Introduction
As recording devices, task designs and analyses become more complex, there is a need for scientific investigations to adopt systematic protocols for managing the collection, curation, organization, and storage of data which can support the application of robust and replicable analyses. In addition, ongoing work seeks to develop approaches for sharing datasets to allow for re-analyses and integration into other projects,1,2 as well as to ensure that analysis code is robustly developed and shareable,3–5 in order to support open materials that can contribute to the transparency and reliability of datasets and analyses and which can be made available for future investigations. Collectively, these goals have led to the development of numerous resources, including protocols, data standards, and open-source software tools for managing and analyzing neuroscientific data of various modalities.
Approaches for managing research projects need to be appropriately designed to meet the needs and specificities of the data under study and the analyses to be undertaken. While common recording modalities such as human neuroimaging have large user-bases that have collectively developed community standards, for example, the Brain Imaging Data Structure for standardized data organization6,7 and general-purpose analysis tools such as FreeSurfer8 and FSL,9 other less common recording modalities have had less development of tools for standardized data management and analysis. One such recording modality with a relative lack of available tools and resources for standardization are human single-neuron recordings, a relatively rare and valuable approach in which single-neuron recordings can be recorded from awake, behaving human patients and used to examine questions in cognitive and clinical neuroscience.
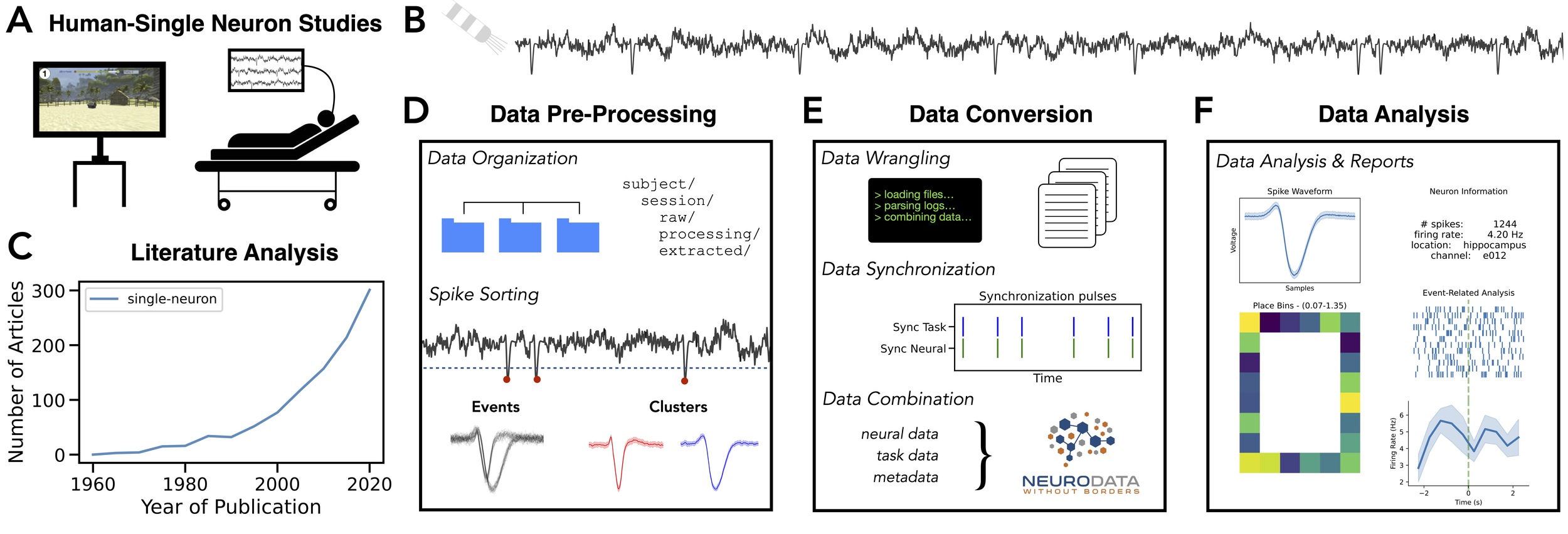
Human single-neuron recordings are available in situations in which electrodes capable of detecting the activity of individual neurons are implanted in patients undergoing intracranial recordings for clinical purposes, for example, for epilepsy monitoring (Figure 1AB).10,11 While examples of recording human single-neurons date back to the early days of developing invasive clinical recordings from patients,12,13 more recent developments of specialized electrodes and associated advances for implanting and recording from such electrodes as well as an increase in the number of clinical centers and research labs pursuing this work has led to an expansion of this field of research (Figure 1C). This work has contributed many notable scientific advances, including on topics such as semantic memory,14,15 episodic memory,16,17 spatial navigation,18,19 and high-level visual representations20,21 in the field of cognitive neuroscience, as well as contributions in clinical neuroscience.22–24 Notably, the study of single-neuron activity in humans allows for many unique research opportunities that are difficult in animal models, for example, studying language,25 visual imagery,26 subjective visual experience,27 conceptual representations,28 representations of others beliefs,29 and volitional movements.30
Human single-neuron recordings have a set of practical considerations that motivate the development of curated procedures and standards. To this end, there are guides for electrode implantation and data collection using microwires from which single-neuron activity can be isolated,10,11 as well as descriptions of other electrode types that have recently been trialed, including tetrodes31 and NeuroPixels.32,33 Human single-neuron recordings are a subset of intracranial human recordings, for which there are associated guides for collecting such data.34,35 While these resources focus on data collection, there is thus far not, to our knowledge, any available resources for managing human single-neuron data and analysis pipelines. Human single-neuron research is therefore a paradigm for which there is much potential upshot to developing and employing standardized procedures and data standards to support efficient, robust, reliable, and shareable research projects.
