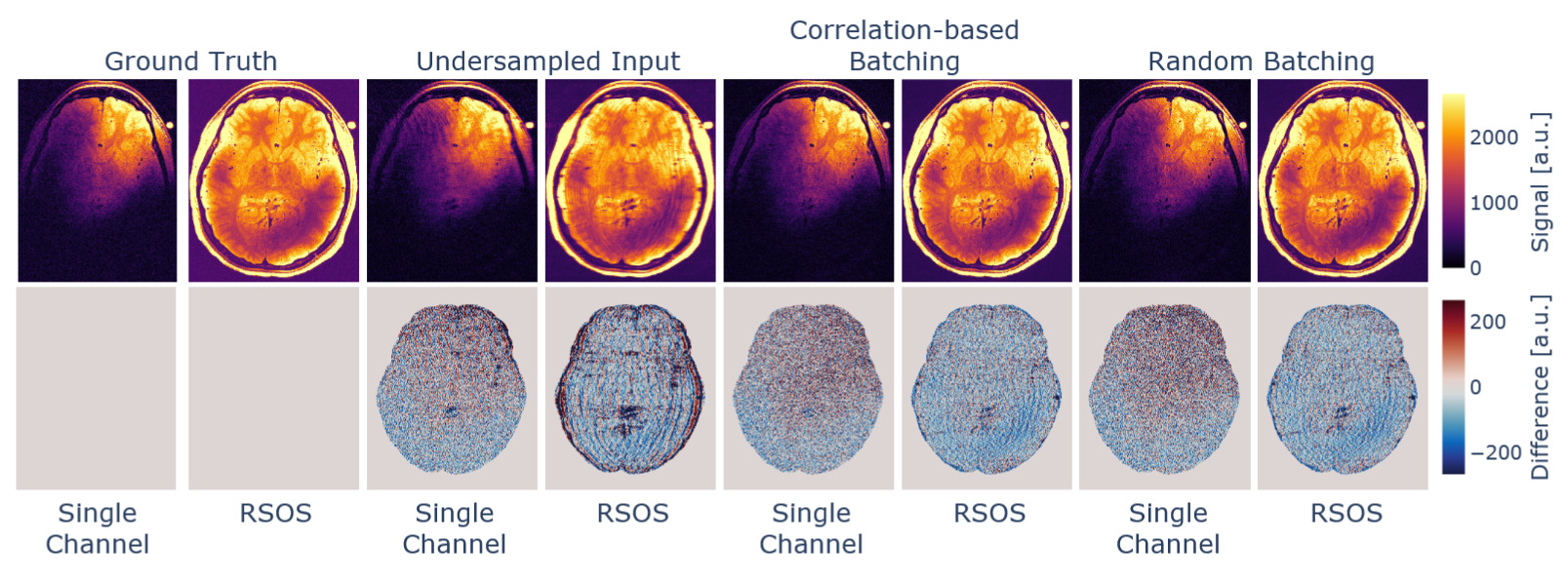
To evaluate the batching influence, we reconstructed retrospectively undersampled in vivo data (see data & hardware section), varying the used channel-batching method. The data was jointly reconstructed per batch across the channel-batches and the number of available contrasts. This procedure was done per-slice, as the channel correlations are dependent on the coil sensitivity profiles, which will vary across the extent of the input volume.
The data was reconstructed slice wise for the slices. For each slice we combined batches of channels and all echoes, purposely choosing a low cluster size to evaluate the influence of the clustering. Hence, the input data contained of the matrices where and
The algorithm was set up using a rank parameter and the neighbourhood patch side-length was We proceeded with two different reconstruction strategies, which differed only in the preparation of the data batches, while all other reconstruction parameters remained constant. That is, (a) the channel dimension was split in chunks of size 4 to form from the input data stream, and (b) the input data was subject to the channel-correlation-based batching with cluster size 4. This led to different channel combinations per slice.
The aim of this experiment was to evaluate the influence of mutual information across a batch. We hypothesised that using channels with a higher cross-correlation would yield increased low-rank matrix properties and thus possibly increased LORAKS performance, which would also support the use of coil compression techniques.
Data scaling and fast SVD methods
In addition to batching or compression strategies, other implementation details can be changed to accomodate increasing matrix sizes inherent in high-resolution joint-reconstruction MRI settings. Specifically, the computational performance of the matrix decomposition at the core of the low-rank enforcement is poor if SVD is employed. Since SVD is a heavily used technique in many data-driven sciences, performant variations have previously been suggested.17 Besides using the built-in torch.svd_lowrank method (LR-SVD)26 which mirrors computational gains described in prior work,25 we implemented matrix decomposition methods in PyLORAKS to increase computational performance. Since randomised variants of SVD do not specifically leverage or are dependent on the Hankel-like structure, and are suited for strong spectral features found in LORAKS matrices, reliable subspace capture is assumed in their deployment.66
The following variation of methods were implemented for benchmarking as they were found computationally beneficial compared to a standard SVD: a randomised SVD (rSVD) method17 similar to LR-SVD, subspace-orbit randomised SVD (SOR-SVD),16 and a randomised QLP (RAND-QLP) algorithm.67
All randomised matrix decomposition algorithms were previously found to benefit from using power iterations and oversampling 26 two parameters facilitating the randomised sampling and compression of the input data. In the process, a data matrix of reduced size is formed to which a QR decomposition is applied, resulting in the computational benefit. This matrix is of rank i.e. the complexity of randomised SVD variants scales with the target rank which is usually much smaller than the input matrix size for joint-reconstruction of high-resolution input. We used empirically determined values and for all randomised decomposition implementations, which have been found to increase estimation accuracy.16
The matrix in equation 2 is estimated from the nullspace of the LORAKS operator matrix built from AC data consequently minimising the use of matrix decomposition methods in AC-LORAKS to a single nullspace estimation. Increased computational efficiency previously was reached by using an eigenvalue decomposition on a Hermitian matrix built from reducing the dimensionality to the shorter axis (usually The nullspace can be estimated using the trailing vectors of the eigenspace corresponding to the lowest eigenvalues. Thus, we included PyTorch torch.linalg.eigh function (EIGH) in the investigation of rank-revealing methods, as its Matlab counterpart was found to perform best in the M-LORAKS default implementation. An algorithm for randomised nullspace approximation was also tested (RAND-NS) estimating the trailing eigenvectors through randomised projections.29
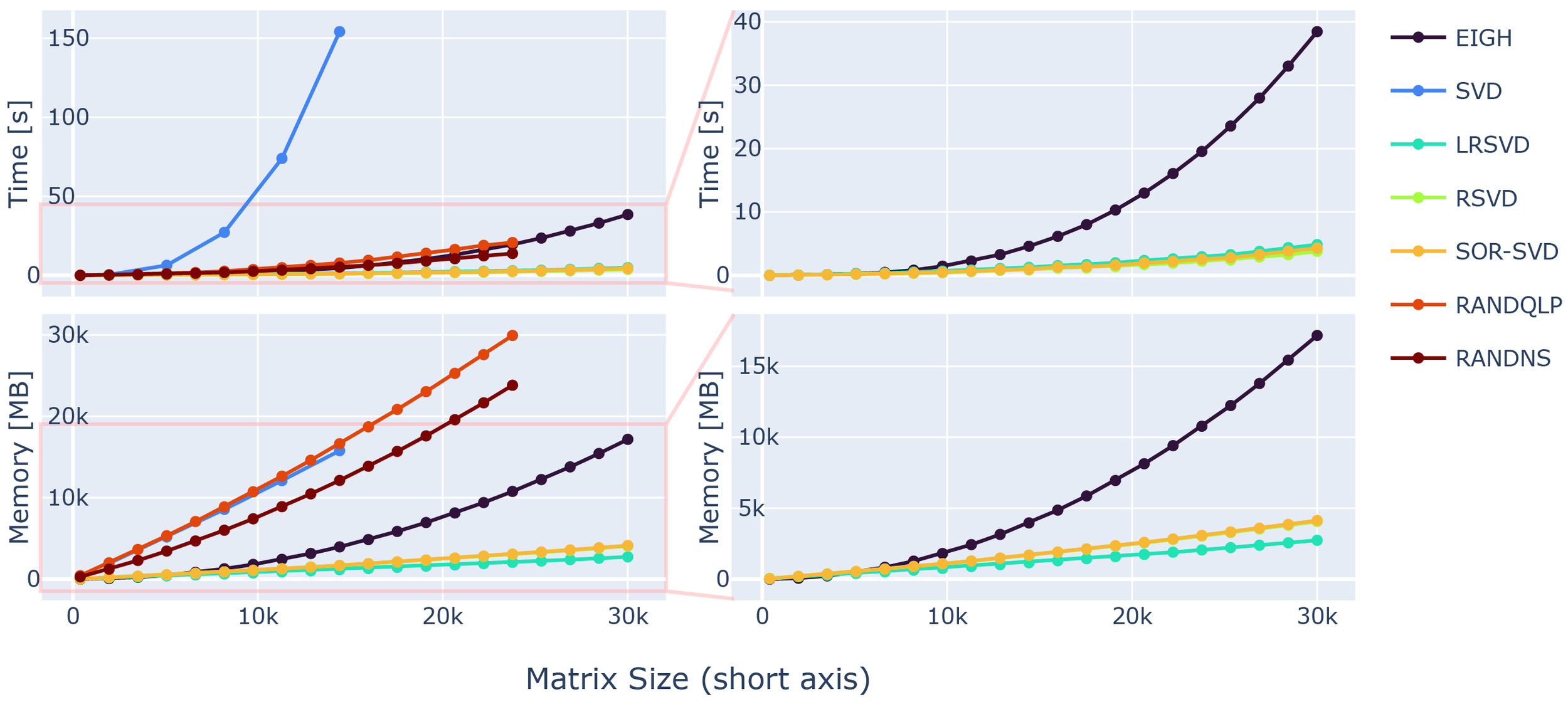
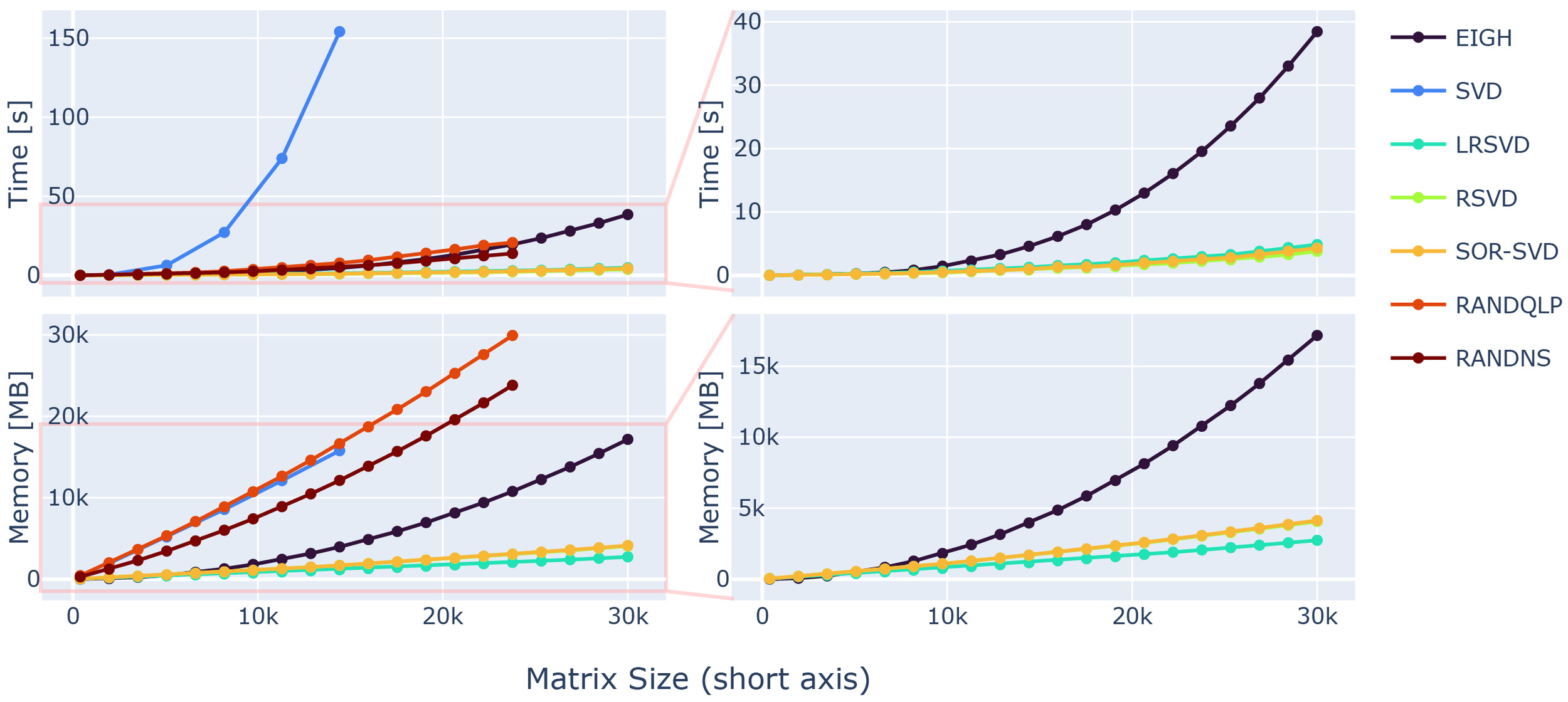
First, we evaluated the speed and memory performance of the randomised matrix decomposition methods for our large matrix sizes. This was deemed necessary as the underlying computational libraries used for matrix algebra possibly switch to different backends dependent on the matrix input sizes.68 Thus, randomised SVD variants might not perform close to their theoretically projected memory and time complexity. We used synthetic matrices (see data & hardware section) to benchmark the matrix decomposition. Theoretical predictions about the computational complexity scaling in time and memory are available.16,17 For an instructive overview, Figure 5 shows the complexities reached in our settings.
