Introduction
Neuroimaging analysis has become increasingly central to neuroscience research and clinical practice, yet effectively teaching these techniques demands attention to both conceptual complexity and technical implementation. Researchers across different disciplines and career stages face diverse challenges when engaging with neuroimaging analysis.1,2 On the technical side, one must navigate diverse software environments, such as command-line tools, scripting languages or containerised workflows, alongside dependency management, and cross-platform compatibility, which are well-documented barriers to reproducible research.1,3–6 Additionally, other challenges of scientific software projects manifest as abandoned GitHub repositories with outdated dependencies, broken installation scripts that fail on newer operating systems (e.g., glibc incompatibilities), or example code that no longer runs due to API changes in underlying libraries.
Then, on the conceptual side, neuroimaging requires mastery of foundational principles that span diverse imaging modalities, computational tools, and statistical frameworks. Functional magnetic resonance imaging (fMRI) involves understanding hemodynamic modelling and statistical inference, while diffusion MRI relies on tractography and tensor modelling, and structural MRI focuses on tissue segmentation and morphometric analysis. In turn, these conceptual challenges each present unique methodological challenges in their implementation. One must also consider requirements for data quality,7 preprocessing, experimental design, and interdisciplinary integration of knowledge from neuroscience, statistics, and computer science.
Together, these challenges are particularly significant given the diverse backgrounds of neuroimaging researchers, who range from software engineers and computer scientists to clinical neuroscientists and medical professionals, with varying levels of computational expertise spanning from expert programmers to those with little to no prior knowledge.8 This diversity extends beyond individual skill sets to encompass varied institutional contexts and technical infrastructures, including different operating systems, computing resources, and levels of administrative access.4
Effective neuroimaging education must accommodate this diversity by adopting evidence-based best practices that emphasise self-directed exploration and problem-centred learning.9,10 Educational approaches that enable users to adapt materials to their own pace, experiment with analytical parameters, and immediately apply techniques to real problems align with how complex technical skills are best acquired in practice.9 Beyond individual learning barriers, the distribution of up-to-date information and versions of educational content poses challenges, as maintaining consistency across varying computing environments, while reaching a global audience requires robust and flexible infrastructure. Democratising access to neuroimaging education requires such a resource to enable participation regardless of institutional resources, technical infrastructure, or geographic location.11
Avenues for further enriching current educational approaches in neuroimaging
Currently, neuroimaging education is well supported by diverse resources, including comprehensive tutorials such as Andy’s Brain Book,12 community exchange spaces (e.g., https://neurostars.org), software-specific documentation,13–17 courses such as the FSL Course18 or the AFNI Bootcamp,19 and many other lecture series and workshop-based training programs.20–22 These resources provide invaluable knowledge and enable hands-on practice through step-by-step guidance. Educational approaches vary in how they structure the learning experience: some provide separate documentation and execution environments, while notebook-based tutorials offered by some tools (i.e., Nipype14) integrate code and instruction within a single interface. Each approach serves different learning contexts and preferences. However, most existing resources require users to install software environments locally. Additionally, educational materials that lack formal version control systems can complicate efforts to track changes, ensure reproducibility, and keep examples current as neuroimaging software evolves.
Reproducibility concerns can extend beyond educational materials themselves to the practices they promote, including data visualisation methods. For instance, figures created manually through graphical user interfaces (GUI) or involving post-processing in external software cannot be independently recreated or systematically modified,23 limiting transparency and reproducibility. Teaching reproducible practices is therefore essential for advancing reproducibility in neuroimaging research. As Rule et al. (2019)24 note, minimum standards for reproducibility require “both machine-readable descriptions of the data, software, dependencies, and computational environment involved […] as well as human-readable documentation describing how all these pieces fit together.” These requirements align with the FAIR data principles25 and the FAIR4RS initiative for research software,26 which promote findability, accessibility, interoperability, and reusability across both data and computational resources. Embedding these principles in neuroimaging education extends training beyond statistical analysis methods to include transparent, shareable, and well-documented research practices increasingly expected in contemporary neuroscience.
In neuroimaging, educational materials such as tutorials and example analyses serve as important tools for demonstrating and disseminating practices essential for reproducible research, including transparent reporting, executable workflows, and well-documented analysis pipelines. Despite their importance, educational contributions are often not treated as primary scholarly outputs,27 potentially discouraging the development and sharing of high-quality teaching materials. This lack of recognition is noteworthy given the substantial time investment required to create comprehensive neuroimaging tutorials: diverse modalities, numerous processing steps, and varied analytical approaches each demand careful documentation and contextualisation. The processes for community members to contribute to or extend existing tutorial collections can also be cumbersome, limiting the diversity of available educational content and the pace at which resources adapt to emerging methods. Together, these factors highlight the need for more open, transparent, and innovative approaches to publishing neuroimaging education that align with the evolving landscape of scientific communication, open science, and knowledge dissemination.
Educational opportunities from technological advances
Recent technological advances in computational publishing and executable research infrastructure present opportunities to address these educational challenges. The Journal of Open Source Education (JOSE), a sibling journal to the Journal of Open Source Software (JOSS),28 operating on the same editorial and technical infrastructure, provides a peer-review venue for open-source educational materials that incorporate computational elements. JOSE publishes scholarly articles describing these resources, assigns DOIs to accepted submissions, and operates on a volunteer basis without subscription fees.29 Complementing these quality assurance mechanisms, technical infrastructure advances support new modes of interactive computational education.
Computational notebooks such as Jupyter enable the creation of “computational narratives” that integrate live code, visualisations, and explanatory text within cohesive educational experiences.30–32 This approach has been successfully applied in resources like the BrainIAK tutorials for advanced fMRI analysis.33 Yet notebooks themselves have well-documented limitations, including hidden state arising from non-linear cell execution, dependency management issues, and tension between exploratory coding practices and software engineering best practices, such as automated testing and adherence to style conventions.34 For computational work to be truly useful, it must be embedded within narratives tailored to particular audiences and contexts. This literate computing format aligns with how humans naturally process information through stories and supports self-directed exploration.31 Interactive visualisation tools represent another significant technological advance for neuroimaging education. Modern browser-based neuroimaging viewers, such as Niivue and its Jupyter Notebook integration ipyniivue,35 allow exploration of neuroimaging data within integrated workflows. Addressing installation barriers, containerisation technologies6 provide standardised, pre-configured analysis environments that work consistently across platforms.36,37 Platforms like Code Ocean demonstrate how containerised environments can be integrated into scholarly publishing workflows, enabling executable research capsules that support verification and reuse of published analyses.38 Open data initiatives have further enhanced accessibility by making datasets readily available, enabling immediate engagement with real research scenarios.11,36,39
Finally, Neurodesk39 provides a stable technical infrastructure for reproducible, accessible neuroimaging education. Over 200 neuroimaging tools are packaged as self-contained containers (Neurocontainers) and streamed on-demand via the CernVM File System (CVMFS), enabling users to access software by streaming only the components actively being used rather than installing the full suite locally.37 The platform integrates open data resources from established repositories including OpenNeuro,40 Open Science Framework (OSF)41 and other community-driven data sharing initiatives. Through tools such as DataLada,42 neuroimaging datasets are immediately available within the computational environment.11 Multiple deployment models are supported to accommodate different user needs and technical contexts. For barrier-free access, Neurodesk Play (https://play.neurodesk.org) provides a globally accessible, browser-based service requiring no installation or setup. Additional deployment options include local installation and high-performance computing environments for users requiring more computational resources or institutional integration.
The convergence of these technologies creates an opportunity to develop neuroimaging educational resources that address challenges in existing approaches while adhering to best practices for computational reproducibility. In this work, we present interactive computational notebooks developed as part of NeurodeskEDU (Neurodesk Education), an openly available online reference book for neuroimaging education built using the Neurodesk ecosystem, a portable, container-based neuroimaging platform.
Our objectives are to: (1) demonstrate how computational notebook-based technologies can enhance neuroimaging education through interactive, narrative-driven learning experiences that integrate code, visualisation, and explanation; (2) show how containerised software can be incorporated into educational notebook workflows to eliminate installation barriers while ensuring reproducibility; (3) implement mechanisms for peer-reviewed community contribution and formal citation of educational materials; and (4) provide a framework for developing neuroimaging educational resources that remain maintainable as software tools evolve.