In proposing materials for managing human single-neuron projects, any such proposal must reflect the complexity and idiosyncrasies of human single-neuron projects. Since such projects often including multiple sites, data collection and analysis must be flexible to variations across patients and hospitals, including differences in recording devices, noise sources, electrode locations, task engagement and performance, and clinical schedules as well as managing idiosyncratic events that can happen in hospital settings. Similarly, pre-processing and data analysis work may also be split across people and locations, including with varying in-house processing approaches, analysis goals, programming languages, etc., that may later need to be integrated. Collectively, these considerations motivate both the challenges and potential utility of developing a standardized pipeline for the study of human single-neuron activity – the increased shareability, interoperability, and transparency of shared procedures and data standards can assist with sharing data and analyses within and between teams and projects, as long as such procedures are sufficiently flexible and modular to support the variability and idiosyncrasies within and between single-neuron projects.
To address this need, we here describe the Human Single-Neuron Pipeline, a resource for assisting with managing, organizing, and analyzing human single-neuron activity, including template structures for managing pre-processing, data organization, and analyses of such data, as well as the adoption of a standardized data format. The goal is both to provide a structured guide for pursuing human single-neuron projects and in doing so to facilitate open-science practices – once a project is complete, sharing the standardized data files and organized analysis code allows for others to reproduce the analyses of a project as well as to further explore the data. In curating a flexible pipeline for use with human single-neuron projects, this project seeks to provide a resource that can be productively employed to provide productive standardization across studies, addressing the need to evaluate and integrate tools to ensure that they work together and meet the needs of the data under study. This means supporting notable features of human single-neurons, for example distributed data collection and their specific processing requirements, in order to provide structured approaches for pre-processing, organizing, storing, and analyzing data that work together to provide efficient and effective project management. By doing so with the combination of existing tools from across the ecosystem that are robustly developed and increase interoperability combined with novel tools and templates that are all evaluated to work together, this pipeline provides a novel resource to increase the efficiency of project management, the shareability of datasets, and the robustness of analyses in order to effectively leverage the scientific utility of human single-neuron recordings.
**_human_patients_with_implanted_electrodes_f.jpg)
Methods & Results
The pipeline is designed to support research designs in which single-neuron activity is recorded from human neurosurgical patients. For example, human single-neuron data can be collected from epilepsy patients who are candidates for surgical intervention and therefore have electrodes implanted for the clinical purpose of localizing epileptogenic regions for potential resection. In hospitals engaged in this kind of research, patients may be asked if they would like to consent to be involved in research with single-neuron recordings and if so, they are implanted with electrodes capable of doing so. The data from these electrodes, such as microwires that extend beyond the tip of clinical macro-electrodes, are the primary neurophysiological data of interest. In the case of epilepsy, patients in the epilepsy monitoring unit (EMU) are asked to complete behavioral tasks, which are usually presented on a laptop, and may include visual and/or auditory stimuli, virtual navigation, memory tasks, etc. These tasks generate behavioral data, typically including information about the operation of the task (such as condition information, trial structure, etc.) as well as responses from the patient through clicks or key taps and/or through other streams such as audio recordings, which then need to be aligned with and compared to the neural recordings. Other research designs that may include single-neuron recordings include intraoperative studies, in which recordings are taken during surgery (e.g., during surgical resection of epileptogenic regions) or during the implantation of deep-brain stimulation (DBS) devices. Human single-neuron research projects may also include other measurements, such as additional physiological or behavioral measures, and associated data such as anatomical recordings.