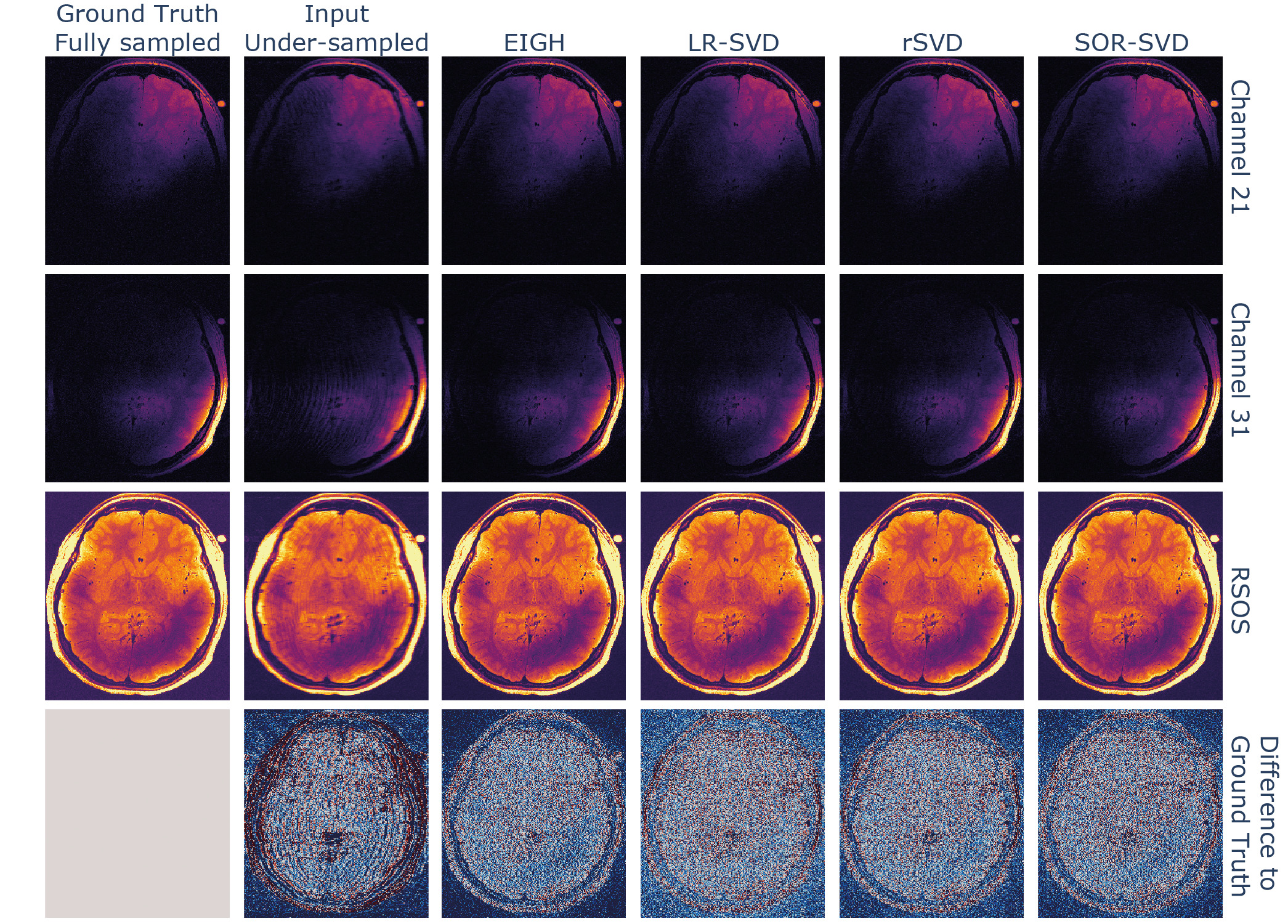
Second, we compared the reconstruction performance of the PyLORAKS algorithm substituting the rank-revealing operation at its core. This reconstruction was done using retrospectively undersampled in vivo data (see data & hardware section). For this experiment only the methods LR-SVD, rSVD, and SOR-SVD were used, as faster computation times and lower memory footprints were found in the above benchmark.
We used these variants for the estimation of in equation 2, and later approximation of the low-rank loss. For all randomised variants tested, we used a target rank with being the rank parameter of the PyLORAKS algorithm. We ensured the target to be much smaller than the matrix size of the LORAKS matrix as this defines the respective method’s computational efficiency. We picked the trailing eigenvectors to approximate the nullspace
Both of these benchmark experiments were solely done using the GPU capability.
New advances and possibilities for MRI
Our target was a computationally efficient LORAKS implementation considering memory and time constraints. Thus, additionally to the presented methods, PyLORAKS can be used as drop in replacement of the current M-LORAKS implementation to offer large computational boosts. For example, the computationally demanding A-LORAKS-CS24 or the OEDIPUS69 framework can benefit from efficient and fast LORAKS computations. Furthermore, the capability of backpropagation through the algorithm makes PyLORAKS a suitable candidate to be used in physics-informed deep learning42,43 or generative AI models,44 separating our implementation from previous attempts to algorithm computation feasibility enhancement,38,39 enabling new features.
To demonstrate the capabilities of PyLORAKS, we used it for a multi-echo 2D acquisition. We evaluated the choice of algorithm parameters and on reconstruction quality, as well as for the design of an optimised sampling pattern. The presented methods generalise to arbitrary acquisition schemes.
Parameter selection
Usually, the value of the algorithm parameters and are manually chosen by the user, and its influence is assessed empirically after reconstruction.14,20,21 In conjunction with J-LORAKS this procedure is impractical due to low computation speed and high memory demand.
The LORAKS algorithm enforces the LORAKS operator matrix to be of rank A low-rank parameter encourages effective filling of missing data and denoising by reducing the variance of the available data based on the used LORAKS operator, but can introduce bias if too low rank enforcement is used.3 While the denoising capabilities of LORAKS have been demonstrated,3,13,15 no head-to-head comparison for LORAKS denoising capabilities compared to dedicated denoising algorithms is available. However, recent studies suggest that for optimal control and results of image denoising, dedicated algorithms should be preferred.21,63,70
On the other hand, high rank favours greater data fidelity but may fail to exploit the low-rank prior, which comes at the cost of acquisition acceleration capability. Other effects on the algorithm are more intricate. For example, in AC-LORAKS a higher rank parameter reduces the size of extracted from the nullspace of the LORAKS matrix used in equation 2, and thus reduces the computational cost after extraction of
Similar effects can be seen with changes in the regularisation parameter If the data signal-to-noise ratio is sufficient, can be set very low, which was found to be beneficial for interpolation of missing data without modifying acquired samples.13 Alternatively, in the true data consistency formulation of the algorithm, the LORAKS constraint is calculated for missing data points only. This is preferable for computational reasons, as the computation iterations are only done over a reduced subset of the overall k-space.
Automation of the LORAKS parameter choices has been proposed using SURE and a soft-thresholding approach71 in conjunction with compressed-sensing and total variation constraints,24 at the cost of additional computational overhead. SURE allows calculating the mean squared error in estimating a true signal from measurements corrupted by additive Gaussian noise22 using only acquired samples. Consequently, SURE has been used in the context of denoising algorithms,72 and was extended to reconstruction algorithms when the constraint formalism resembles linear denoising operators,73 for which analytic expressions have been proposed.23 This is possible for the independent LORAKS constraint24 in equation 1).
However, the full LORAKS implementation involving data consistency and constraint regularisation (via is nonlinear, typically necessitating Monte Carlo or Hutchinson methods to estimate the operator divergence further adding computational complexity. Furthermore, finding more complex dependencies (e.g. LORAKS rank dependence on matrix size or sampling pattern) might not be possible using SURE, as e.g. divergence with respect to a sampling pattern is not reasonably defined. Nonetheless, we included a comparison with a SURE optimised rank using a method similar to Ilicak, Saritas, and Çukur,24 briefly described in the supplementary material. For this other parameters (complementary subsampling scheme, number of contrasts and were kept fixed and were evaluated by the method below.
It is common for MRI studies that the data sampling method and the basic data structure (dimensionality, FOV) remain similar between acquisitions. An optimisation of the algorithm parameters and evaluation of their dependencies can be tied to the specific acquisition and is a possible prior to reconstruction of individual data acquisitions. We evaluated the reconstruction performance with respect to the algorithm parameter settings of and
We used a fully sampled and retrospectively subsampled in vivo dataset obtained from the multi-echo spin-echo (MESE) acquisitions (see data & hardware section). The PyLORAKS joint-reconstruction was followed by a root-sum-of-squares (RSOS) channel combination to obtain magnitude data.
Since the autograd framework is not suited for mixed integer optimisation, we chose a Bayesian sampling optimisation method74 within the wandb framework75 (version 0.17.3). Thus, the presented parameter investigation is enabled by the computational gains of PyLORAKS. To vary the neighbourhood matrix size of our input data, we varied the channel batch size In our optimisation, the reconstruction time for one optimisation run, for a single slice of the input data and joint-reconstruction took s on average. It is varying with the choice of
We introduce an overall minimisation score to optimise the input parameters and with respect to all of our metrics, scaling each of the individual metric values accordingly:
\[\min_{r, \lambda}\ \eta_{\text{loss}} = -\eta_\text{ssim} - 0.01\ \eta_\text{psnr} + \eta_\text{nmse}\tag{7}\]
The evaluation followed three distinct aims with respect to the algorithm input parameters and :
-
Find correlations between the number of missing points and the parameters.