Methods
Overview
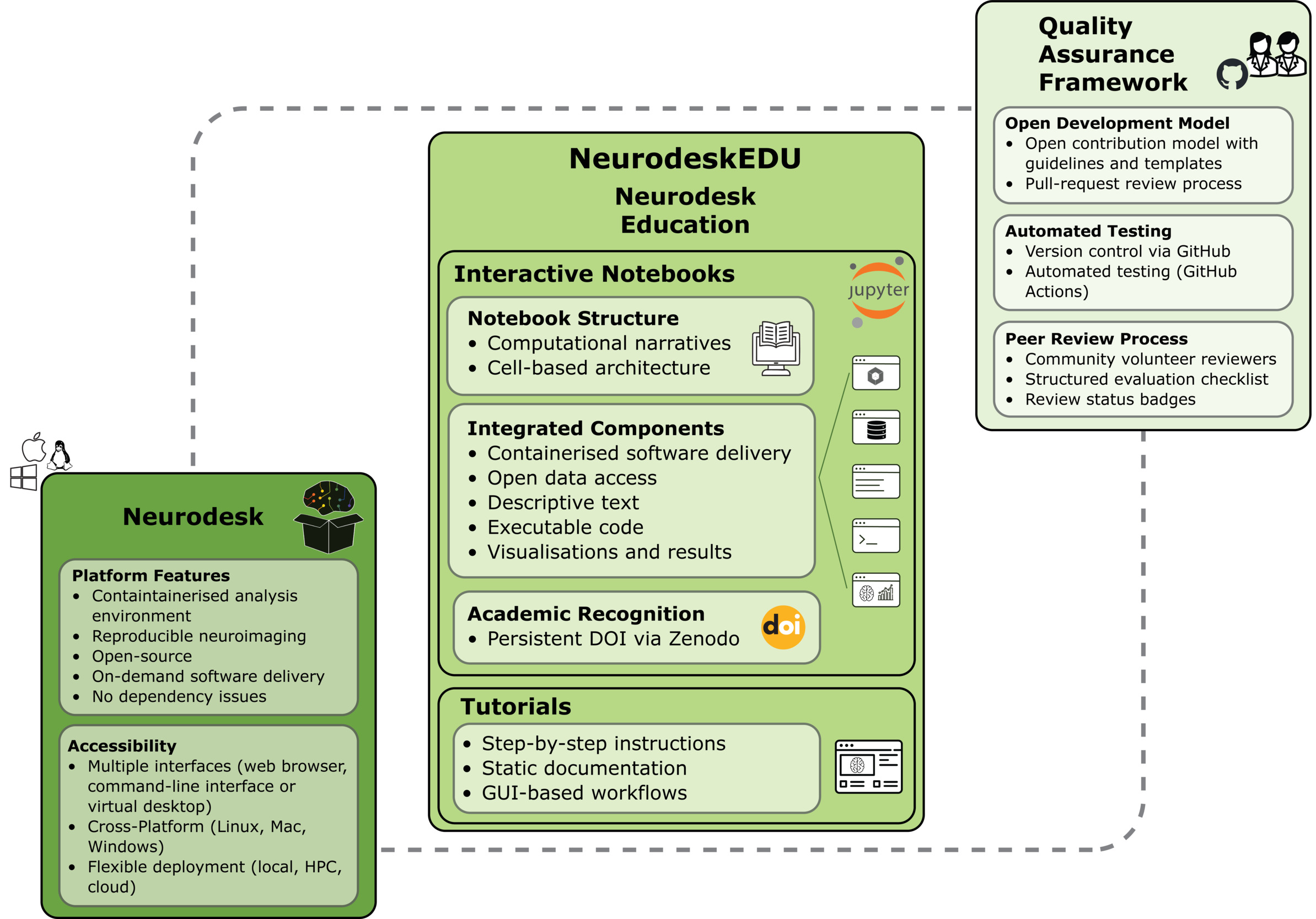
To provide an integrated, hands-on learning experience, we developed NeurodeskEDU’s interactive educational notebooks using Jupyter and the JupyterLab interface. As NeurodeskEDU is built upon Neurodesk39 it allows users to run analyses and examples without installing any tools locally and reproducibly across operating systems (Windows, macOS, Linux). Within this environment, our narrative computational notebooks offer an integrated alternative to traditional educational resources. Each notebook serves as both an interactive learning resource and a citable scholarly output, with persistent Digital Object Identifiers (DOIs) enabling formal recognition of educational contributions (Figure 1). The following sections describe the design principles, reproducibility mechanisms, and scholarly recognition framework underlying NeurodeskEDU.
__neurodeskedu_s_interactiv.png)
Notebook design and narrative structure
Following the concept of computational narratives,31 NeurodeskEDU notebooks guide users through diverse use cases, from demonstrating individual tools to executing complex neuroimaging analysis workflows, while maintaining a coherent learning progression. Each notebook integrates multiple components: markdown-formatted instructional text explaining concepts and analytical rationale, executable code implementing methods, immediate computational outputs, and embedded visualisations presenting results. The integration of all these elements within a single interface reduces cognitive load and eliminates context switching between separate tools, supporting a more streamlined learning experience. Furthermore, by storing computational outputs directly alongside their generating code, notebooks create a permanent record that maintains a transparent link between results and their analytical origins,6 reinforcing conceptual understanding of how analytical decisions shape outcomes.
Integrating code-based figure generation within analytical narratives offers advantages over GUI-based tools in terms of reproducibility and flexibility, enabling transparent outputs that can be independently replicated and modified.23 Notebooks incorporate sophisticated visualisation capabilities through plotting libraries (e.g., Matplotlib,43 DIPY,44 FURY45) and specialised code-based neuroimaging visualisation tools, including interactive viewers (e.g., ipyniivue,35 Nilearn46), allowing production of publication-ready visualisations directly within the analysis environment. While GUI-based neuroimaging tools are often used interactively, some environments (e.g., AFNI47,48 and SUMA49,50) also support command-line-driven workflows that create systematic and reproducible images. The notebook framework facilitates both code-based and command-line figure generation within a unified environment. This integration helps users understand how analyses are performed and how results can be effectively communicated without interrupting the workflow.
Interactivity is further supported through ipywidgets,51 interactive HTML widgets for Jupyter Notebooks and the IPython kernel, which allow self-directed and in-depth exploration of parameters and their effects on analysis outcomes, without requiring manual code modification.
While the majority of NeurodeskEDU notebooks demonstrate Python-based workflows, the platform also supports multi-language analyses through Jupyter’s magic command system.52 For example, R code can be executed within notebooks using R magic commands (%%R), alongside Python code without requiring kernel switching.
Modular and cell-based learning architecture
NeurodeskEDU systematically leverages the cell-based architecture of Jupyter Notebooks for both educational and scholarly communication purposes. Each cell represents a meaningful analytical step, enabling incremental execution, inspection and transparent reporting of code. This stepwise structure facilitates debugging and promotes a clear understanding of complex neuroimaging workflows, while also supporting research transparency through explicit, auditable analytical traces. Cells are organised with descriptive markdown headers, comprehensive documentation, and low-level code comments, creating clear logical divisions that serve as educational scaffolding.
For workflows that require substantial computation time or distinct processing phases, analyses are divided into sequential notebooks, each building upon outputs from the previous stage. This design allows users to complete computationally intensive steps separately while maintaining the logical flow of the complete pipeline.
Furthermore, modular code structure decomposes analysis steps into discrete, reusable functions, implementing established software engineering principles that enhance code readability, debuggability, and parameter exploration. This modularity helps to understand the purpose of each analytical component and makes it straightforward to adapt these functions across different datasets and analysis pipelines.