As with other human intracranial research designs, human single-neuron data for a particular experiment is often collected across multiple hospitals, including variations in the recording devices, amplifiers, file types, and pre-processing steps. It then requires specific procedures for pre-processing and analyses. While some of these aspects are shared with other human intracranial EEG (iEEG) work, the specifics of the single-neuron elements differ from projects analyzing the local field potential (LFP) from clinical macro electrodes. While some aspects of human single-neuron projects also overlap with animal model electrophysiology, the clinical context as well as differences in the recording equipment and task design means that processes and tooling can also differ significantly from what is required in single-neuron recordings from animal models. Ultimately, human single-neuron projects require an idiosyncratic set of approaches that overlap with both other human intracranial research and invasive animal electrophysiology, but which also entail unique considerations that differ from both. To address these needs, this pipeline implements a series of standardized workflows that can be used specifically for human single-neuron data.
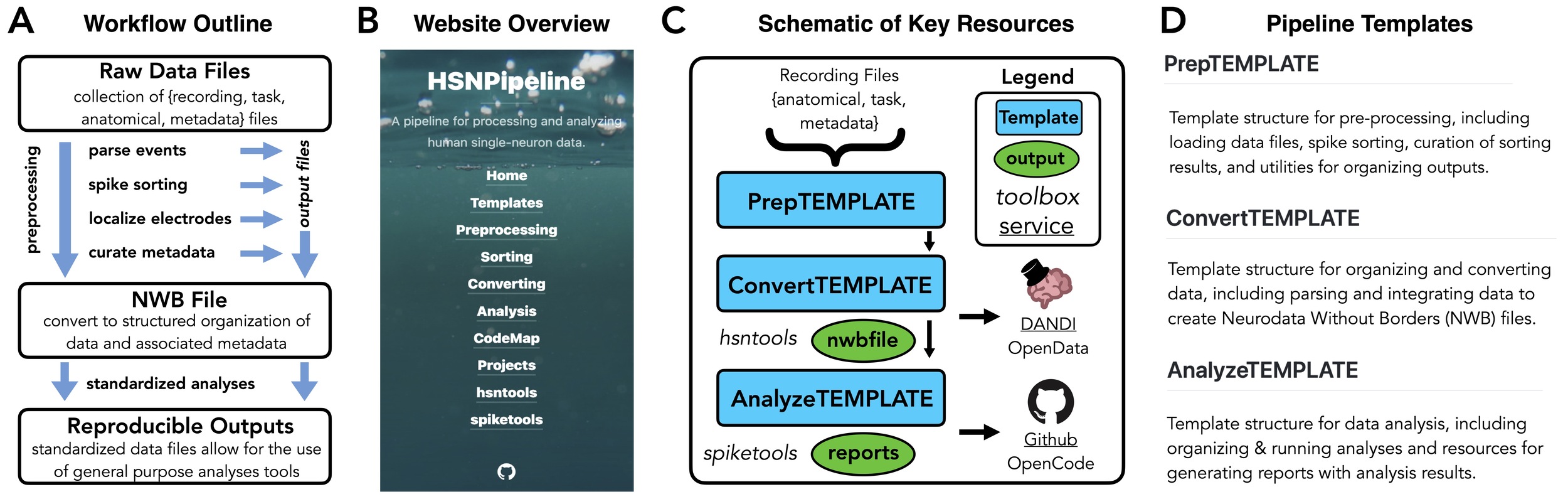
Acknowledging the overlap with other recording modalities, the goal of this pipeline is to productively integrate available tooling and resources to meet the needs of human single-neuron projects. Accordingly, this pipeline generally does not reflect new tools or standards – there is no new data format or general-purpose software package proposed and introduced. Benefits of not requiring novel or bespoke elements include increased inter-operability with existing tools and resources, and less development burden required to maintain novel resources. The pipeline is also designed to be modular, such that a project may adopt templates and outlines for one aspect of the project, without needing to adopt the whole pipeline. In doing so, the pipeline also provides an outline for managing human single-neuron projects that is implementation agnostic, in the sense that the organizational structure, data standard, and general recommendations do not require any particular programming language or specific tools. In practice, the associated code for the pipeline is developed in the Python programming language. As part of its modular design, the pipeline is organized into three sections: pre-processing, including applying spike sorting to the raw recordings; data conversion, with the goal of combining different data streams into standardized data files; and analysis, providing template structures and related tooling for robust and reproducible analyses.