-
Find correlations between the used input matrix dimensions and the parameters.
-
Evaluate the influence of the undersampling pattern with respect to variation in the parameters.
This assessment is specific to the used sequence and hardware due to the available number of channels and contrasts in the joint-echo reconstruction, the individual contrast content, and SNR. Nevertheless, a number of general conclusions can be drawn from the optimisation procedure.
Sampling optimisation
PyTorch’s autograd framework, described in the loss estimation and automatic differentiation section, allows direct gradient computation via backpropagation, with additional support for complex valued differentiation using Wirtinger calculus,76,77 essentially tracking gradients in each computation step and applying the chain rule. Further information can be found in.40 This feature was used to inform the sampling density of the input data using a single forward and backward pass of the reconstruction algorithm. We used fully sampled data, assuming true data consistency (i.e. only computing the LORAKS regularisation part in equation 1), to compute the gradient of the PyLORAKS loss function with respect to each sampled point.
We denote the loss function in Equation 1 with and compute the gradient with respect to the input by propagating through the loss objective in a single pass, obtaining PyTorch gradients attached to the k-space candidate: \[ g(x, y, c, e) = \nabla_k \mathcal{L}(k) \in \mathbb{C}^{N_x \times N_y \times N_c \times N_e}\tag{8}\] Taking by considering a fully sampled k-space input, we note that can be obtained from the Taylor expansion around using to indicate a small perturbation at point Thus, under the assumption of smoothness and linearity in local k-space subregions, the gradient amplitude can be regarded as a first order predictor of the change induced by corrupting (or removing) sample Hence, equation 8 serves as a local sensitivity measure of the reconstruction loss to each sample under the imposed low-rank constraint.
We interpret a larger as a sign of greater importance of the respective samples to the image reconstruction problem. Collapsing over channels yields: \[ s(x, y, e) = \sum_{c=1}^{N_c} \bigl|g(x,y,c,e)\bigr|\tag{9}\] This way we can deduce a sampling density mask across the input slice. Since in our case, we were interested in subsampling along the phase encode dimension of a 2D sequence, we aggregated to obtain the phase encode density per index and formed a probabilistic sampling density per echo:
\[ d_e\left(i_y\right)=\sum_{k_x} s\left(k_x, i_y, e\right) \tag{10}\]
\[ w_e\left(i_y\right)=\frac{d_e\left(i_y\right)}{\sum_{k_y} d_e\left(k_y\right)} \tag{11}\]
Complementary echo sampling has previously been shown to increase the reconstruction performance of LORAKS.13,52 Thus, we sampled a mask from per echo using an adaptive sampling method78 to ensure complementarity across echoes.
We applied this procedure to fully sampled in vivo MESE data from each participant (see data & hardware section) to compute one-pass gradients of PyLORAKS and derive an average Averaging across subjects yields a nominal density for the MESE 2D sequence. Because the gradient field is contrast- and sequence-dependent, the resulting density should be viewed as a data-driven guideline that can be recomputed for other sequences or contrasts.
The obtained sampling pattern was used for retrospective undersampling of the data and compared to the four other 2D sampling strategies given in the previous section. We used 36 AC lines and an acceleration factor of 5 with respect to the coverage outside this region. Hence, due to the data size, each echo was sampled using 76 lines.
The undersampled data was subjected to PyLORAKS joint-reconstruction using the same parameters in all reconstruction runs. The channel batch size was set to LORAKS parameters where i.e. true data consistency, and
The resulting reconstructions were Fourier transformed and channel-combined using an RSOS combination to obtain magnitude image data. We used the same metrics to assess the reconstruction quality: NMSE, PSNR, and SSIM.
We conducted an additional validation experiment. For each k-space point in the fully sampled dataset, we removed the sample by inserting 0, and measured the degradation to the full k-space reconstruction, using (as well as defined in equation 7: \[ \Delta_i = \eta(k_{\text{fully sampled}}, k_{i, \text{dropped}})\tag{12}\] Effectively, we measured the k-space interpolation ability of LORAKS for each point and we take as the ground truth for the location importance to compare against the density obtained via gradient propagation in Equation 11 by calculating Pearson and Spearman correlation coefficients.
This approach is computationally exhaustive, necessitating a full reconstruction run for each k-space point. Thus, we used some simplifications for the comparison: We adapt aggregating the readout direction and channels, as in the gradient-based optimisation method (Equation 9). Hence, we are calculating Equation 12 per phase encode, zero-filling each full line at a time.
The reconstruction was done using the same settings as above (channel batch size and took h per slice iterating through all phase encode lines per echo, except for lines in the AC region as this would yield erratic AC-LORAKS performance. For comparison, the single-pass computation using propagation of Equation 8 took s per slice.
Results
Algorithm innovations and technical implementation
Different tests and validation runs demonstrated that the implementation of PyLORAKS achieved the same reconstruction fidelity as M-LORAKS when using equal algrotihm parameters. An exemplary comparison can be found in the supplementary material.
Computational speed
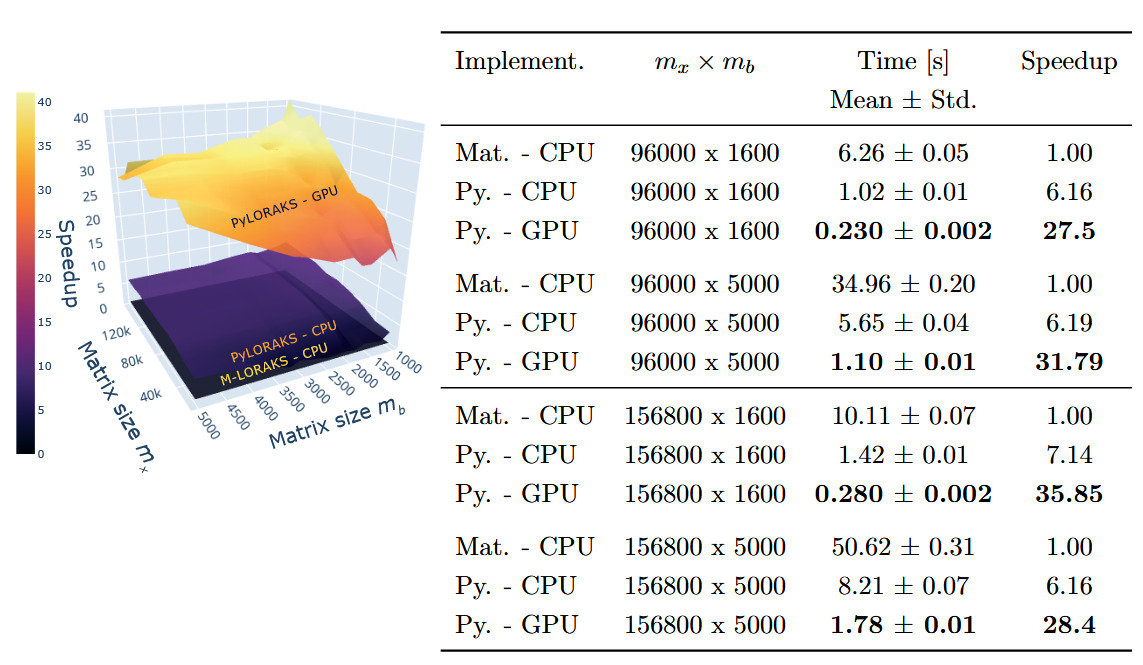
The PyLORAKS implementation offers faster computation compared to M-LORAKS. The speed differences between PyLORAKS in CPU and GPU processing modes versus the (CPU only) M-LORAKS implementation can be found in Figure 2.
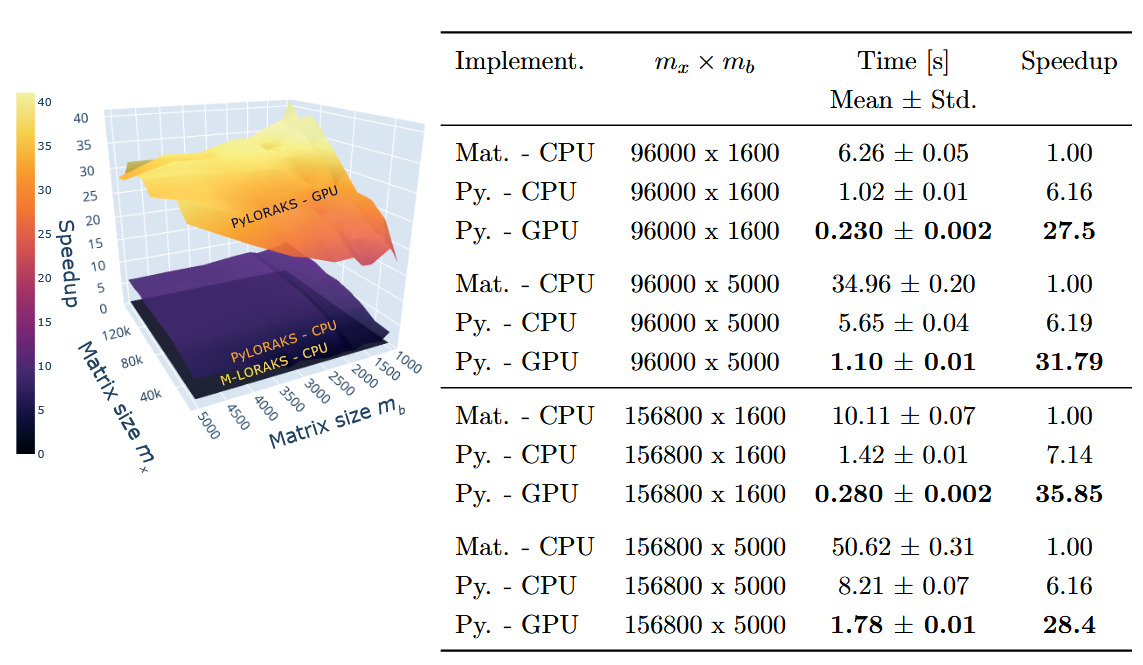
A great improvement was achieved using PyLORAKS compared to M-LORAKS irrespective of matrix sizes. Across all benchmarked input matrices we found an average speed increase of 5.75 using PyLORAKS and CPU computations. However, the highest speedups were observed when increasing spatial matrix size and fairly small or moderate neighbourhood matrix dimension This is presumably due to the improvements in linear memory layout and parallelisation of computations. The performance of the actual matrix decomposition algorithm (eigh in this case) was not assumed to vary drastically between Matlab and Python implementations and scaled with the smaller matrix dimension, i.e.
The PyLORAKS GPU implementation resulted in a substantial acceleration of computations, yielding an average speed increase of 29.11 across all tested matrix sizes compared to M-LORAKS. Note that due to the high computational demands, LORAKS is commonly used on a per-slice computation iteration (in M-LORAKS and PyLORAKS). Hence, the per-slice time savings presented here additionally scale with the number of slices to process, considering whole volume reconstruction. The resulting speed improvements mark a step towards real-time-imaging applicability of joint-reconstruction PyLORAKS, with the computational speed well below 1s for scan sizes encountered in high-resolution imaging (see Table 2).
Furthermore, the matrix sizes are given by and The biggest matrix sizes given in Table 2 correspond roughly to a data size (without slice dimension) of i.e. a scan using a 32-channel receive coil and three contrasts, or similar configurations if batching is used.