Reproducibility documentation
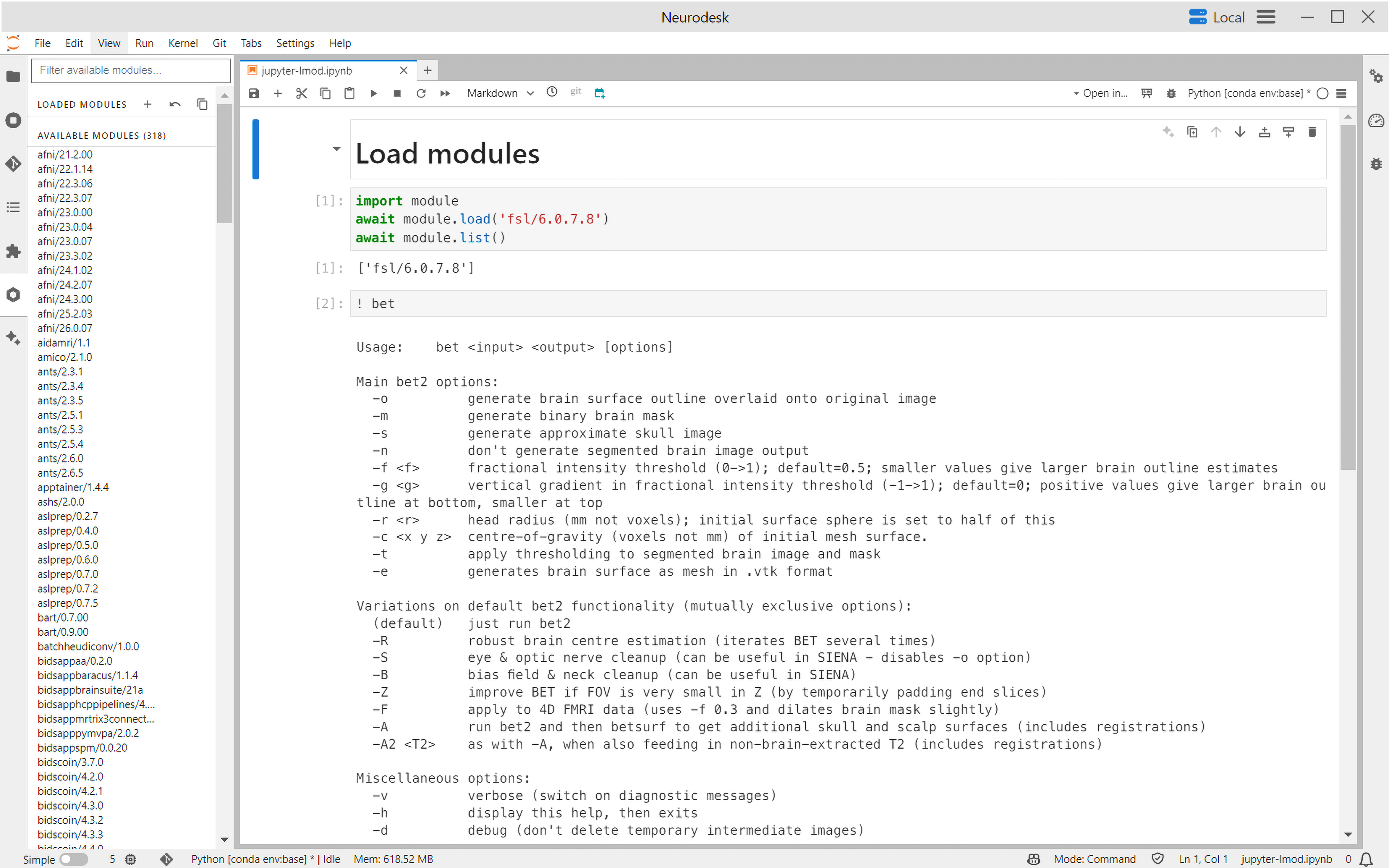
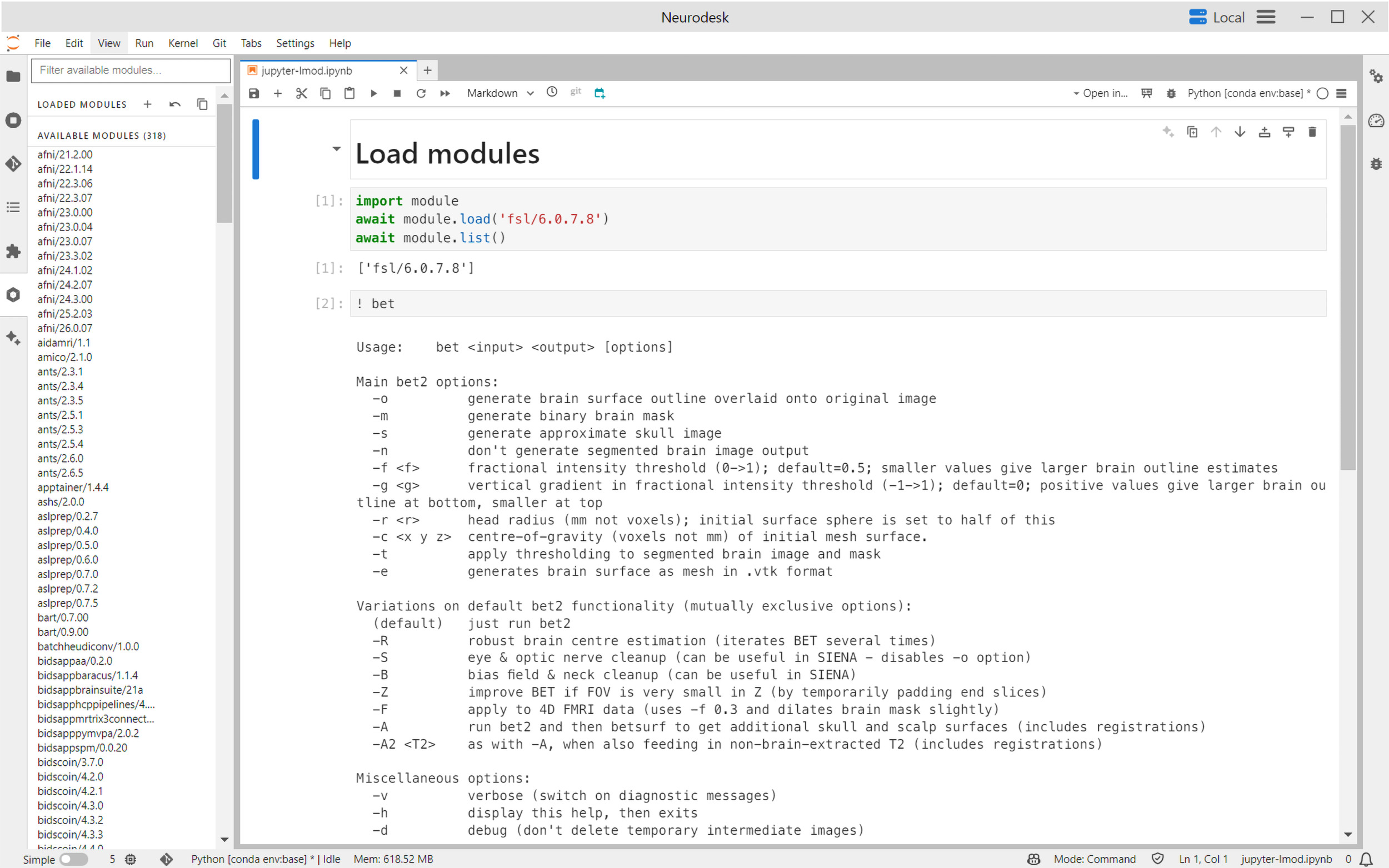
Within notebooks, specific software versions are accessed through an intuitive modular loading system implemented via jupyter-lmod,53 a Jupyter extension providing environment module functionality. For example, a specific version of FSL can be loaded using module.load('fsl/6.0.7.8') and seamlessly combined with other neuroimaging tools without dependency conflicts (Figure 2). This approach ensures version-specific reproducibility while enabling flexible integration of multiple tools.
To complement this versioned software access, all example notebooks include the watermark extension54 to document the execution environment at the end of each notebook, including the Python version, system architecture, and versions of all imported Python libraries. This explicit documentation ensures that even if a notebook is used in isolation from its original environment, it retains essential dependency information necessary for reproduction, addressing a key challenge in computational reproducibility.24
Educational content formats and delivery
Notebooks are rendered into static HTML documentation on the NeurodeskEDU website using Jupyter Book,55 creating persistent, searchable educational resources accessible in any web browser. This static rendering ensures that content remains available even when interactive computing resources are unavailable, while maintaining the visual integration of code, outputs, and explanatory text.
