
To the authors of this perspective piece, the 2025 Organization for Human Brain Mapping (OHBM) Annual Meeting was notable for the ease with which the term generative model circulated — often appearing without explanation, and as though its meaning were self-evident. In the educational course on neural field theory, generative models appeared as mechanistic, biophysical descriptions of neuronal dynamics. In keynote talks and symposia, the same term was used to describe (generic) general linear models (GLMs), and black-box artificial intelligence systems. Elsewhere, in a roundtable celebrating the thirtieth anniversary of the Statistical Parametric Mapping (SPM) toolbox, “generative modeling” was described as the defining feature that distinguished SPM from other neuroimaging software[1].
What caught our attention was not just the breadth of these uses, but the tension between them. Generative models seemed, at once, to be something very general — almost a synonym for “model” — and something highly specific, even privileged. They were common, yet they were also invoked as a mark of conceptual or methodological distinction. This apparent contradiction led us to ask colleagues, informally (over coffee), what they understood the term to mean. Several of these conversations ended with the same suggestion: that we should survey the community in a more formal manner[2].
It is worth briefly noting that other researchers have remarked on the ambiguity surrounding this term,1 and that — without attempting a sociolinguistic analysis — this ambiguity appears to reflect a gradual drift in usage across disciplines. In machine learning, the term was associated with early work on Boltzmann machines and related probabilistic models,2,3 though it appears earlier still in linguistics, where it referred to rule-based formalisms for producing well-formed linguistic structures.4 In Bayesian statistics, the term came to denote the specification of a joint probability distribution over observed data and latent variables, with priors encoding assumptions about the data-generating process.5,6 In parallel, influential work in computational neuroscience framed perception itself as a process of inference over latent causes of sensory input.7 Subsequently, the term became associated with mechanistic and biophysical models — models in which states are intended to correspond, at least approximately, to known biological processes that give rise to measured signals, regardless of whether those models are cast in explicitly Bayesian terms.8,9 More recently, with the increased visibility and use of large language models, the same term may now be more often understood to refer to artificial intelligence systems that produce text and other content.10
This is all to say that, from certain perspectives, a model may be considered generative not because it generates realistic synthetic data, but because it supports inference about latent causes or parameters assumed to have generated certain features of observed data. In neuroimaging, this can mean specifying how unobserved neuronal states, network interactions, or coupling weights give rise to second-order features of neural signals (correlations, for example) well enough to estimate those quantities, with realistic time-domain simulation not serving as the primary basis for evaluation.11–13 Although a diversity of perspectives is not surprising, it raises the possibility that researchers may be talking past one another using the same words to refer to models that differ fundamentally in their aims, assumptions, and standards of evaluation. To move beyond anecdote and to characterize how these different understandings are distributed in practice, we conducted a short survey of the OHBM community, combining open-ended and structured questions about how generative models are defined, used, and evaluated. In what follows, we summarize the results of this survey and reflect on what they reveal about shared intuitions and points of divergence within the field, before offering a pragmatic working definition and minimal reporting recommendations.
Results
Our survey comprised 14 questions in total, including a mixture of free-text responses, multiple-choice items, and rank-ordering questions (see Supplementary Material). The survey was circulated via the OHBM mailing list and remained open for 2 weeks, with participation entirely voluntary; respondents were free to skip any question. For the exploratory, descriptive analyses reported here, we focused on respondents who completed at least 5% of the survey, yielding a final sample of 88 respondents; full methodological details are provided in the Supplementary Material.
For readability, percentages are rounded to the nearest whole number throughout this section (exact values can be obtained via the accompanying analysis code). Of those respondents who provided demographic information, 45% identified as principal investigators or group leaders, 23% as postdoctoral researchers, and 21% as doctoral students, with smaller proportions reporting roles such as research staff, clinicians, or other positions. Reported ages ranged from 25–34 years to 65 years or older, with the largest proportion of respondents (41%) falling within the 25–34-year age group. Among respondents who reported gender, 59% identified as men and 33% as women, with 8% preferring not to disclose. Respondents who provided location information were based across 15 countries, most commonly the United States (29%) and Australia (26%), followed by the United Kingdom (9%), Germany (6%), and Italy (6%), with additional representation from Canada, South Korea, India, Belgium, Switzerland, France, Finland, and Singapore.