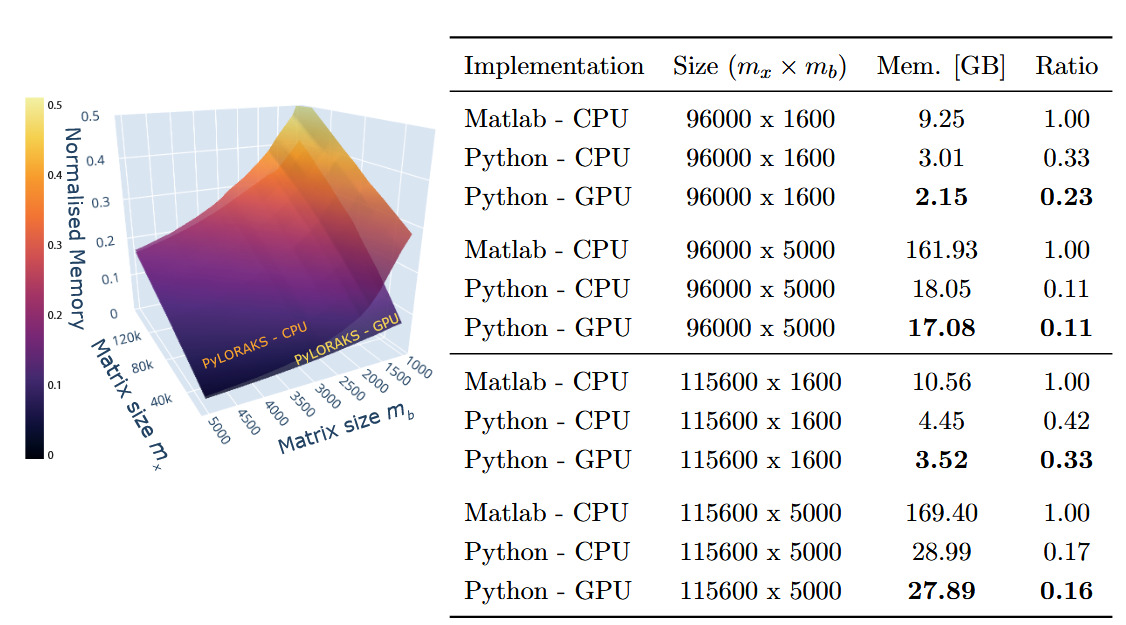
Memory
The memory allocation of the algorithm was tracked, including the data loading to RAM and the overhead created by the software (e.g. memory allocation for matrix decomposition operations). The resulting benchmark is visualised, and a subset of the numbers are given in Figure 3. The projected memory complexities match literature values.16,17
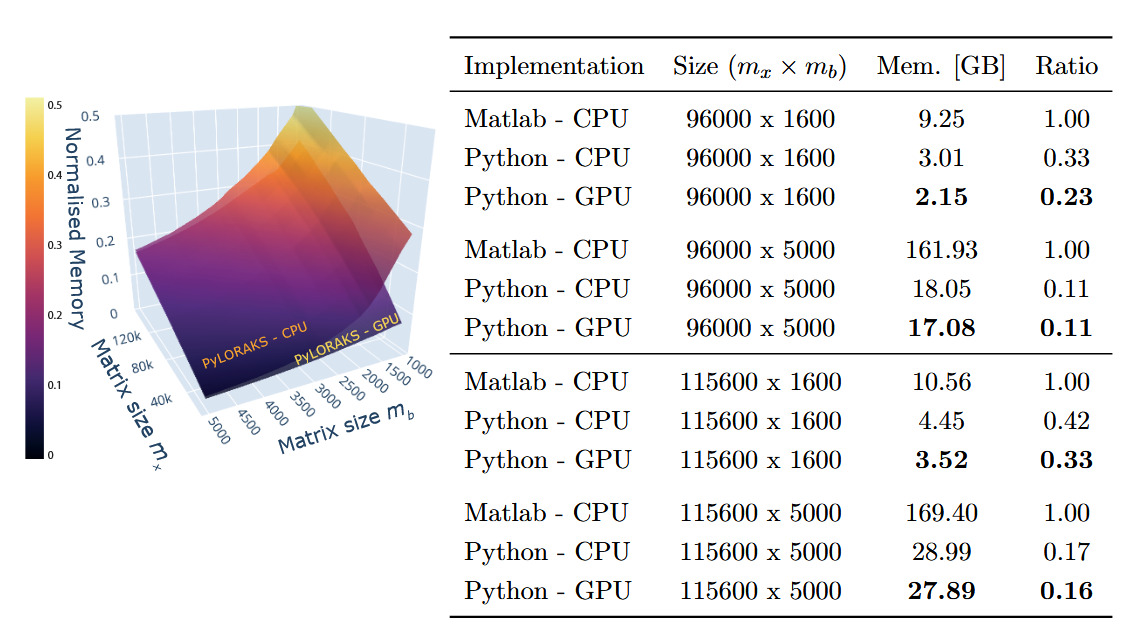
Averaged across all tested matrix sizes, we found PyLORAKS to be using only of the memory compared to M-LORAKS for the same computation when using CPU processing. This is presumably due to increases in efficiency of memory allocations and linear indexing and the absence of any loops in the core functionality. The memory usage ratio compared to M-LORAKS dropped even more for big matrix sizes, to as low as in some cases, as can be seen in Figure 3.
In both cases modern hardware might be able to efficiently use parallel CPU computing to process datasets. However, our memory tracking was set up to follow all child processes created by the algorithms. Thus, if hardware memory is limited, the processing might not be done in parallel but sequentially and is possible with smaller available total memory than the values presented here, at the cost of increased computation time.
For the PyLORAKS GPU computation mode an even smaller memory footprint was achieved, using only compared to the M-LORAKS processing when averaged across all tested matrix sizes. Again, the memory usage ratio compared to M-LORAKS was lower for big matrix sizes, reaching below in some cases, as can be seen in Figure 3. The drop compared to the PyLORAKS CPU mode is due to careful transfer of only necessary data to the GPU RAM, which on average saves around of memory. However, it follows that PyLORAKS GPU mode allocates this amount of memory additionally on CPU memory, primarily for loading in the data.
Note, AC-LORAKS is based on an approximation of which decreases in size with increasing rank. This way, the allocated memory is not only dependent on the input data size but also the algorithm parameters and
Data combination and batching
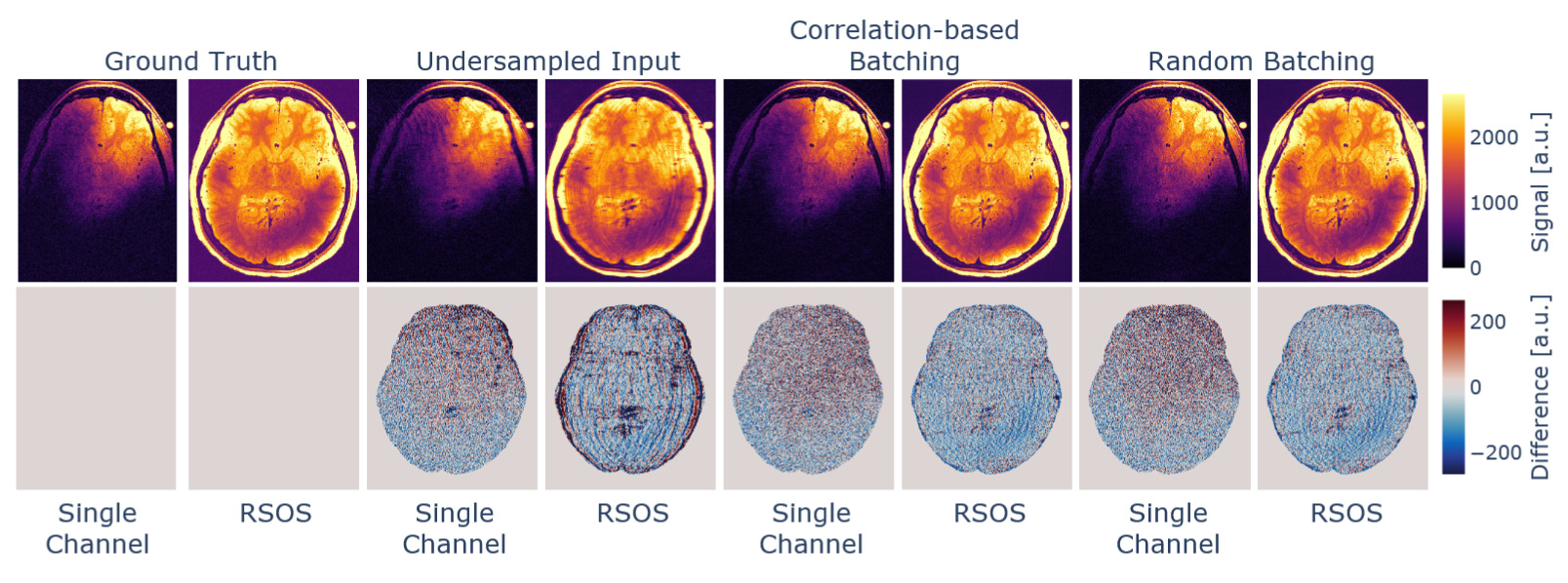
The reconstruction of the data using different channel combination methods in conjunction with batching along the channels can be seen in Figure 4. We compared the reconstruction to the fully sampled data after brain masking, and the derived metrics can be found in Table 1. The channel-correlation-based batching resulted in increased performance metrics, while the difference in the reconstruction is hard to notice visually. This can be regarded as a minor performance boost but likely will not suffice, e.g., to be traded for higher acceleration in the acquisition process.
Data scaling and fast SVD methods
For optimisation of the loss function in 1, the rank-revealing decomposition (SVD or eigenvalue decomposition) can be substituted by a randomised variant more effective for big matrix sizes. The performance of each method was tested separately, processing the decomposition on simple input matrices. The speedup of the respective method was substantial and can be appreciated in Figure 5. For growing matrix sizes, an SVD scales linearly in Memory usage and quadratically in computation time.
The memory overhead of randomised versions is dependent on the target rank and an oversampling parameter making memory saving possible, as the memory allocation overhead of randomised SVD variants is dependent on the chosen target rank. Hence, memory allocation of the respective randomised methods is possible in a controlled manner, e.g. tailored to the available hardware.
While the EIGH does offer considerable performance increase faster) compared to the standard SVD, it falls short compared to other randomised rank-revealing decomposition alternatives (see 5, right column). While the RAND-NS and RAND-QLP methods offer considerable speedup, close to what can be achieved with the EIGH method, their demand on memory is similarly high as standard SVD methods.
Further speed increases are possible by using the proposed rSVD,17 LR-SVD26 or SOR-SVD16 methods, offering a -fold speed increase for the biggest matrix dimension used in the test comparison to EIGH. The computational efficiency is projected to be even greater with higher-dimensional input. Thus, the use of randomised SVD variants is preferable, especially with increasing matrix sizes encountered in high-resolution MRI reconstructions.