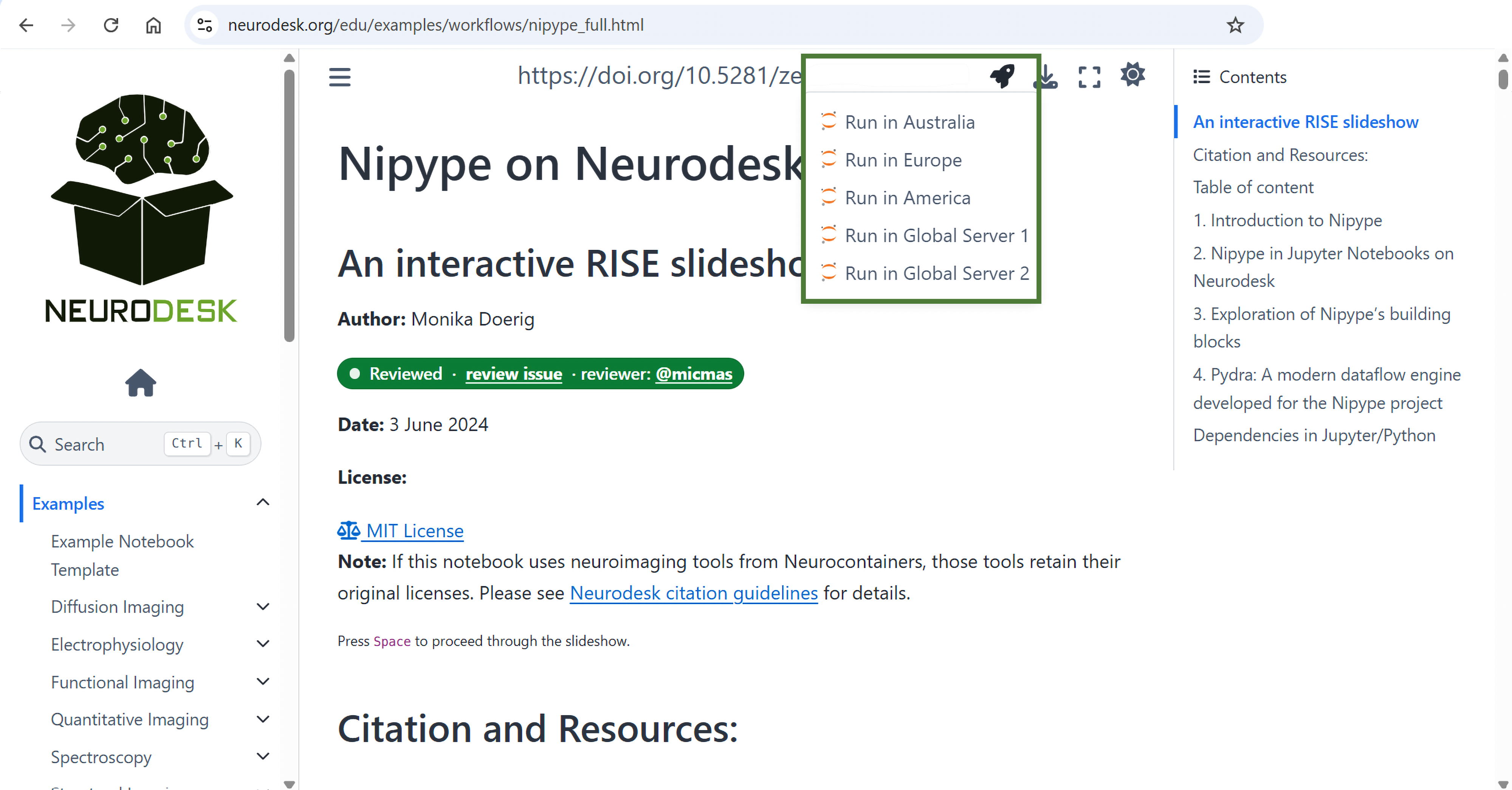
For interactive execution, each notebook in the collection can be launched directly in Neurodesk Play via a single-click icon from the static documentation site (Figure 3). This setup provides immediate access to live, executable code in a fully configured neuroimaging environment without any installation, configuration, or downloads required.
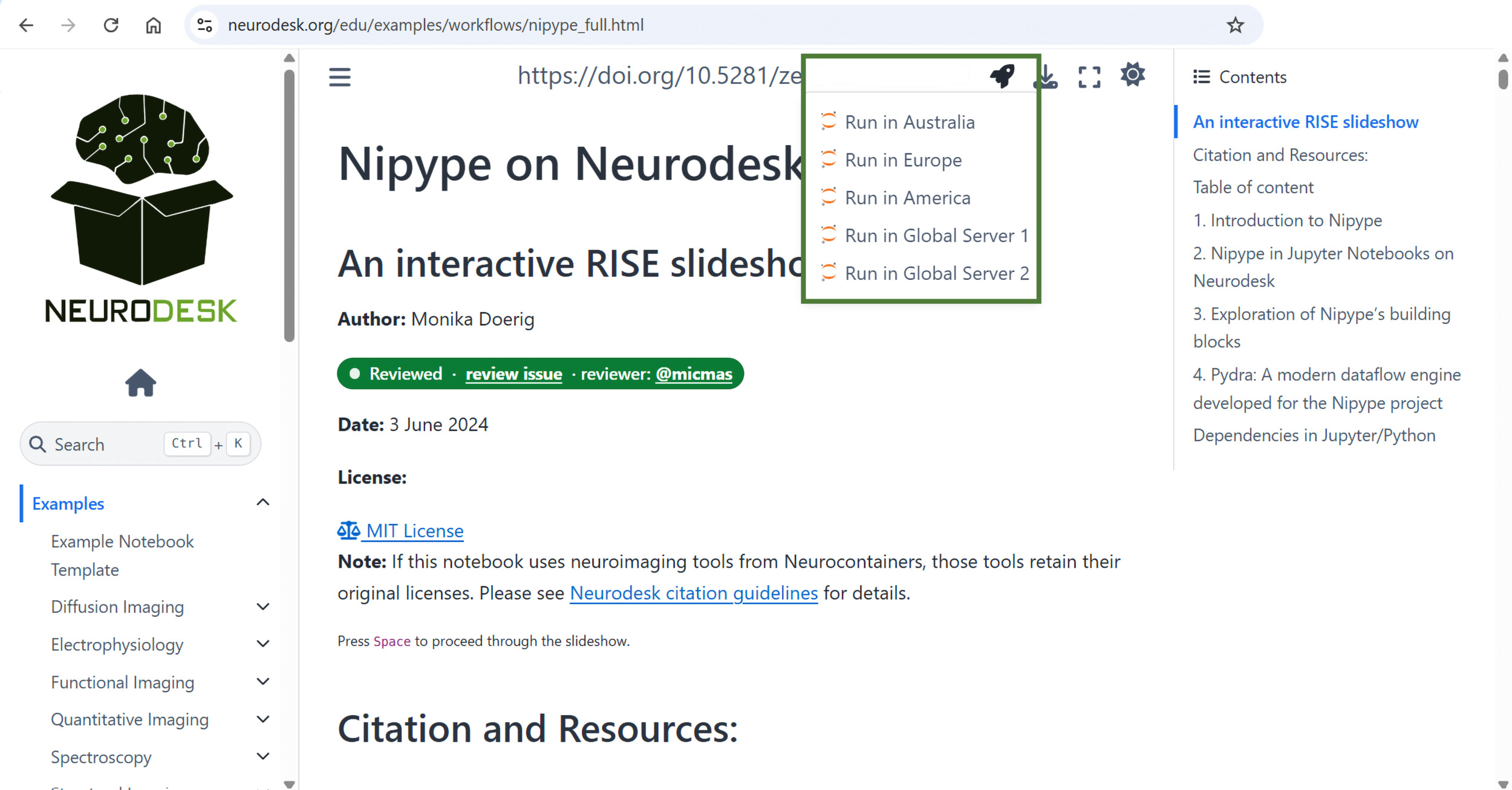
Users can also clone or download the complete notebook files directly from the GitHub repository for local execution through Neurodesk installations. This download option provides flexibility for users who prefer working offline or require more computational resources.