In terms of primary research area, respondents most frequently reported working in magnetic resonance imaging (MRI) (44%) and methods development or computational modeling (22%), followed by multimodal imaging (13%) and electroencephalography (9%), with smaller representations from clinical and translational neuroscience, positron emission tomography, and magnetoencephalography. When asked how generative models are used in their own work (multiple selections permitted), respondents most frequently reported applications in mechanistic or biophysical modeling (49%) and whole-brain dynamical modeling (42%). Substantial proportions also reported using generative models for synthetic data generation or augmentation (37%) and clinical prediction or stratification (35%). Less frequently reported uses included encoding or decoding models (31%), normative modeling or deviation mapping (24%), and simulation-based or likelihood-free inference (10%). Taken together, these characteristics suggest that the survey captured a reasonably broad snapshot of the OHBM community.
How do researchers define a “generative model”?
We conducted a thematic analysis of responses to the open-ended question “In one or two sentences: what is a generative model, in your own words?”, drawing on established qualitative methods.14 These free-text responses were inductively coded, codes were iteratively refined, and higher-level themes were identified through grouping of related codes (see Supplementary Material). Responses clustered into five themes, defining generative models as: (i) mechanistic or biophysical forward models, in which latent physiological states are mapped to observed data; (ii) probabilistic or Bayesian latent-variable models, specified via joint distributions over hidden causes and observations; (iii) models defined by their capacity to simulate data, irrespective of underlying mechanism; (iv) content-producing artificial intelligence systems, such as large language or image-generation models; and (v) hybrid or mixed definitions combining elements of multiple perspectives. This diversity was also reflected in responses to the multiple-choice question “Which definition best matches your use of generative model?” (Figure 1a). The most commonly endorsed definition — “any model that can produce synthetic data, by any method (mechanistic, probabilistic, or machine learning based)” — placed particular weight on a model’s capacity to simulate data. In line with this emphasis, most respondents (66%) indicated that an explicit likelihood was not required for a model to count as generative, and most respondents (59%) indicated that models unable to generate raw data — operating only at the level of summary statistics — would not be considered generative.
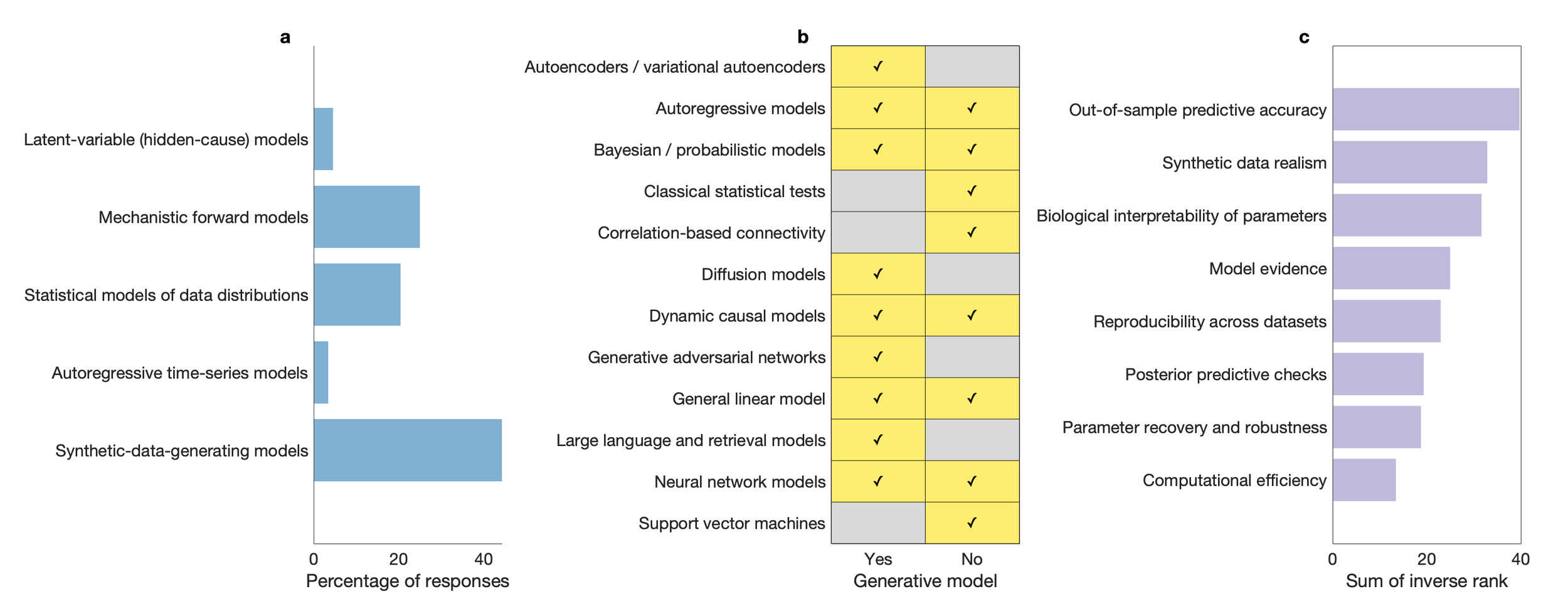
Despite this seeming convergence and liberality, responses to a question asking participants to name one model they considered generative and one they considered not generative revealed substantial disagreement. Many of the same approaches were cited on both sides of the generative–non-generative divide by different respondents (Figure 1b). For example, dynamic causal models, autoregressive models, and the GLM were each described as generative by some participants and explicitly non-generative by others. These disagreements were typically justified by reference to different evaluative criteria, including whether a model specifies an explicit forward process, whether it can generate raw data, and whether its parameters are interpreted as causal or mechanistic. In contrast, contemporary machine-learning systems such as generative adversarial networks and large language models were more consistently described as generative, while purely discriminative or descriptive models were more often cited as non-generative.