Similarly, EIGH, rSVD, LR-SVD and SOR-SVD are all preferable in terms of memory consumption. Where again the former shows deficits, with more than -fold more memory demand for big input matrices. The memory consumption agrees well with complexity estimates given in literature.16,17
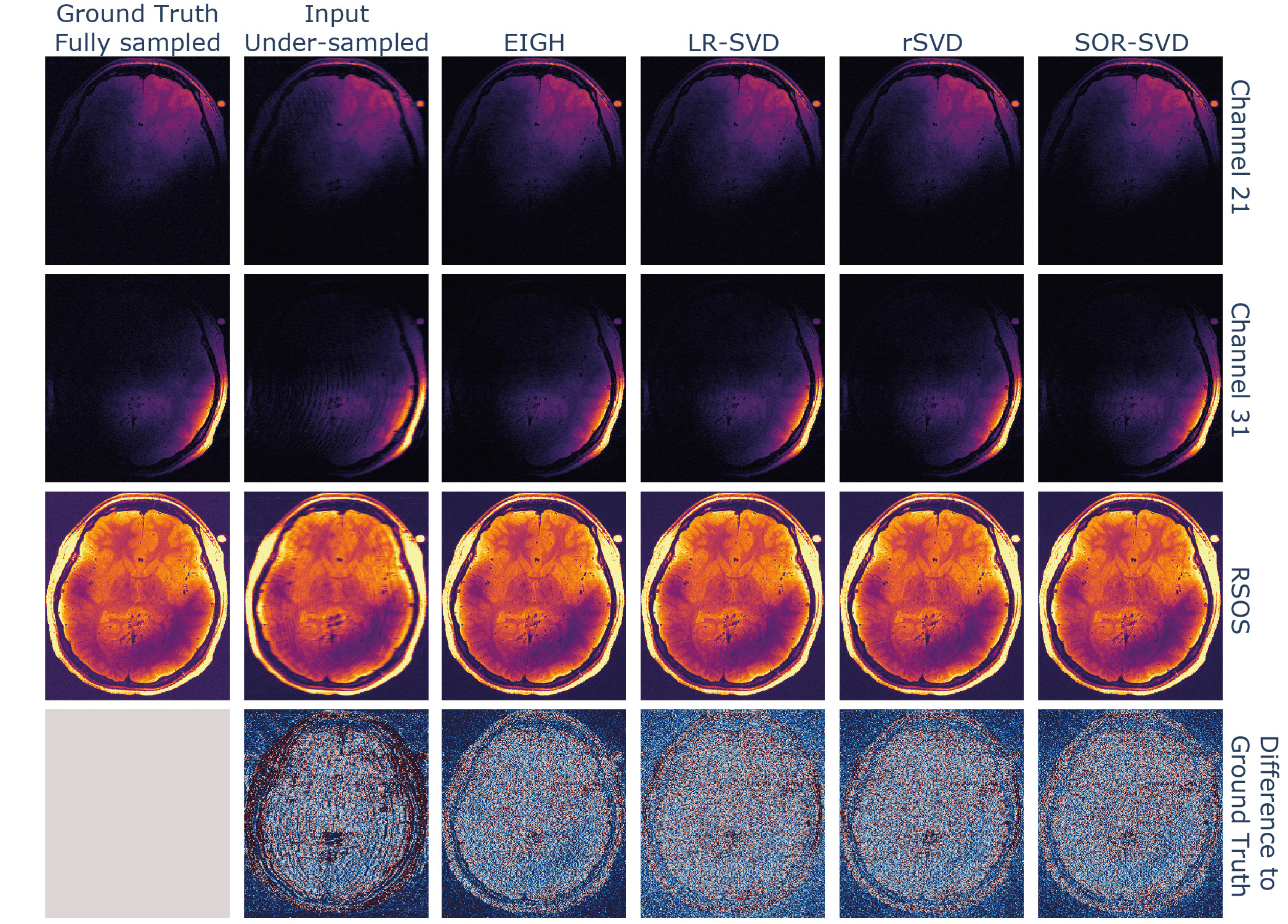
We compared the reconstruction performance of the SVD variants with favorable memory and time demands, which is shown in Figure 6, by substituting the matrix decomposition operation within the algorithm with the respective method. All tested randomised SVD variants showed similar reconstruction performance to the EIGH (default in M-LORAKS) method, the used metrics are shown in Table 2. While the LR-SVD method appears to be optimal with respect to the NMSE and PSNR, the original EIGH method achieves the highest SSIM score. However, rSVD and SOR-SVD were able to achieve quicker computations for the dataset used.
A substitution of the rank-revealing operation when using LORAKS reconstruction for high-dimensional input data was beneficial computationally and resulted in comparable image quality as the standard LORAKS reconstruction implementation. The computational benefit of using randomised SVD variants is dependent on the number of nullspace eigenvectors used for the nullspace approximation (here as well as the matrix sizes in general. Presumably, even higher speedup is possible given the randomised SVD benchmarks in Figure 5 when bigger matrix sizes are involved or with optimising the dimensionality used for nullspace approximation.
New advances and possibilities for MRI
The results of the acquisition optimisation for our MESE sequence are presented in the following, using different features of the PyLORAKS framework, such as its backpropagation capabilities.
Parameter selection
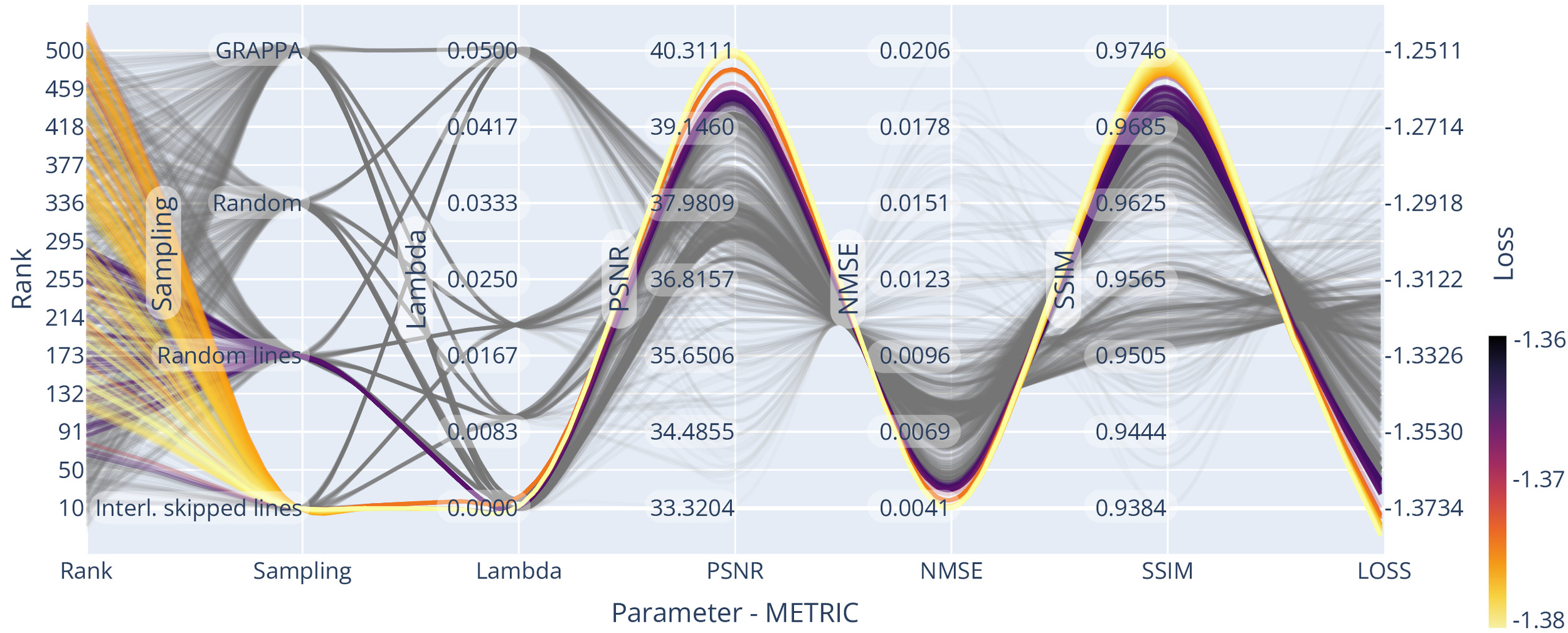
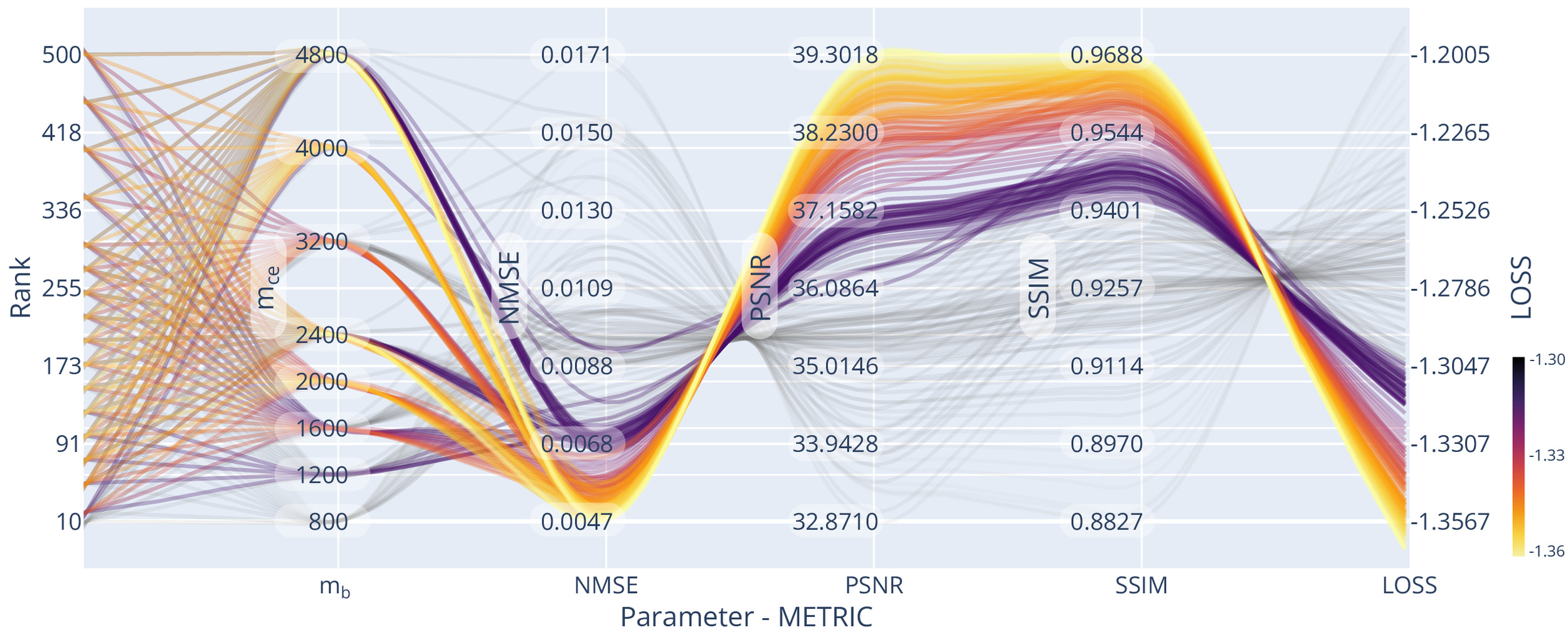
We optimised the reconstruction algorithm parameters for the highest quality reconstruction of our data compared to a fully sampled dataset. We obtained parameter trend-lines for and the used sampling patterns for a 3-fold acceleration, which can be seen in Figure 7. Less heterogeneous k-space coverage across the sampling pattern for joint contrasts, like in GRAPPA, reduced the resulting reconstruction quality. Using random-line sampling or interleaved skipping of outer k-space lines across different contrasts yielded the lowest loss values, which is in line with previous findings of performance increases with complementary echo sampling.13,52
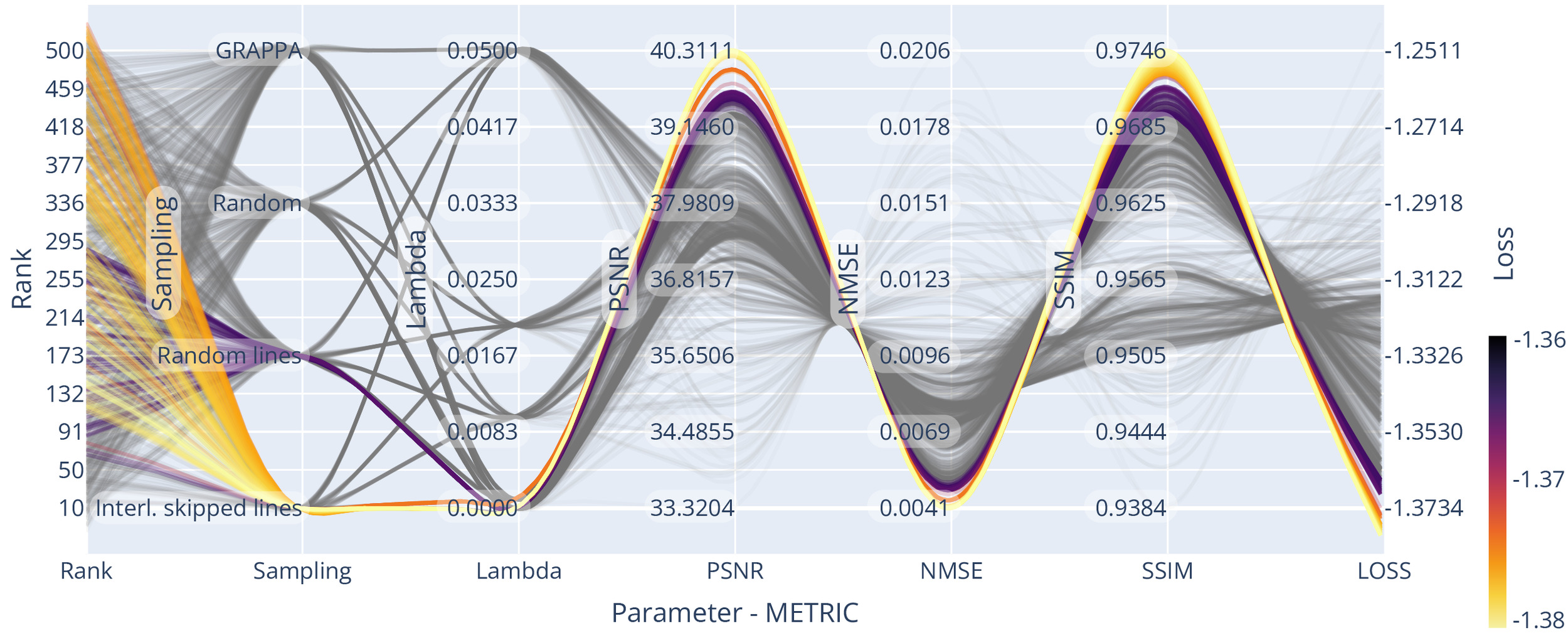
We found optimality in all metrics using the true data consistency formulation over the regularised version, updating only missing data points in the reconstruction. Whenever noise suppression and handling of imperfect data was not one of the main aims in the reconstruction or could be achieved with dedicated processing steps, the true data consistency formulation offers advantages.
For example, for all considered sampling patterns except GRAPPA, setting resulted in the highest SSIM and PSNR and the lowest NMSE. On average the NMSE increased for compared to and much higher values for higher settings of Similarly, SSIM decreased for compared to and again even lower values were found for higher settings of For the GRAPPA sampling, low values of resulted in loss minimisation and a small advantage over the true data consistency setting, which corresponds to other findings13 for GRAPPA acquisitions.