To support and enact the pipeline, this project includes code, documentation, and templates that implement needed functionality and provide guidelines for human single-neuron projects. Each section of the template is available as an individual Github repository with key materials, supported by dedicated documentation, such that any project seeking to use the project can simply take a copy of the repository and start using it. All code and resources developed for this pipeline are licensed with permissive open-source licenses for reuse. A key part of the template cutting across sections is the hsntools module, which is an open-source Python module that is documented, version-controlled, and tested, which provides a collection of utilities for working with the pipeline (documentation: https://hsnpipeline.github.io/hsntools/). This includes functionality including managing data files and objects, applying spike sorting processes, aligning multiple data streams, creating standardized outputs, and managing analyses of output files. In doing so, this module prioritizes the use of existing tools over novel solutions and implementations, connecting together existing tooling for the use with human single-neuron data into a single module, for example, using neo39 for loading and interacting with recorded data and pynwb for creating and interacting with NWB files.40,41
**_hsnpipeline_supports_workflows_to_pre.jpg)
Pre-processing & spike sorting
Prior to analysis, electrophysiological recordings need to be pre-processed, including spike sorting to isolate putative single-neuron activity.42 Single-neuron recordings from human patients are typically recorded with microwires, such as with Behnke-Fried electrodes, in which individual microwires extend beyond the tip of the clinical depth electrode.10 Notably, this use of microwires in human recordings is different from current recording and pre-processing standards used in animal models, which often use grids of electrodes which allow for using spike sorting algorithms that leverage the known geometry of the electrodes.43 As such, despite the similar goals for spike sorting, in practice the requirements and specific tools of human single-neuron studies typically differ substantially from current practice with animal models, motivating the need for human data specific procedures and resources. Human recordings also often include probes across multiple areas and are recorded in a clinical setting with possible idiosyncratic noise sources, all of which adds variability to the recordings. Accordingly, spike sorting solutions from human recordings typically require verification through the examination of quality metrics and/or through manual inspection of the extracted waveforms. Overall, human single-neuron projects require the use of spike sorting approaches that can be applied to individual microwires with no known geometry, and functionality that allows for visually inspecting and curating spike sorting solutions.42
To address the specificities of human single-neuron recordings, this pipeline implements a recommended approach for spike sorting human single-neuron data, designed to work with microwire recordings. There are several available spike sorting algorithms which have been developed for human recordings, including Combinato,44 WaveClus,45 and OSort.46 Leveraging these available tools, the pipeline does not implement a new spike sorter but rather offers a template structure that can be integrated with existing spike sorters. Several of these sorters are also available in SpikeInterface,47 a framework for running and comparing spike sorting which can also be used within the pipeline as a way to run one or more of the aforementioned spike sorting algorithms, and/or to compare across spike sorting solutions. In the default template of the pipeline, the Combinato spike sorting algorithm is used, with some available utilities for managing the outputs of this tool. To support the data pre-processing and spike sorting, the hsntools module includes functionality for loading neural data files and managing spike sorting related outputs.
Regardless of which individual spike sorting algorithm is used, the process for spike sorting activity recorded from individual microwires typically follows the same protocol, wherein putative spike events are detected by a thresholding procedure, after which clusters of events are created reflecting putative single-neuron clusters. The main differences across algorithms largely relate to differences in the clustering algorithms that are used or in pre- and post-processing steps. This process typically requires manual curation, in which visual inspection verifies spike sorting solutions such that putative clusters may be rejected if they are considered to reflect non-neural noise. Clusters may also need to be separated if they are over clustered (if events have been combined that appear to arise from different neurons) and/or combined if they are under clustered (if multiple clusters appear likely to stem from the same neuron). In addition to curating the clustering process, additional properties may need to be verified in identified clusters – for example, a neuron with a well-defined waveform may have too few spikes and/or have spike events that are only present over a too small proportion of the task to be effectively analyzed. In order to support this functionality, the spike sorting materials and the hsntools module include guidelines and utilities for assisting with these processes, including curating and labelling spike sorting clusters and extracting, organizing and exporting spike sorting solutions for analysis.