What do researchers consider evidence of a “good” generative model?
We conducted a thematic analysis of responses to the open-ended question “What is one best practice you would recommend to others when evaluating generative models?”. Responses clustered into six themes, emphasizing: (i) generalization and out-of-sample validation, including the use of independent datasets and safeguards against data leakage; (ii) interpretability and biological plausibility, particularly the meaningfulness and identifiability of model parameters; (iii) simulation realism and failure modes, including stress-testing models and examining when they break down; (iv) model comparison and falsifiability, through the use of alternative models, null models, or formal comparison criteria; (v) appropriateness of assumptions, including parsimony and alignment between model, data, and research question; and (vi) explicit resistance to codified best practices, reflecting concerns that prescriptive standards may constrain innovation or obscure context-specific goals. When asked to rank evidence for a “good” generative model, respondents placed the greatest weight on out-of-sample predictive accuracy and generalization, followed by a model’s ability to generate realistic synthetic data and the biological interpretability of its parameters (Figure 1c).
What do researchers consider to be misused terminology?
To assess whether ambiguity surrounding generative models reflects a broader issue of terminology in neuroimaging, we examined responses to the question asking participants to identify commonly misused modeling terms and to clarify how they would define them. Responses highlighted concerns about the use of language that implies mechanistic or biological realism without sufficient justification, the tendency to treat formal statistical criteria as guarantees of scientific validity, and the conflation of prediction, explanation, and interpretation. Several respondents also expressed unease with uncritical adoption of machine-learning terminology in neuroimaging contexts.
Discussion
The aim of this perspective was deliberately modest. We set out to document how generative models are currently understood, used, and evaluated within the human neuroimaging community. Prompted by informal conversations at the 2025 OHBM Annual Meeting, we conducted a short survey combining open-ended and structured questions. Our key finding is that, while definitions of what constitutes a generative model varied widely across respondents, judgments about how such models should be evaluated tended to converge. While other authors have remarked on disagreements surrounding modeling concepts and terminology,15–19 to our knowledge this is the first attempt to survey how a single, widely used term is interpreted within neuroimaging.
On the surface, respondents appeared to agree on broad criteria for what counts as a generative model — most commonly, the capacity to simulate data (Figure 1a). Yet agreement was less apparent when participants were asked to classify specific methods: the same models were repeatedly placed on opposite sides of the generative–non-generative divide (Figure 1b). In some cases, these disagreements appeared to reflect differences in context of use. A GLM, for example, might be considered a mechanistic model when used to map known experimental inputs — convolved with a hemodynamic response function — onto functional MRI data,20,21 whereas in other settings it may simply be used as an ordinary least-squares tool for relating observed variables, without much commitment to how those relationships should be understood.22 Despite divergent definitions, when it came to evaluative criteria respondents largely converged on the importance of out-of-sample generalization, simulation realism, and interpretability, while placing less weight on formal criteria such as model evidence or computational efficiency (Figure 1c). Agreement, where it existed, tended to concern what models should do, rather than what they should be called.