However, GRAPPA sampling was found to underperform compared to other sampling methods, possibly due to the lack of complementary sampling across echoes. For example, the NMSE was and SSIM was for GRAPPA sampling compared to and for echo - interleaved skipped line sampling
The Bayesian optimisation framework was arriving at (or approximated) the optimum already after few iterations Thus finding a close to optimal rank parameter for a single slice was possible in 75 s, totalling 35 m for the full volume. We included trendlines from a more exhaustive search for visualisation purposes in Figure 7, Figure 9 and Figure 10 to spot trends more easily.
Optimal rank parameters for all subsampling schemes were in similar ranges The optimal loss for joint-reconstruction of our input (slice dimensions with batched channels) was found using echo - interleaved skipping of lines and the rank For comparison, we used the SURE optimisation approach (see the supplementary material) on AC data of the same input, yielding an optimal rank value of
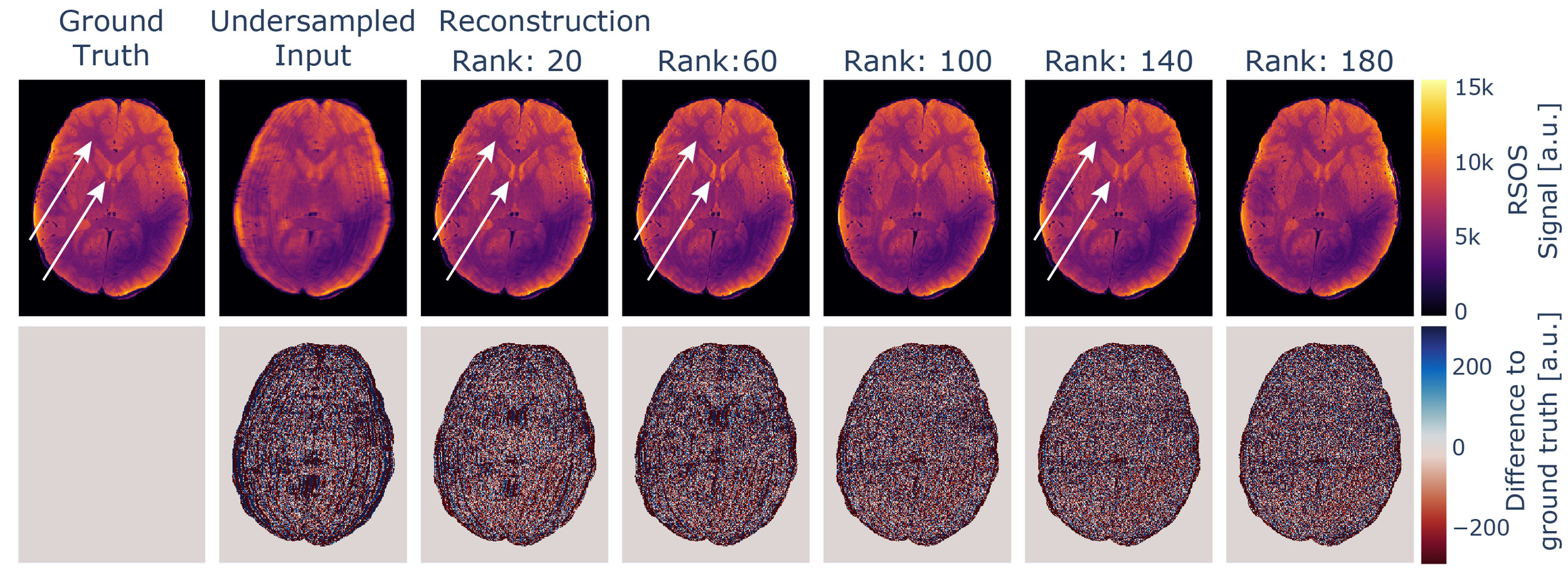
If the rank parameter is selected to be too low, the increase in the loss is accompanied by intensity variations in the reconstructed images not immediately evident if no ground truth for comparison is available. If further processing involves physical modelling of the data, as e.g., in our case the estimation of quantitative values, this will degrade the robustness of the estimates. This influence is depicted in Figure 8 and is presumably caused by mixing of contrasts, as for MESE data, late echoes show a higher dynamic range between white matter and ventricles compared to early echoes, which is visible in the data. The effect might be more subtle and might not disappear the same way as e.g. aliasing artefacts with increased rank settings.
All evaluated metrics, however, approach an asymptotic value below the respective optimum with increasing rank parameter. Thus, using a higher rank parameter does not affect the reconstructed image in the same way. With increasing rank parameter the reconstructed image appears to be more granular, but intensity variation artefacts were absent, as also visible in Figure 8. Thus, we recommend using rather high rank parameter settings.
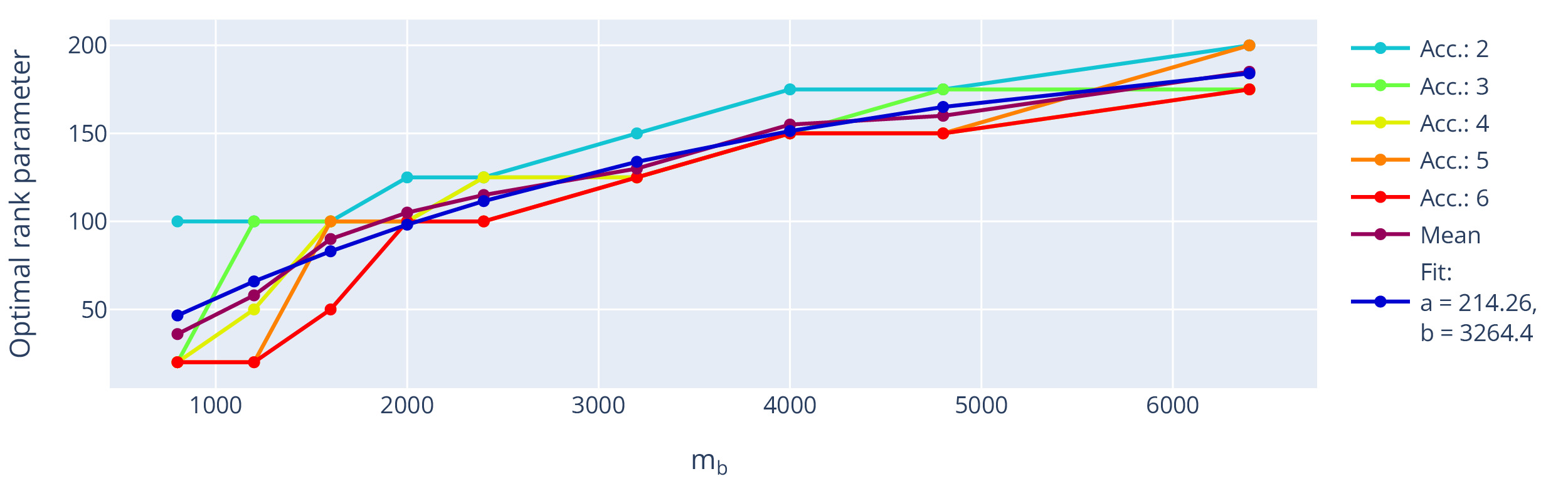
We evaluated the influence of rank, matrix size, and acceleration on reconstruction quality, using the previously found optimal settings regarding the subsampling pattern and The trendlines can be seen in Figure 9. The joint-reconstruction of as many channels and echoes as possible (i.e. high improves reconstruction quality.
The extracted optimal rank using this setting (fixed sampling and using true data consistency) is shown with respect to the number of missing k-space points, i.e. the acceleration, in Figure 10. The optimal rank is dependent on the matrix size but shows little influence on the used acceleration. Assuming the information found in local k-space neighbourhoods is limited, we expect asymptote of the optimal rank parameter.