Data conversion & standardized data files
Following pre-processing, the next element of the template is to organize collected data into a standardized format, that can be used for analyzing the data within the project, and later for sharing the data (and associated analyses) publicly at the time of project completion. To do so, the pipeline adopts a data standard and includes tools and templates for organizing data into this format. Data organization for human single-neuron experiments involves effectively structuring and coordinating at least three key types of data: metadata, neural data, and behavioral data. Optionally other data, such as the original local field potential data from the microwires and/or other data streams such as recordings from clinical macroelectrodes can also be added to these files. The template is agnostic to the file types or organization of the original recording files, which can vary across different recording amplifiers, and can be applied to a broad range of collected data, as long as the relevant data can be loaded and organized. The data conversion step includes organizing and converting the single-neuron data along with a structured representation of behavioral data and task information into a standardized file that should also include metadata necessary for understanding and reporting on the tasks, subject, and collected data.
A critical step in the process of data organization is synchronization, which ensures that disparate data streams are precisely temporally aligned, which is essential for accurately relating behavioral events to neural activity. There are multiple available strategies for synchronizing data in use in neuroscientific experiments, though there can be notable idiosyncrasies for human single-neuron studies which are recorded in clinical contexts. For example, beyond the typical situation of having different computers running and collecting the behavioral and neural data, there may additionally be different systems running the clinical macroelectrodes that record the local field potential and the microwire electrodes that record single-neuron activity, requiring strategies that can synchronize across potentially multiple disparate neural recordings. Synchronization strategies include using photodiodes or other outputs signals whereby time-stamped light flashes or other outputs can be sent from one system, typically the task computer, to an input channel on one or more other systems that need to be synchronized such that corresponding events can be detected and aligned in order to synchronize collected data across systems. Required functionality for these processes – including utilities for detected pulses on synchronization channels, computing temporal differences between synchronization channels, fitting models and realigning timestamps, and visualizing utilities to verify alignments – is available in hsntools as part of the pipeline. Further discussion on synchronization is also available in other guides for intracranial recordings which share similar synchronization requirements.35
The data standard used in this pipeline is the Neurodata Without Borders (NWB) format. NWB is a standardized data format that has been proposed for organizing and sharing multiple modalities of neuroscientific data.48–50 NWB is based on the HDF5 data format,51 and as such has the benefit of allowing for flexible definition and encoding of different data objects and the capacity to store large quantities of data while allowing for efficient read access, all organized into a hierarchical data object. The NWB format is ideal for human single-neuron data, as it already supports extracellular recordings with corresponding behavioral information for animal studies, and therefore already supports the necessary data structures required for human data without requiring any significant extensions or customization. In addition, NWB is already a format which has been used to share multiple available datasets of human single-neuron recordings,52–54 emphasizing its appropriateness for this use case. Other shared human single-neuron datasets55,56 use the NIX format,57 and/or use custom data files,58–60 overall suggesting that while there is not as yet a dominant data format for human single-neuron data, NWB is the most consistent choice thus far.
One of the key benefits of the NWB data format is that it is an extendable format offering the capacity to add multiple pre-defined data types, as well as offering functionality for designing custom definitions for additional data fields if needed. This serves the needs of human single-neuron projects, which may also include additional data streams such as eye-tracking, audio or video recordings, and/or other additional information from the patients. This flexibility also supports variability in the task designs, as NWB supports the integration of variable information as required for the task, including structured trials tables for event-based tasks, dedicated data structures for position and related information for (virtual) spatial navigation tasks, and support for storing stimulus information, including being able to add images, videos, and/or sound files into the NWB data structure. Once data is loaded and synchronized, NWB then enforces the use of a consistent time unit and clock across all the data within a session, allowing for the unified analysis of data from across the file, regardless of its original provenance. There are also data structures for defining and managing recording device information, allowing for the specification of information about electrodes including their organization and location, and a structured definition of expected metadata, that can also be extended for the project’s needs, to ensure that each data file contains all the relevant information for understanding and analyzing a session of data.
Data analysis for robust & reproducible analyses
The third and final part of the template relates to analyzing the data. The specifics of human single-neuron data analyses are necessarily specific to the task and research questions of the experiment. As such, the goal of the analysis template is not to serve as a guide for any specific analyses, but rather to provide a structure with associated guidelines to organize code and associated files that promotes best practices in scientific coding and in particular supports the use and development of readable, robust, and reproducible analyses.3,4 To do so, this section of the pipeline provides a recommended structure including templates and outlines for organizing code, running analyses across neurons, and creating reports and figures to visualize the results. This includes the use of Jupyter notebooks61 which allow for integrated examination and exploration of code and outputs, which is ideal for the development of analyses and the examination of individual examples and figures. Once analyses have been developed, the template recommends organizing code into dedicated analysis scripts, which are more efficient and robust for running analyses at scale.