The final set of responses helps to place these findings in a broader context. When asked about commonly misused terminology, participants pointed to similar problems elsewhere in the field: language that implies mechanistic or biological realism without sufficient justification, and persistent confusion between prediction, explanation, and interpretation (for example). If there is one practical lesson to draw from this survey, it is that clarity is a minimal requirement: when using the term generative model (and indeed, any other ambiguous term), researchers should state explicitly what they mean by it in context.
Before closing this section, it is worth noting that the disagreements captured by the survey were not entirely dispassionate. The tone of many free-text responses was striking. Some respondents treated their views as self-evident; others resisted the premise that generative modeling requires definition at all; others openly described confusion. Taken together, these reactions suggest that ambiguity around generative models is not merely a technical problem, but one bound up with disciplinary identity and assumptions about what should go without saying. Against that backdrop, we offer a pragmatic working definition and a minimal set of reporting items — not to enforce consensus, but to make disagreements explicit and easier to evaluate.
Working definition and initial recommendations
One thing is clear: we cannot define the term generative model in a way that satisfies all the views we have documented. If one insists that a generative model must generate raw data (rather than summary statistics) and encode biophysical mechanisms, we risk excluding models that many researchers regard as paradigmatic — models evaluated via prediction of second-order data features,11–13 for instance, and general-purpose conditional generators trained to produce realistic samples.23,24 At the same time, the view — commonly held, as we have shown — that an explicit likelihood is not required does not remove what we take to be a basic requirement: a generative model must specify a source of variability so that it can produce sampled realizations of data under stated parameter, latent-state, or prior settings.
Thus, we propose that the term generative model should refer to a model that specifies a forward data-generating scheme linking latent variables and parameters to neuroimaging observations (or derived targets), whether that scheme is written as an explicit likelihood or implemented as an explicit sampling procedure. Of course, the point is not simulation for its own sake. In many neuroscientific applications the forward scheme is introduced to support inversion — inference on latent quantities from data. In other applications, including modern sampler-based artificial intelligence systems (generative adversarial networks or diffusion-based models, for example), the forward scheme is learned as a sampler and is used primarily for conditional generation or prediction, with applications such as imputation, forecasting, and assessing responses to perturbations of conditioning inputs. Both can be seen as falling under the same umbrella. What matters is that the model states what is stochastic (where variability enters) and how model-consistent samples are produced under stated settings. By contrast, purely descriptive associations or discriminative mappings (reporting correlations or decoding observed features into labels, for example) may be useful, but are not generative under this definition unless embedded in a forward data-generating scheme.
Again, this is a pragmatic (broad) definition, and precisely because it spans mechanistic forward models used for inference and learned samplers used for prediction, differences in modelling ambition should be stated, not assumed. If authors choose to describe a model as generative, we recommend following a minimal set of reporting commitments (Box 1). Questions of evaluation — what counts as a strong test of a generative claim, and how to align checks with aims, for example — are substantial, and will be the focus of future work. Here, we simply hope to have gone some way toward making it harder for different models — and different goals and standards of evidence — to pass under the same name unnoticed.
Data and code availability
The survey data analyzed in this study have been de-identified and include only revised codes and thematic variables, with no free-text responses, initial coding labels, or direct identifiers retained. The processed dataset and all analysis code are publicly available at https://github.com/mdgreaves/ohbm-generative-models-survey, and are archived at Zenodo: https://doi.org/10.5281/zenodo.18238047, enabling reproducibility of the reported results.
Funding sources
M.D.G. was supported by an Australian Government Research Training Program Scholarship. M.D.G., L.N. and A.R. were funded by the Australian Research Council (ref. DP200100757). M.B. acknowledges the facilities and scientific and technical assistance of the National Imaging Facility (NIF), a National Collaborative Research Infrastructure Strategy (NCRIS) capability, at the Hunter Medical Research Institute Imaging Center, University of Newcastle. A.R. was funded by Australian National Health and Medical Research Council Investigator Grant (ref. 1194910) and Australian Research Council Future Fellowship (FT250100563). A.R. was affiliated with The Wellcome Centre for Human Neuroimaging supported by core funding from Wellcome (203147/Z/16/Z). A.R. is a CIFAR Azrieli Global Scholar in the Brain, Mind & Consciousness Programme.
Conflict of interest
Authors declare that they have no competing interests.
These observations are necessarily impressionistic, as not all talks were archived. However, all accepted abstracts from OHBM 2025 were deposited on Zenodo,25 and a term search of this corpus returns multiple instances of “generative model” and related phrases, consistent with the breadth of usage described here.
We are particularly grateful to Joseph Lizier for encouraging us to formalize these discussions and to survey the broader community.