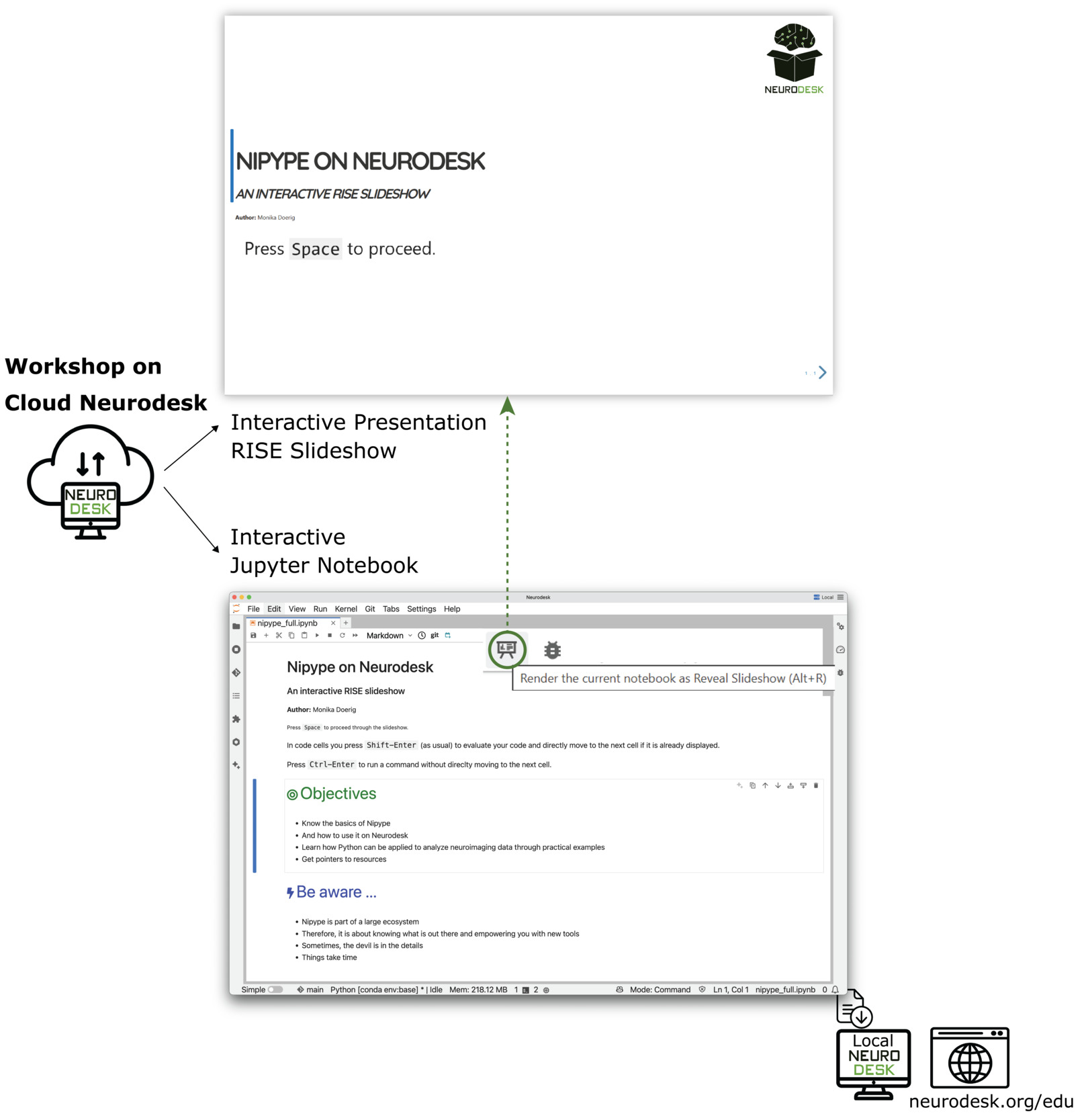
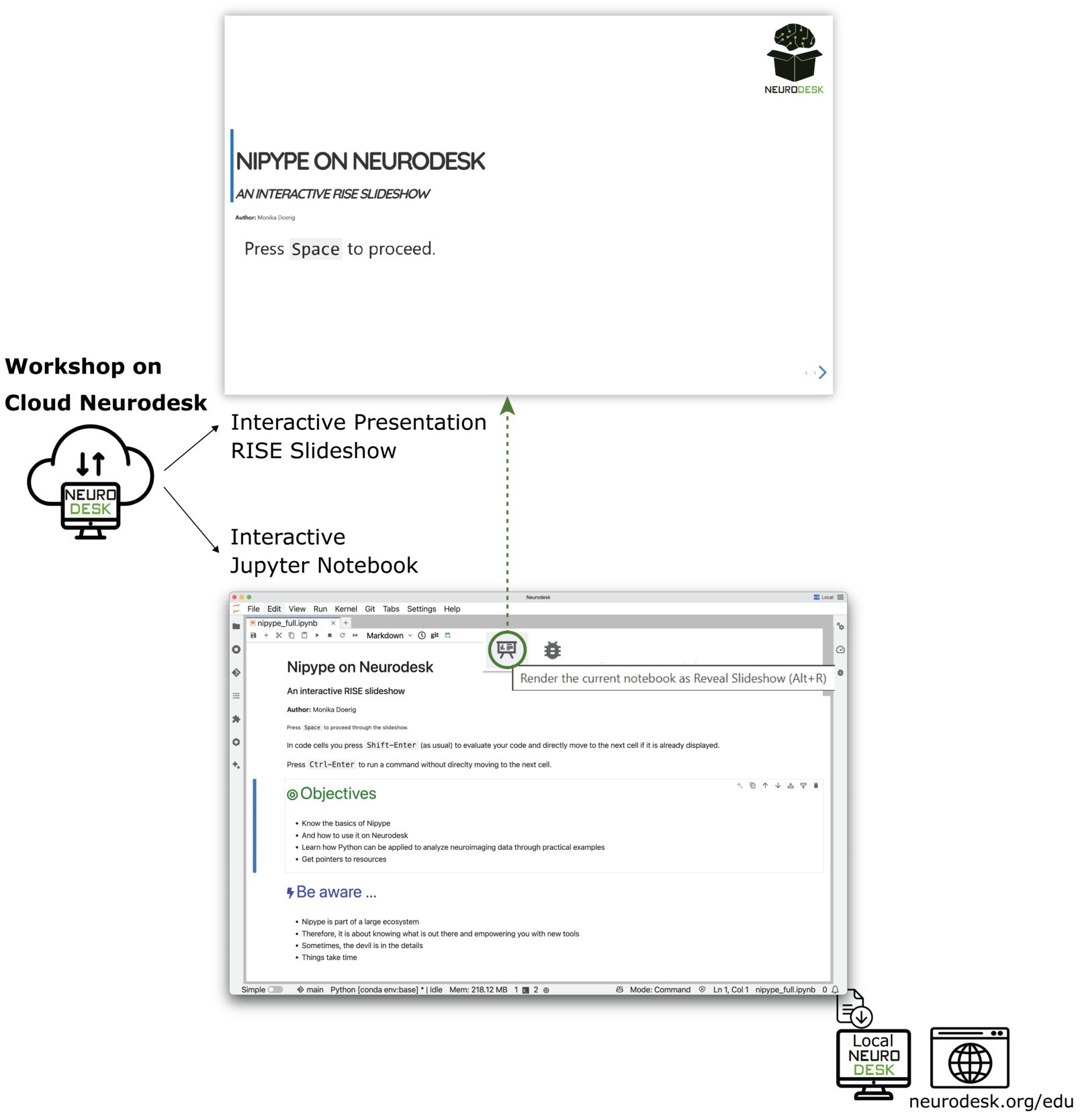
Additionally, notebooks can be presented in a live, slide-based format using the RISE extension56 for Jupyter. This allows instructors to transform the notebooks directly into interactive slides for classroom instruction or workshops, while preserving executable code and visualisations. Since the RISE extension is already included in Neurodesk, no installation or configuration is required. We provide an instructional notebook in our repository that demonstrates how to set slide-level cell metadata and convert any notebook into a RISE-based presentation (RISE Slideshow). Contributors may choose to configure their notebooks with slide metadata; this is optional and not required for publication. Many NeurodeskEDU notebooks include slide metadata, enabling immediate use in presentation mode. As an illustrative example Nipype on Neurodesk demonstrates this functionality. Participants can follow the narrative step by step as instructors highlight key analytical steps, demonstrating workflows interactively without leaving the notebook environment. This accessibility model supports both individual learning and classroom settings, providing scalable access to a standardised environment that facilitates remote participation and continued engagement with materials beyond formal instruction.
Community contribution framework
NeurodeskEDU’s submission workflow supports and encourages community contributions. Contribution guidelines and templates are available at https://neurodesk.org/edu/contribute/examples.html. All notebooks and supporting code are maintained in a public GitHub repository (https://github.com/neurodesk/neurodeskedu), providing transparent development and evolution of materials. This collaborative approach leverages the expertise of the broader neuroimaging community while maintaining high quality.
Contributors can fork the repository, creating their own editable copy of the project, use the provided templates to develop new material, and then submit pull requests — GitHub’s mechanism for proposing changes. These submissions undergo automated testing via GitHub Actions before being merged (integrated) into the main repository. The automated testing verifies that notebooks remain executable and functional as software dependencies and tool versions change, addressing a common challenge in computational education where tutorial examples can become outdated. Contributions are encouraged across the full spectrum of neuroimaging applications and methodologies, promoting diversity in analytical techniques and research contexts. This community-maintained model, supported by version control and continuous integration, offers a scalable framework for creating and curating computational educational content that remains current as methods evolve.