One of the best practice guidelines enacted by the templates is the recommendation to use implementations from well-developed modules that include code tests and documentation, as such code is typically more robust, efficient, validated, and portable as compared to idiosyncratic re-implementations. To make sure such module code is available, we previously created and continue to support the spiketools Python module,38 which includes functionality of analyzing single-neuron responses and relating them to task performance (https://spiketools.github.io). Note that the pipeline does not enforce or require any particular analysis software, and the template structure can also be used with other openly-available analysis toolkits, for example, pynapple62 or pylabianca.63 In cases where desired functionality is unavailable and/or the analysis requires the implementation of novel analysis techniques, custom code can be developed and integrated for such analyses. To share such functionality back to the research community, these implementations can also be proposed to be added to modules such as spiketools. In addition, to assist with managing such analyses, hsntools includes control-flow related utilities for managing analyses across neurons, including managing paths and outputs, managing control flow by robustly catching and documenting errors encountered in individual neurons while allowing analyses to continue, and collecting, organizing, and saving results.
Another suggested approach is the use of ‘reports’, whereby a structured output reflecting statistical analyses and visualizations is designed to create a report that can be saved out as a document that reflects the overview of an analysis of an individual neuron, combining metadata and quality control information with results from the analyses. Additional report formats can also be created that reflect the analysis of a session of data, allowing for the systematic examination of behavioral results per session paired with summary data about the recorded neurons and/or across a group of sessions or patients, to visualize properties of the entire dataset. This approach emphasizes visibility and interpretability of results, in that it allows for running analyses while systematically saving out reports that allow for the examination and verification of neural and behavioral responses as well as providing visibility for potential issues or errors. Note that such reports do not seek to replace, but rather to supplement, group level analyses that examine patterns and summaries across neurons. Structuring analyses to include such report generation helps with analysis steps such as visually inspecting results, debugging possible issues, examining results across entire populations, and selecting example neurons for visualization by building report generation directly into the analysis framework.
One of the goals of emphasizing reports for the analysis of each recorded neuron is to assist with monitoring and evaluating quality control of neuron recordings and individual analyses. Quality control information included on such reports can include information such as the average spike waveform, spike quality metrics such as the presence ratio, and potentially raster plots across the whole task session and/or across all trials that can be used to identify potential drop out / drop in (if neurons are not consistently recorded across the whole recording). Notably, employing such measures that prioritize and visualize neuron quality metrics can also help address the subjective elements of curating spike sorting solutions. While any unambiguously artifactual or inconsistently recorded neurons should be rejected during manual curation there may be cases which are difficult to adjudicate as to whether individual clusters should be considered to be of neural origin and/or whether different clusters reflect one or multiple neurons visible on the same recording electrode. By having spike quality metrics available in the analysis reports, potential issues can be identified, for example, neuron presence varying across trials or conditions in ways that complicates the analysis, or observing different clusters with similar waveforms that appear to have very similar task-related response profiles such that they should potentially be merged.
Reports also seek to systematically create visualizations for each of the analyses applied to the neurons, for example, visualizing raster plots around events of interest or the pattern of firing across place or time bins. To do so, visualizations need to be created and tuned for each analysis, which can typically be efficiently created based on the templates available in spiketools. This can then be used in combination with functionality from hsntools for creating and saving multi-panel report figures. These reports seek to provide visibility on analyses that are being applied, allowing for verifying that analyses work as intended. Visualizations may also help to identify unexpected patterns – for example, visualizations of trial-by-trial raster plots or comparisons across conditions may suggest neural responses that respond to or discriminate between aspects of the task that were not initially hypothesized by the task design, allowing for further exploratory analyses of such cases. Reports can also help to identify if there may be potential issues with the data or analyses, such as if there are suspicious patterns that may not be visible in group summaries – for example, an unlikely consistency across neurons in terms of which place bin or time point or stimulus shows a significant response. The goal of such reports is to emphasize visibility and quality control of analyses of human single-neurons. Such reports can be efficiently designed and created using the available tooling, and can be modularly extended as new analyses are added. Note that while these reports do collect and visualize information across analyses, they are not intended as the main output for the statistical analyses – in addition to report generation, the template scripts, using functionality from hsntools and spiketools, also structure analyses to systematically collect results across analyses and neurons and save them out in structured, machine-readable formats which can then be used for examining group level results across the whole dataset.