Fitting an exemplary asymptotic function modelling the trend, e.g., \[f(x) = a (1 - e^{-x/b}),\tag{13}\] to the mean value across used accelerations, the rank parameter would thus approach an optimum at around 214 for big input matrices, which is close to the default settings used in the original multichannel M-LORAKS algorithm.18
If a fully sampled dataset or subset is available or can be acquired for piloting a particular sequence acquisition scheme, the PyLORAKS framework includes the presented optimisation procedures for finding suitable algorithm settings using Bayesian parameter optimisations.74
Sampling Optimisation
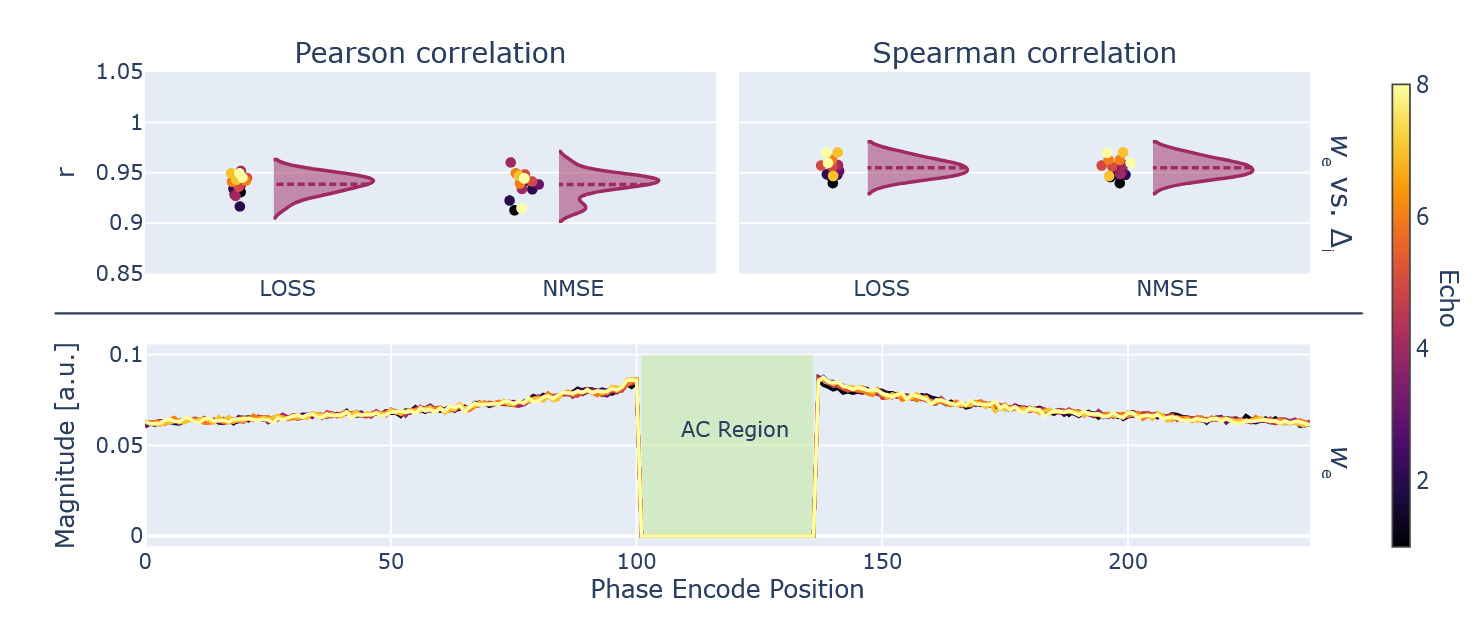
The automated gradient computation through the PyLORAKS algorithm was used for estimation of the sampling densities which are shown in Figure 11.
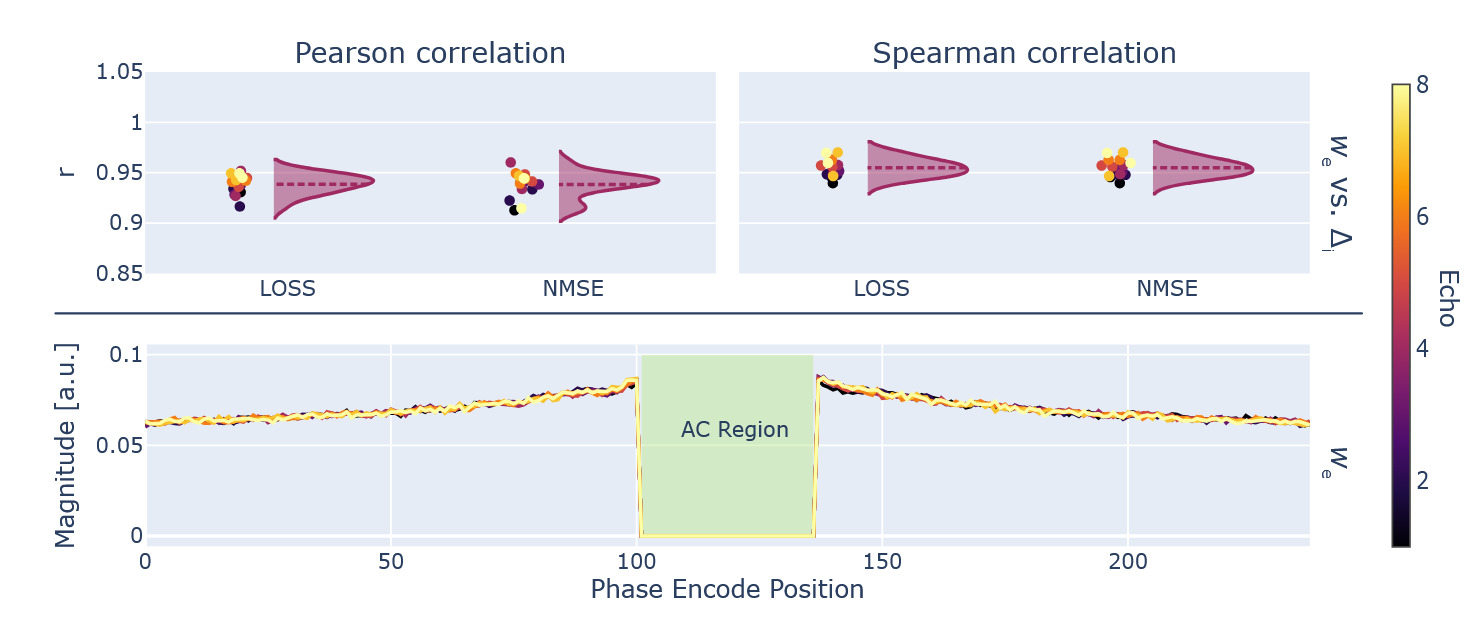
An additional validation experiment was used to find given in Equation 12 using ablation of each respective phase encode line. was computed using and from Equation 7. These measures of sampling importance were correlated to using Pearson and Spearman correlation coefficients. The individual data per echo is given in Figure 11. When using the average, across all available echoes, the following coefficients were computed: Pearson correlation and Spearman correlation for versus and Pearson correlation and Spearman correlation for correlating versus However, a single gradient backpropagation pass through PyLORAKS was achieved in of the computation time.
Using the obtained and an adaptive sampling method78 we created a sampling pattern matching the input dimensions, AC line, and acceleration constraints. The resulting sampling pattern, alongside the ones used for comparison, can be seen in Figure 12, showing sampling variation across echoes for the phase encode direction.
The obtained sampling pattern was tested against the other 2D joint-echo sampling strategies. The resulting reconstructions are exemplified in Figure 13. We evaluated the reconstruction performance, and the respective evaluation metrics are given in Table 3.
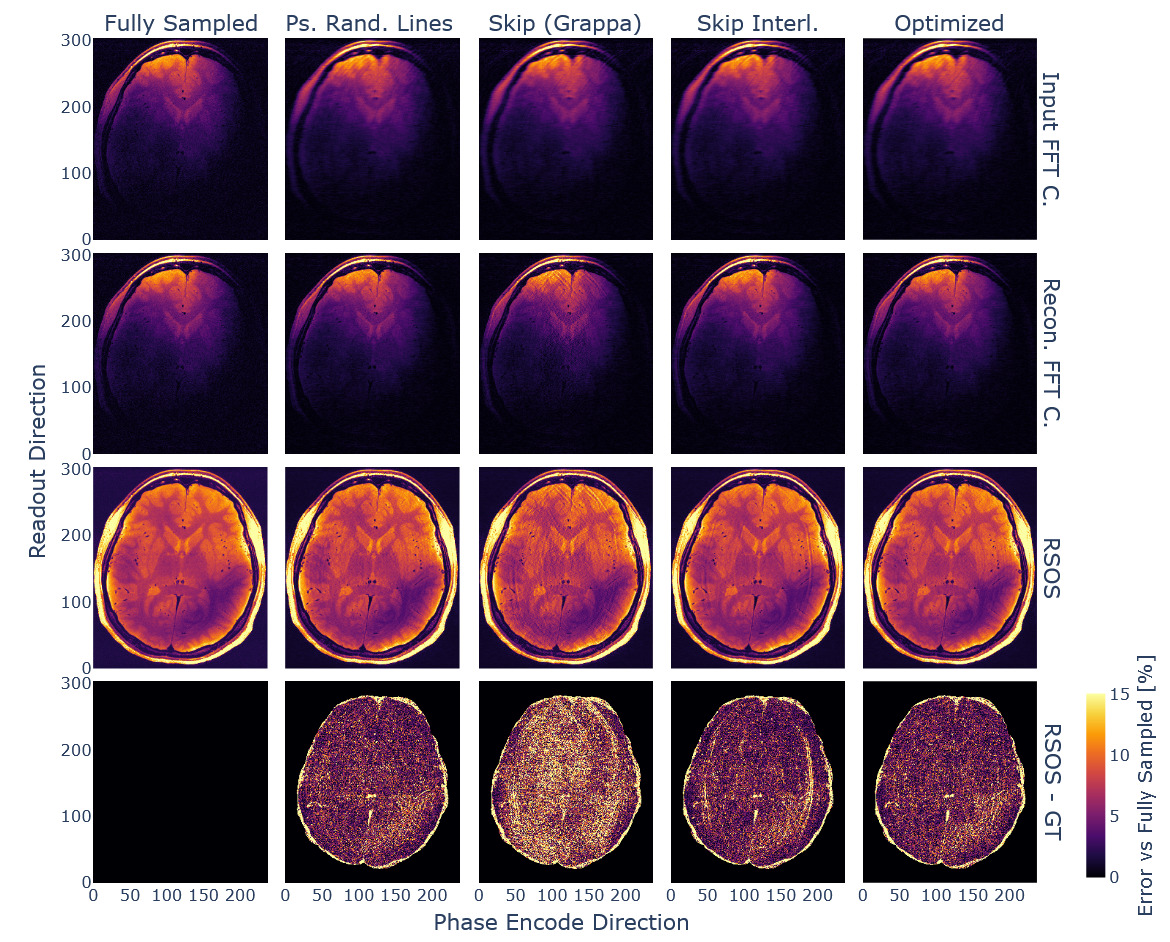
Consequently, the optimised subsampling strategy ensured optimal reconstruction metrics, close to the previously found optimum for the interleaved line skipping method. Noticeably, the latter provided similar overall scores, but the reconstructed images showed residual aliasing artefacts. The obtained sampling density function was similar for all used in vivo datasets.