Persistent citation and academic recognition
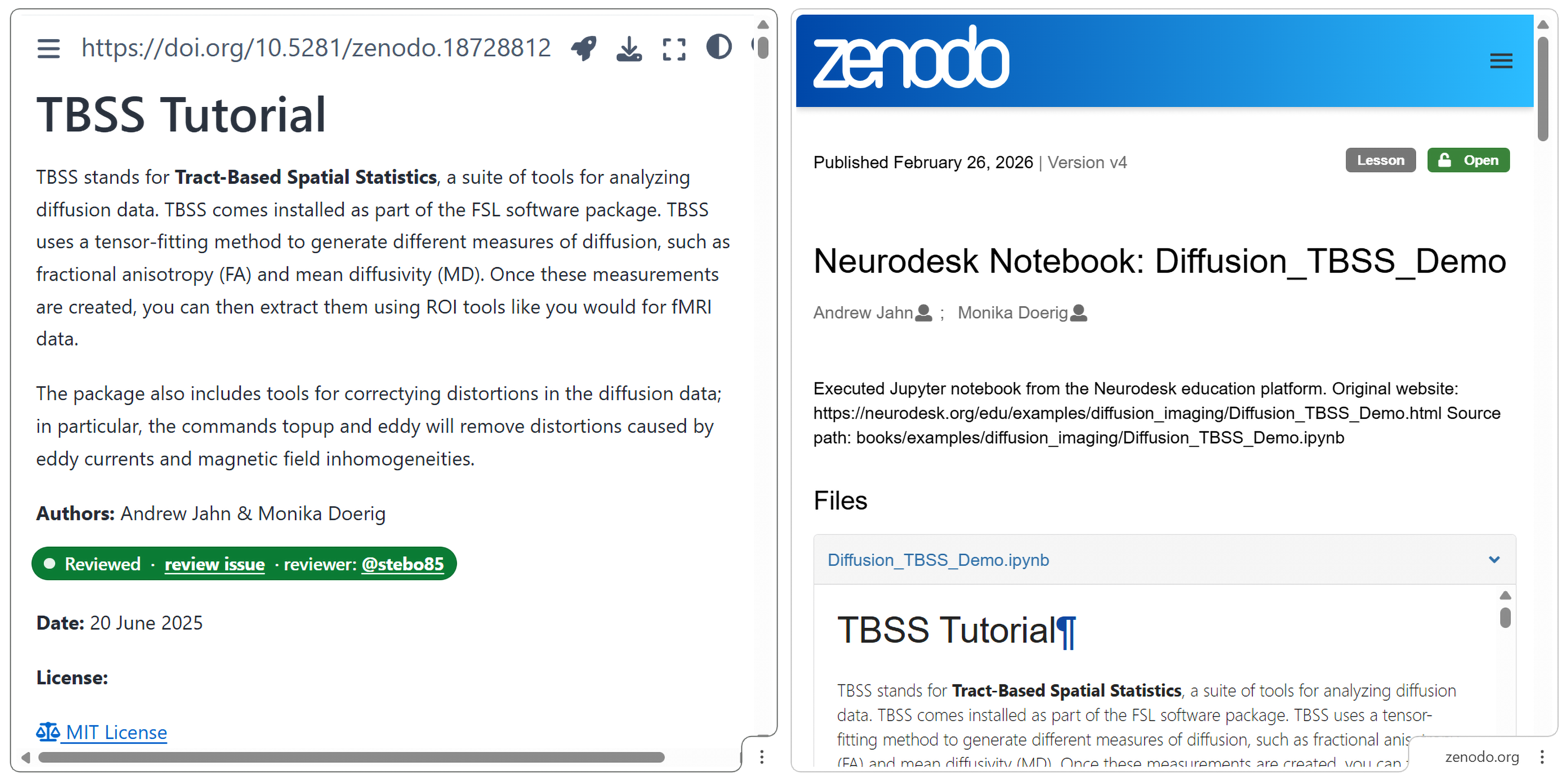
Once the notebook successfully passes the GitHub Action test, it is assigned a unique version DOI via Zenodo, establishing educational content as a formally citable research output. This enables precise referencing of analytical methods and workflows while providing formal credit for educational contributions. The system assigns a new DOI version to each updated notebook. This approach prevents citation ambiguity and ensures that notebooks can be reliably referenced in courses, publications, or as the basis for derivative work. For example, the TBSS Tutorial notebook is available at Zenodo via DOI 10.5281/zenodo.18728812. The DOI is displayed prominently on the static Jupyter Book site, directly above the notebook title, adjacent to the launch and download icon (Figure 4).
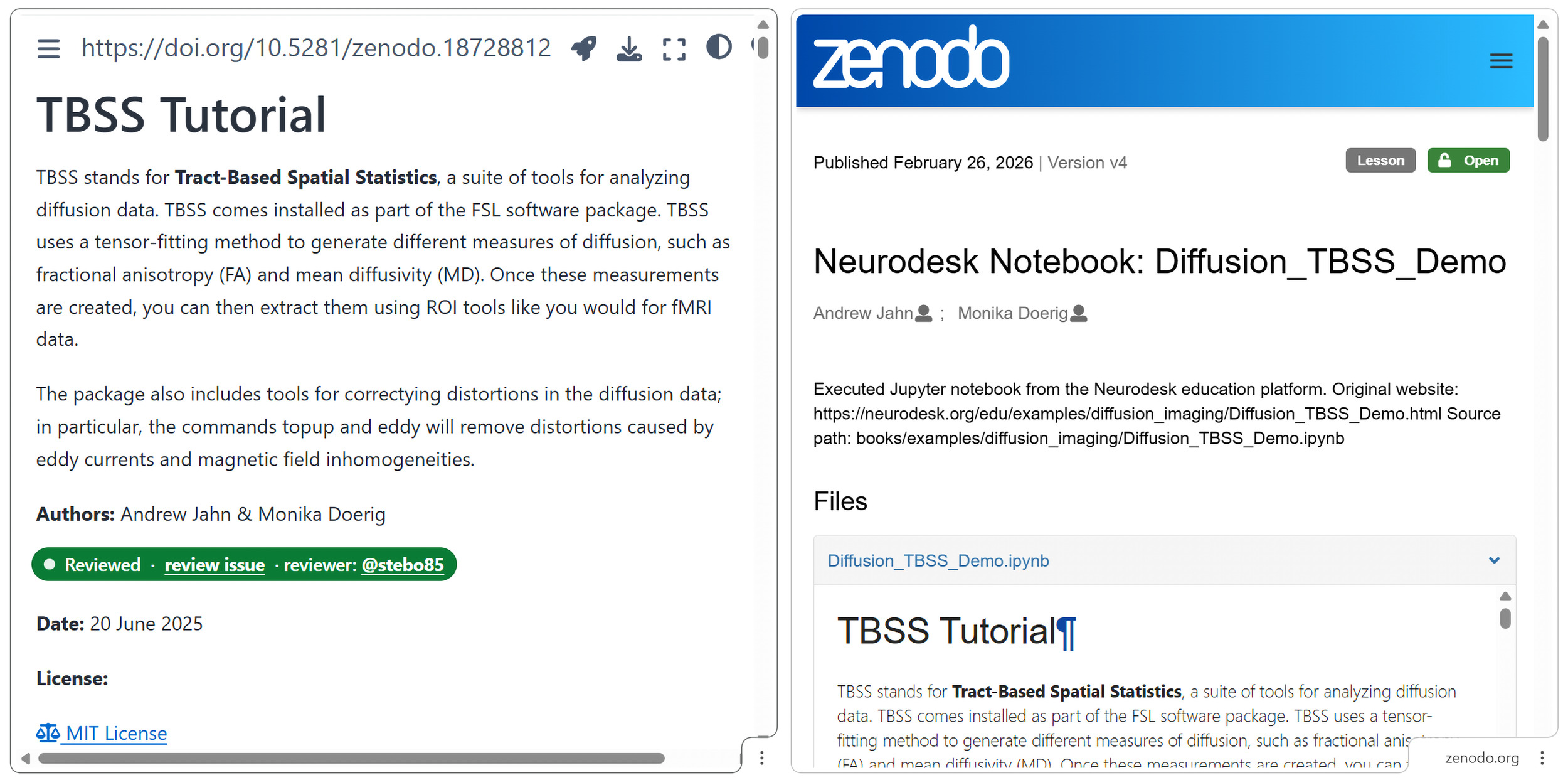
This integrated design implements key aspects of the FAIR4RS principles,26 ensuring educational materials remain findable, accessible, and reusable over time while demonstrating how interactive tutorial formats can maintain the scholarly rigour and citability of academic outputs. The Zenodo deposit workflow is automated via GitHub Actions, providing reproducibility and auditability: the Actions logs record DOI generation, and Zenodo’s version history allows verification of each notebook deposit.
Peer review
To ensure quality and address potential conflicts of interest in content curation, a formal peer review system modelled on the Journal of Open Source Education (JOSE) has been implemented for NeurodeskEDU. The review process is not a hurdle that prevents the publication of a notebook. Rather, notebooks will be marked as “Unreviewed”, “Under review”, “Reviewed” or “Review out-of-date” allowing the reader to make an informed decision when using the notebook. Minor revisions (e.g., software version updates, typo fixes) can be editorially acknowledged without full re-review, while substantial changes trigger a new review cycle. The system automatically detects when a reviewed notebook has been modified, flagging it as potentially out-of-date until a maintainer assesses whether the changes warrant re-review.