Discussion
Pursuing, managing, and sharing large, complex, multi-site research projects, as is typically the case for studies collecting and analyzing human single-neuron recordings, requires dedicated resources and procedures for ensuring projects are organized, robust, efficient, and portable. Here, we propose the Human Single-Neuron Pipeline (HSNPipeline) to assist with these goals for human single-neuron data, a rare data type for which there is thus far a relative lack of existing resources. Examples of the use of this pipeline are available in a recent study examining single-neuron activity during a virtual spatial navigation and memory task, for which the data and code are made openly available,64 and in a comparison of place-cells analyses across humans and animal models.65 Additional ongoing projects are currently using the pipeline, ensuring that it has been developed and tested in a way as to ensure generalizability and applicability across multiple projects.
In its design and implementation, this template seeks to be a guide and framework to help support the development of robust, replicable, and shareable data and analysis pipelines for human single-neuron projects. In doing so, several key design choices are worth noting. First, this pipeline is organized in a modular fashion that is designed to be flexibly applicable to the varying details and requirements of human single-neuron projects. This flexibility is such that projects can choose to use different aspects of the pipeline as needed, as well as working to ensure that the pipeline can be adapted to projects across different kinds of tasks, research questions, and analyses. Second, this pipeline purposefully prioritizes the adoption of existing standards and tools. This approach effectively leverages available resources, which assists with inter-operability and avoids unnecessary development or duplication of functionality in novel bespoke standards or resources, which also reduces development burden for ensuring this pipeline remains active and supported.
A notable design choice for this pipeline is the choice of the NWB data standard for organizing data. There are other data formats in use for data collected from human subjects, most notably BIDS, which has specifications for managing imaging data6 as well as electrophysiological recordings including iEEG.66 However, the BIDS ecosystem does not currently support single-neuron recordings, and as such would have required significant development of an appropriate extension to support this. In addition, such an extension would likely not be as interoperable with existing tools for single-neuron pre-processing and analysis, for which NWB is already a common standard. However, the use of a data standard different from that more commonly in use in other modalities in human data does have limitations, perhaps most notably that while iEEG data can also be organized into NWB files, it is perhaps more common to manage such data in BIDS, which creates some potential tension for projects seeking to analyze both LFP and single-neuron data from the same sessions. Future work that explores and develops best-practices for supporting integration across data formats and/or proposes a unified approach for studies examining both data types will be a valuable contribution.
A key goal of this pipeline is to embody and promote best practices for scientific project management including for managing and sharing data, code, and project outputs. The code related to this pipeline, including the hsntools and spiketools Python modules, are developed following best practices for module development, including being version controlled, documented, tested, and following a development and release schedule including semantic versioning. Other included resources, including templates for analysis code, documentation, and examples, seek to promote best practices by being openly-accessible, version controlled, and robustly documented. These principles seek to embody and promote coding principles that are appropriate for scientific code and that promote readability, resilience, and reuse,3,4 to support robust and reliable analyses. Such approaches also promote portable and interoperable analyses that can be applied across the different people and labs that are often involved in such projects. Finally, these approaches also build in standardized approaches for supporting readable and shareable resources, allowing for public release without significant additional work for cases in which the code and analyses are to be publicly released as part of a publication.
A key consideration when working with human clinical patients is ethics and privacy.34 Projects that include data collected from across multiple sites and potentially from across multiple different countries must consider data governance and relevant regulations for data sharing.67 If data is to be shared, then the privacy of patients must be ensured, removing names, dates and other potentially identifiable information. Notably, using a structured and standardized data format such as NWB is useful for this as standardized data fields only contain information explicitly added to the file (as opposed to raw recording files which may contain sensitive labels and dates in headers or other sections) and can be easily scrubbed of sensitive data fields for public release. This pipeline also does not discuss the details of managing anatomical data which is likely to be included in such projects, as there are guides to such aspects elsewhere,35 though it should be noted that if anatomical data is to also be shared there are additional privacy concerns to be addressed for such data, for example due to the potential for re-identification from facial reconstruction from anatomical recordings.68
While this project seeks to fill a niche in providing resources for human single-neuron projects to fill a gap in the available resources, this project is only possible due to the integration of existing tools to support the different aspects of this overall pipeline. In terms of the key element of the data structure, this includes the NWB data format and related tools for creating and interacting with such files,40,49 and well as notable previous examples demonstrating and advocating for using NWB for human single-neuron projects.52 Other related tools, for example, SpikeInterface, that integrates multiple different spike sorting algorithms and related functionality into a unified interface,47 and neuroconv,69 a tool that supports converting various data streams to NWB, offer additional functionality in the broader ecosystem and that can potentially be productively integrated in future development of the pipeline.