The strategy allows for data-driven optimisation of the sampling scheme for a given MRI acquisition, which in turn can facilitate enhanced reconstruction results. Alternatively, the gained reconstruction capability can be traded for increased acceleration or resolution. Furthermore, PyLORAKS reconstruction might be considered as a building block for physics-informed AI modelling, due to its capabilities for gradient propagation.79
Discussion
In this study, we introduce PyLORAKS to address the computational demands of low-rank-based joint reconstruction for state-of-the-art MRI datasets. By incorporating efficient parallel CPU and GPU computations, PyLORAKS serves as a fast tool for reconstruction of high-resolution MRI data. Beyond speed, PyLORAKS enables scaling to high-dimensional data by replacing classical matrix decompositions with randomised variants, which will be required for future increases in data size.
We demonstrate the capabilities of our framework by presenting data-driven acquisition optimisations and showing a subsampling optimisation that improves reconstruction quality for multi-echo acquisitions, enabling higher acceleration factors. Furthermore, we present a Bayesian parameter optimisation strategy for evaluating optimal algorithmic parameters that results in increased reconstruction fidelity. We observed improved performance with true-data consistency and note inter-contrast artefacts when the rank parameter was set too low, relative to the LORAKS matrix size. The resulting extensible framework opens up potential, specifically through the implementation of backpropagation. This enables future integration with acquisition and reconstruction optimisation or deep learning-based data modelling.
Hardware limits and speed
Despite substantial speed increases, PyLORAKS (like LORAKS in general) benefits from modern hardware. The largest gains were achieved by using GPUs. Recent high-memory GPU nodes may be unavailable or too costly for certain research settings. Additionally, benchmarks will depend on the CPU/GPU architecture and may vary across different hardware systems.
However, we present data-combination and batching strategies to enable joint reconstruction under tighter hardware constraints. Furthermore, the openly available framework includes deployment guides for HPC/cluster or cloud use, although computational speed gains may be offset by data-transfer overhead.
In any case, PyLORAKS accelerates computations for CPU units as well. Emerging sparsity-exploiting frameworks for efficient memory handling and computation80 may further reduce computational demands in the future.
Fast SVD methods
Randomised SVD algorithms reduce memory and time for processing of large LORAKS matrices and computational demands are tailored by target rank and oversampling. Thus, explicit control of the memory footprint with respect to hardware limits is possible, but a dedicated optimisation of the influence on the reconstruction was beyond the scope of this work.
For example, introducing randomised SVD methods will be much more efficient for P-LORAKS as the LORAKS constraint is enforced with a low-rank approximation of the LORAKS matrix, allowing for big data compression within the matrix decomposition method since On the other hand, with the AC-LORAKS framework presented here, the rank enforcement is done by approximating the nullspace of the LORAKS matrix formed by AC data. This nullspace is of dimensionality and an effective compression using randomised SVD variants has little computational benefit for small Therefore, we decided to use a different approximation of the nullspace by computing the leading eigenvectors of the nullspace by the randomised SVD method. Further increase in computational efficiency might be possible by further reduction of this dimensionality, and effective memory control is possible by adjusting to the available hardware.
Scalability and 3D acquisitions
Given the computational efficiency improvements achieved with PyLORAKS, we demonstrated effective joint-reconstruction of modern high-resolution data. However, we limited the study to slice-wise reconstruction most suited for 2D sequences. While 3D sequences can be reconstructed in this fashion (e.g. by formation of a hybrid space with the Fourier-transformed readout direction taken as the iterative dimension), 3D subsampling might benefit from extending the LORAKS neighbourhood to a 3D volume as previously suggested.3,18 However, the scaling implications are beyond what has been investigated within the scope of this study. Not only does the neighbourhood size contribute with the power of its dimensionality to the LORAKS matrix size also the larger matrix dimension scales linearly with an added dimension. This counterbalances the improvements presented in our study and might be prohibited by memory limits in a joint-reconstruction setting and high-resolution data. We suggest using the PyLORAKS framework in iterative fashion across 2D slices to achieve the presented advantages. However, further exploitation of the use of randomised matrix decomposition methods enable higher dimensional data processing, as well as future hardware advancement possibly allows for joint-LORAKS 3D reconstruction of high-resolution data using PyLORAKS.
Noise
One aspect of joint-echo reconstruction and LORAKS reconstruction in general is its effect on imaging noise not studied in the presented research. LORAKS has previously been shown to have denoising effects, which are additionally related to specific image structures.3 The resulting spatially dependent noise reduction or amplification possibly extends across contrasts in a joint-reconstruction and, to the authors’ knowledge, has not yet been thoroughly investigated. Due to the nature of randomised SVD methods, using random sampling of the LORAKS matrix to facilitate data compression, additional effects on imaging noise are likely. In our presented PyLORAKS framework focus was placed on reconstruction of individual channel and contrast data respectively, allowing for a more straight forward investigation of noise influence compared to e.g. channel compression approaches, but is left to future research efforts.
Evaluation of algorithm parameters
The presented methods for data-driven evaluation of algorithm parameters revealed joint-reconstruction pitfalls that are applicable to other data, such as the mixing of contrast information when using too aggressive rank settings. Results such as the optimality of true data consistency or specific rank parameters may not generalise to all acquisition modalities, but the presented methods can be used to tailor the algorithm parameter settings to the specific acquisition method. Furthermore, if fully sampled data can not be acquired for reference, optimisations with respect to the parameter choice are possible using a target reconstruction. The applicability of our results to other imaging data remains to be demonstrated. Nonetheless, the usage of PyLORAKS as a drop-in replacement within reconstruction optimisations like A-LORAKS-CS24 to increase computational performance opens up other pathways to data-driven parameter selection beyond the presented method. However, presenting generalisable optimal LORAKS settings remains a challenging task.
Automatic differentiation and backpropagation
We demonstrate automatic gradient computation for backpropagation through the PyLORAKS algorithm, enabling input or condition optimisation. However, great efforts were previously invested into enhancing the LORAKS framework.18 The least-squares solver mechanism is a fast and efficient method, especially in conjunction with CGD approaches, and thus has been proven to be quicker than the gradient descent used with backpropagation. This is mainly due to the update rate being unknown a priori, which is the case for most machine-learning approaches using the same PyTorch mechanism. Thus, similar loss optimisation efforts in conjunction with backpropagation might be used, for example, adopting stochastic optimisation like Adam.81 Additionally, computation of an optimal or adaptive step size is part of recent AI - research82–84 and emerging results might be applicable to the PyLORAKS framework.
Subsampling optimisations
The automatic differentiation feature was used for end-to-end optimisation of the sampling pattern of a multi-echo acquisition, which provided an increase in reconstruction quality transferable to increased acquisition acceleration. Due to the stochastic sampling approach, the optimisation for other acceleration factors is implemented quickly. We found the obtained sampling densities to be similar across participants, and thus to be valid across equal acquisitions. However, due to the limited number of subjects, generalisation to other acquisitions or changes in acquisition parameters (such as or FOV) warranting re-computation need to be further analysed in future research. In principle, the automatic differentiation framework can be used to compute a deterministic mask with additional improvements beyond the scope of this work. Furthermore, the processing relied on the availability of fully sampled data for at least parts of the FOV. To circumvent this for cases where this is not available or hard to obtain, a target reconstruction can be used instead. In any case, PyLORAKS can be suitable for integration in existing sampling optimisation frameworks like OEDIPUS69 and thus allows for a plethora of sampling optimisation options.
Assessment
We used a number of metrics for assessment of the reconstruction quality and the optimisation procedures. Each metric (NMSE, PSNR, SSIM) has specific advantages and limitations; we consider SSIM most suitable for perceptual image quality assessment. Nonetheless, the used images have a high resolution, and reduction of image content into one quantitative metric has its drawbacks. For example, the second-best sampling pattern (based on metrics) showed notable aliasing artefacts compared to others. Thus, visual inspection of the data is still necessary, should always be carried out, and future improvements in image evaluation quantification are needed.
Conclusion
We present PyLORAKS, a fast and computationally efficient implementation of the LORAKS reconstruction approach, particularly for large MRI datasets. We incorporated joint-contrast reconstruction and optimised code to achieve high computational efficiency and a speed increase of around 5–6-fold compared to the original MATLAB implementation. Additionally, GPU parallelisation further accelerates single-slice joint reconstruction by up to 30-fold. The estimated increase in computation time scales with the number of slices, drastically reducing reconstruction time of whole volume multichannel multi-contrast data. We leverage these computational gains to enable Bayesian sampling-based optimisation of the algorithm’s main parameters for regularisation and low-rank completion and which previously were chosen manually after visual inspection. We found a performance increase with the use of the LORAKS true-data consistency formulation and demonstrated bleeding artefacts between contrasts if the rank parameter is chosen too low compared to the LORAKS matrix size. Furthermore, we introduced automatic backpropagation, enabling data-driven optimisations and physics-informed AI-modelling. We demonstrated its capabilities in the design of an optimised subsampling scheme, which can be used to increase acquisition acceleration. PyLORAKS is openly available, including containerised environments for deployment large-scale compute clusters.
Data and Code Availability
The software used in this study is available on GitHub at https://github.com/schmidt-jo/PyMRItools.55 This includes the LORAKS reconstruction framework for the AC and P-LORAKS algorithms, the S and C LORAKS matrix formulations, and the different solvers using CGD and automatic gradient descent mentioned in this paper. Additionally, a collection of tools and scripts to demonstrate the experiments used is included, and a guide for setting up containerised environments for high-performance compute cluster utilisation is provided.
The code repository contains phantom data that allows reproduction of the experiments. The presented subject data contains sensitive patient information and is subject to European GDPR regulations. It is thus only available upon request and with a formal data sharing agreement.
Author Contributions
Jochen Schmidt: conceptualisation, data curation, formal analysis, investigation, methodology, project administration, software, visualisation, writing—original draft. Patrick Scheibe: conceptualisation, data curation, methodology, software, writing–review and editing. David Carreto Fidalgo: data curation, software. Andreas Marek: data curation, software, resources. Robert Trampel: conceptualisation, supervision, writing—review and editing. Nikolaus Weiskopf: conceptualisation, funding acquisition, resources, supervision, writing—review and editing.
Funding Sources
This project has received funding from the German Federal Ministry of Education and Research (BMBF) under support code 01ED2210. Furthermore, this work was supported by the Max Planck Society for the Advancement of Science, Germany.
Conflicts of Interest
The Max Planck Institute for Human Cognitive and Brain Sciences and Wellcome Centre for Human Neuroimaging have institutional research agreements with Siemens Healthcare. Nikolaus Weiskopf holds a patent on acquisition of MRI data during spoiler gradients (US 10,401,453 B2). Nikolaus Weiskopf was a speaker at an event organised by Siemens Healthcare and was reimbursed for the travel expenses.
Acknowledgments
First and foremost, we are deeply indebted to Justin P. Haldar for our discussions and the exchange about our ideas and encountered problems, to which he always responded with great patience and remarkable detail. His expertise has been invaluable, and this work would not have been possible without his guidance.
We also appreciate the support given by the Max Planck Computing and Data Facility for their help in implementing the software for AMD architectures and running our experiments at scale.
We thank Valerij Kiselev for his input on random matrix theory. We are grateful to Barbara Dymerska for the exchange and her shared insights into the user experience of LORAKS. Given the early stage of PyLORAKS, we are especially thankful to Tiago José Timóteo Fernandes for the extensive testing, which highlighted the importance of hardware constraint estimation.
Lastly, we extend our special thanks to all the MTAs at the Max Planck Institute for Human Cognition and Brain Sciences involved in scanning participants.