The review system will engage volunteer reviewers from the neuroimaging community to evaluate notebook submissions through a GitHub-based review infrastructure (https://github.com/neurodesk/neurodeskedu-reviews). Submissions will undergo evaluation using a structured checklist covering general quality standards, functionality, documentation, and instructional design. This transparent review process will ensure educational materials meet community standards for both technical accuracy and pedagogical effectiveness and is seen as a complementary process to the automated GitHub Action testing, as it verifies the educational content of the notebook beyond “does the notebook run”.
Detailed guidance for volunteer reviewers, including expectations and workflow instructions, is available in the Reviewing for NeurodeskEDU documentation.
Licencing
All NeurodeskEDU notebooks are released under the MIT License, with licensing information displayed in each notebook header. While users may license their own derivative notebooks as they choose, they must comply with the licenses of third-party neuroimaging tools accessed through Neurocontainers, which retain their original licenses documented in the Neurocontainers repository.37
Results
To date, NeurodeskEDU already includes 45 interactive notebooks spanning diverse neuroimaging methods and applications (neurodesk.org/edu). The following use cases highlight how the learning resource addresses challenges in neuroimaging education by integrating computational notebooks, containerised software, and flexible deployment options. Use Case 1 demonstrates consolidation of instruction, analysis, and visualisation within unified workflows. Use Case 2 illustrates the integration capabilities of multiple software tools for complex analytical pipelines. Use Case 3 shows a scalable deployment from structured workshops to self-directed learning.
Use Case 1: Integrated educational workflows
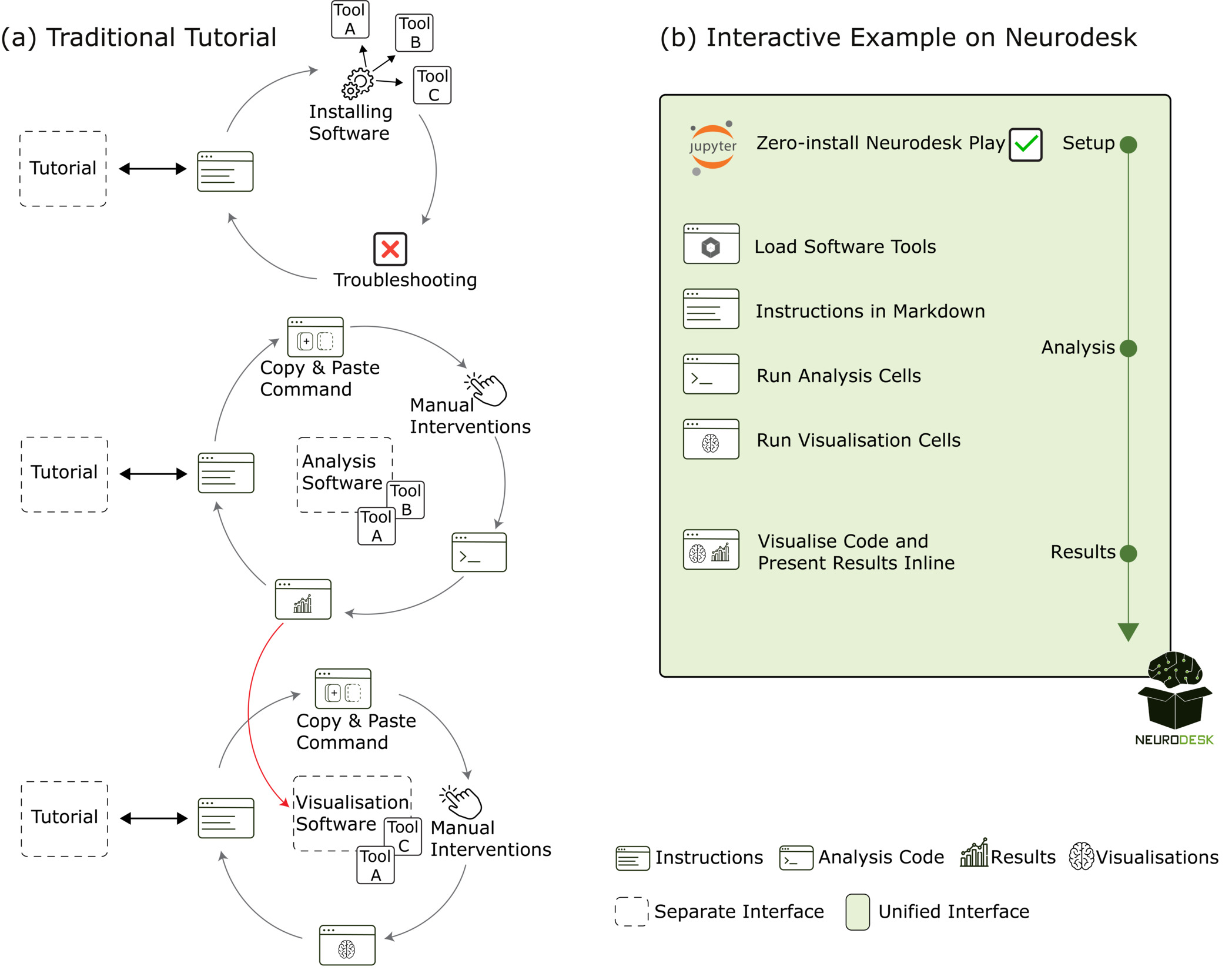
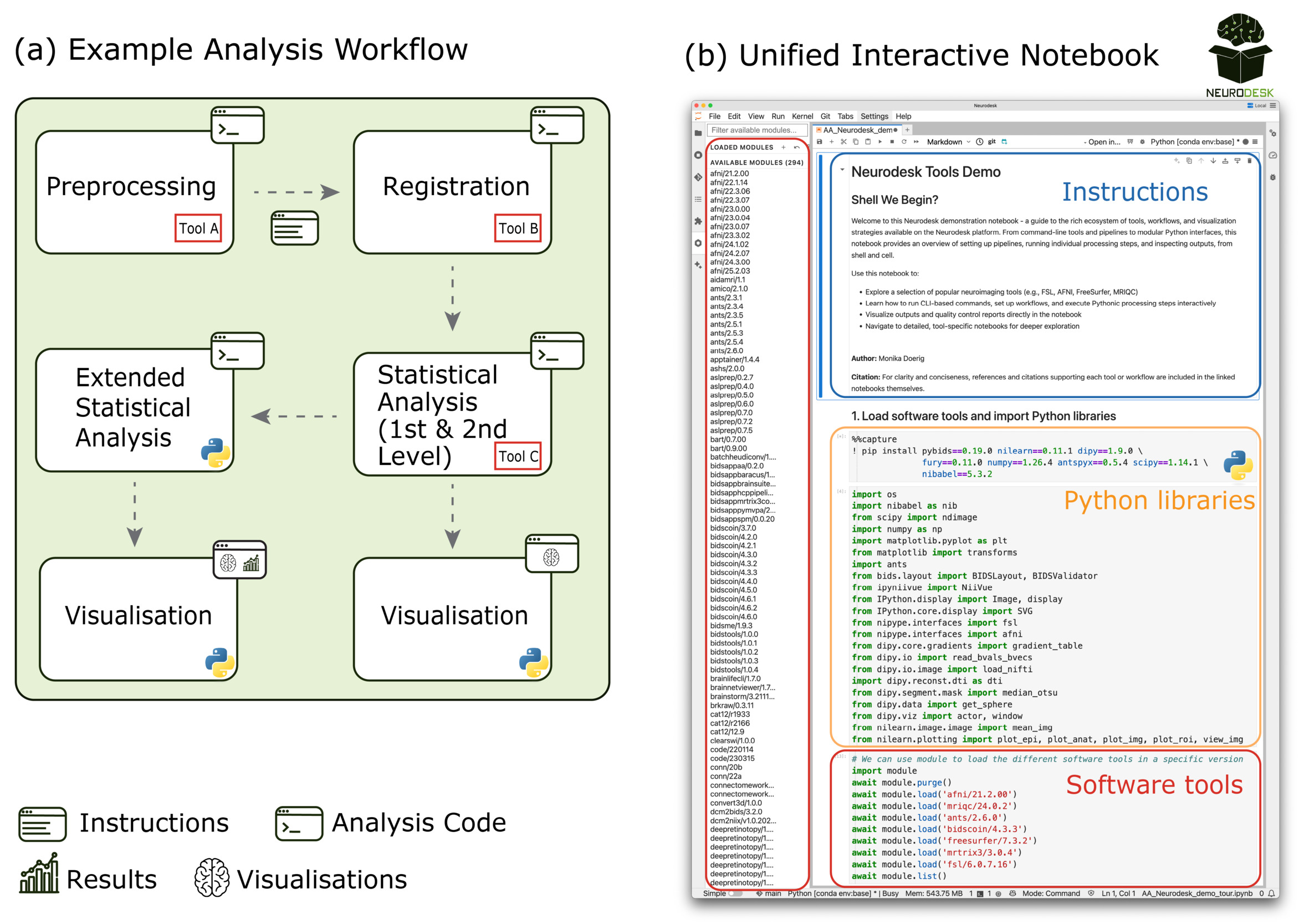
The interactive Jupyter Notebooks integrate instructional content, executable analysis code, and visualisation tools within a single interface. Traditional neuroimaging tutorials often require coordinating multiple software tools: reading instructions in a browser or PDF viewer, running analyses in terminal or GUI-based applications, and visualising results in separate viewers (Figure 5a). In contrast, our notebook-based approach consolidates all components into a single interactive document, combining markdown-formatted guidance, code execution, and embedded visualisation (Figure 5b). This integration is supported through Neurodesk’s containerised software delivery, which removes installation barriers, and by in-notebook visualisation libraries such as ipyniivue, Nilearn and Matplotlib. Together, these features enable a continuous workflow that spans data loading, preprocessing, and visualisation within one reproducible document.