Further potential development and extension to this pipeline may be useful to extend beyond its current scope. Although designed to be broadly applicable to different task and analysis contexts, its adoption across additional projects may assist in assuring its scope and utilities genuinely do apply across contexts. For example, many of the current experiments and tasks that have been used with the pipeline are Behnke-Fried electrode recordings of spatial navigation and memory tasks using similar approaches for behavioral data logging, and most of the analysis have been applied at the level of individual neurons (e.g., running analyses across each individual neuron). Further extensions to the components of the pipeline may come from extending support to explicitly include other kinds of electrodes; exploring its use with different kinds of tasks and logging processes; and different analysis approaches, such as population analyses – all of which, if explored through the pipeline, could provide additional functionality that could be merged into the code and resources of the pipeline to better support the breadth of human single-neuron projects.
While the main motivations of standardized processing pipelines relate to individual projects, there can also be additional benefits to standardization within and between labs and research hospitals. A notable aspect of single-neuron experiments is that the same patient is typically in the EMU for a week or more, and if they have consented to research, are likely to complete multiple sessions of the same task, and/or multiple different tasks. This allows for the possibility of analyzing recordings from the same patients across multiple sessions and tasks.70 This research design can be useful to address research questions comparing representations, for example, examining the same neurons across different kinds of tasks to examine the flexibility of hippocampal representations.64 However, these different tasks are often affiliated with multiple different labs, with data integration and comparison depending on interoperability across potentially different kinds of task designs, data streams, recording equipment, and pre-processing. This can complicate combining and analyzing the data together, even for data recorded from the same subjects. If studies being recorded at the same or overlapping hospitals coordinate to adopt consistent practices and data standards, as is supported by the pipeline proposed here, then such cross-task comparisons should become much easier.
The field of human single-neuron recording is rapidly advancing, with significant investment having been put into developing equipment and protocols to safely and effectively implant electrodes in the context of clinical recordings that allow for basic and clinical research investigations. This data is valuable, both in the rareness of the opportunity to collect it, and in the cost of doing so when possible, which behooves us to ensure that such datasets are efficiently and effectively collected, curated, and analyzed, and shared to the broader community, if and when possible. This has the benefit not only of supporting research projects that include between-task comparisons by design, but also of making it easier to do post-hoc data integration and comparison, comparing between tasks from across distinct projects that happened to be recorded in the same patients – research designs that are thus far vanishingly rare with human single-neuron datasets, but which could be supported by increased standardization, as seen in other modalities that have adopted standardized practices for data collection, organization, and analysis.
Conclusion
The efficient storage, analysis, sharing, and re-use of scientific data requires the use of interoperable and interpretable data standards and processing procedures that allow for standardization of data and analyses within and between projects that match the requirements for the data under study. Here, we propose an overarching pipeline for assisting with this goal for single-neuron recordings as recorded from human clinical patients, a relatively rare but very useful data modality for which there is currently a lack of standardization. This pipeline includes the adoption of a standardized data format (NWB), as well as providing templates, guides, and associated utilities and resources for pre-processing and analyses of human single-neuron data, all designed in a modular way. Collectively, this pipeline offers support and resources to increasing the standardization of human single-neuron projects.
Author contributions
TD and JJ designed the project and materials. TD, WZ, CZH, and SMP contributed code and resources. TD drafted and all authors contributed to writing and editing the manuscript.
Data & code availability
This manuscript reports on the ‘Human Single-Neuron Pipeline’ (HSNPipeline), which is available as an open-source collection of resources, templates, and Python code implementations.
Human Single-Neuron Pipeline:
Source https://github.com/HSNPipeline/
Website https://hsnpipeline.github.io/
Code and figures created for this manuscript are available on Github:
Paper Repository https://github.com/HSNPipeline/Paper
Funding sources
This work was supported by NIH grants 5U01NS121472-04 and R01-MH104606 awarded to JJ.
Conflicts of Interest
The authors declare no conflicts of interest.
Acknowledgments
We would like to thank members of the Jacobs lab for helpful discussions related to this work.