**_t.png)
Use Case 2: Multi-software integration
Neuroimaging research often requires combining multiple specialised software packages, as each tool offers distinct strengths for specific processing stages. Here, we present educational content demonstrating how containerised software packages can work together in complete analytical workflows.
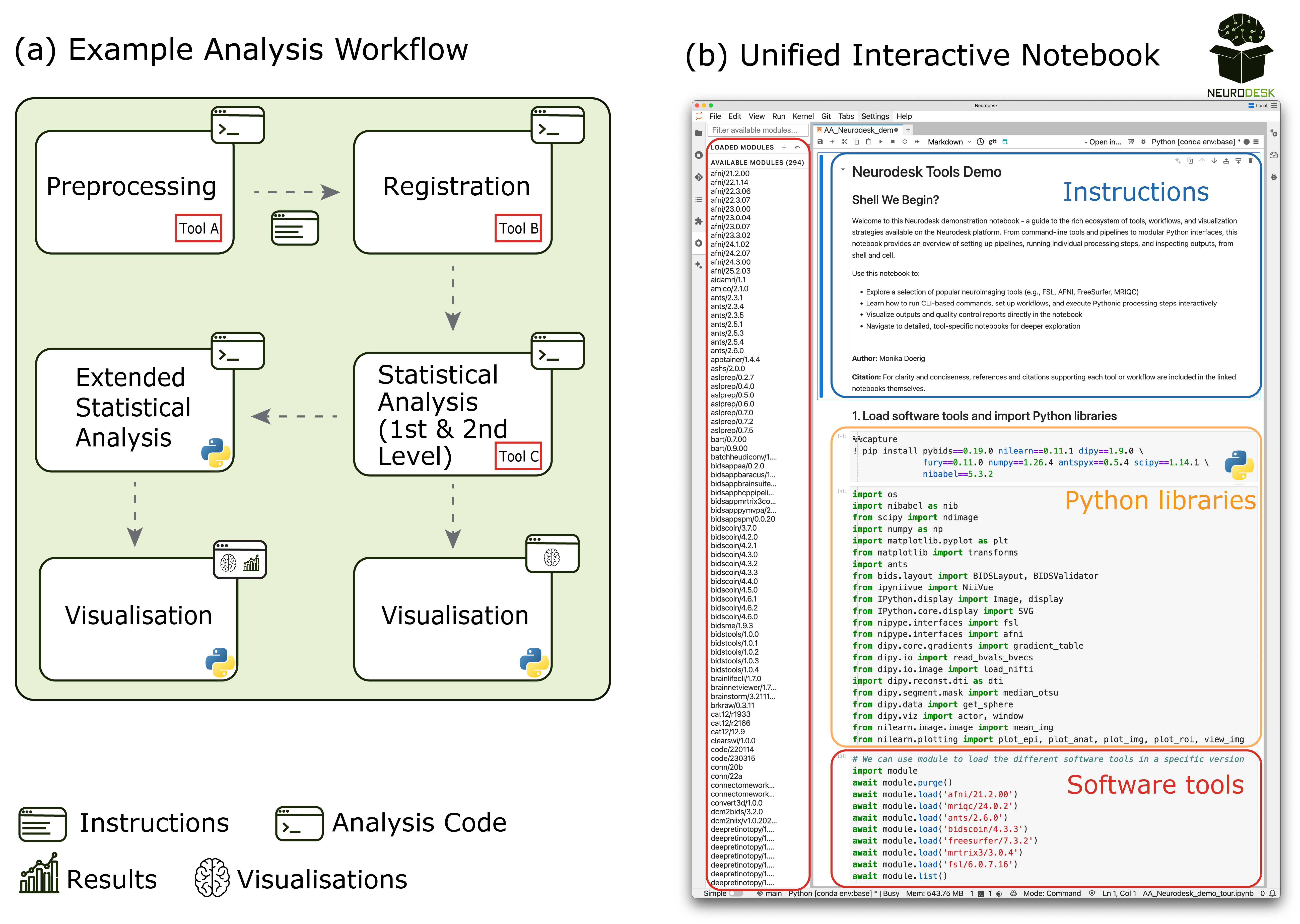
The Neurodesk Tools Demo notebook illustrates this multi-tool approach using multiple neuroimaging packages (FSL,58 AFNI,47,48 FreeSurfer,59 ANTs,60 MRtrix361) alongside Python libraries (e.g., NiBabel,62 Nilearn, DIPY, ipyniivue). The notebook demonstrates technical mechanisms: loading containerised packages on demand, executing commands from various software packages within a single interface, and managing data flow between tools. This prepares users to construct flexible, reproducible workflows (Figure 6).
This multi-tool approach even extends to multi-language workflows. Two example notebooks demonstrate R-based analyses integrated via magic commands: 1) The Magic Commands notebook illustrates different methods for R integration beyond other useful magic commands, and 2) the Resting-State fMRI Analysis in R notebook presents a complete fMRI analysis workflow using R.
Use Case 3: Workshop deployment and continued learning
Traditional workshops often devote substantial time to resolving installation issues and software incompatibilities across participants’ diverse computing environments. Using a shared cloud-based Neurodesk instance, workshop participants access identical preconfigured environments immediately, containing the required neuroimaging tools and example datasets, ensuring that demonstrations run consistently across all participants.11 Workshop materials are implemented as interactive Jupyter Notebooks, which can be presented directly as instructional content. The RISE extension56 enables instructors to transform notebooks into live slide shows, transitioning seamlessly between explanation and hands-on execution while participants follow along in their own instances. Beyond the workshop, persistent access ensures continued learning: participants can download notebooks for local execution or review static versions via GitHub Pages, leaving them with complete, reproducible learning resources they can immediately apply (Figure 7).
Discussion
Building on Neurodesk’s open infrastructure, we developed the community-driven neuroimaging learning resource NeurodeskEDU, combining computational notebooks, containerised software, and flexible deployment mechanisms. Across three use cases, we demonstrated how this approach consolidates fragmented educational workflows, enables multi-software integration, and supports scalable deployment from structured workshops to self-directed exploration. This hands-on methodological training complements ReproNim’s focus on educating instructors in FAIR neuroimaging principles, together addressing both educator preparation and learner engagement in reproducible practices. It extends established educational resources while also enabling their transformation: existing tutorials can be adapted into interactive notebooks that retain instructional content while adding executable code and embedded visualisations. In doing so, static instruction is transformed into dynamic exploration leveraging the capacity of interactive notebooks to enhance learner engagement and the attainment of complex learning outcomes.63 Beyond conceptual understanding, this interactive format allows users to develop problem-solving skills with concrete, responsive situations, including the detection and resolution of common processing failures — competencies that are challenging to develop through static formats.
Traditional formats such as GUI-based and command-line tutorials, or static documentation, serve important roles aligned with different learning preferences, instructional contexts, and educational goals. Interactive notebooks address specific limitations around integration, reproducibility, and accessibility while coexisting within a diverse educational ecosystem. Similarly, platforms like brainlife64 excel at pipeline construction and scaling across large datasets, but offer limited visibility into processing rationale and edge case handling. Platforms like Code Ocean focus on reproducing specific published analyses, while NeurodeskEDU provides an educational platform teaching generalisable methods. NeurodeskEDU adds an educational layer to the Neurodesk ecosystem by foregrounding the pedagogical scaffolding that helps learners to understand how to build pipelines and why particular processing decisions matter.
Beyond immediate educational applications, this work highlights a broader transformation in how computational methods are documented and disseminated. Neurodesk provides the technical infrastructure that underpins NeurodeskEDU, supporting educational reproducibility and enabling educational materials to be recognised as formal scholarly contributions.37
Addressing computational notebook challenges
Computational notebooks have been criticised for issues such as hidden state, dependency management, insufficient documentation, and weak alignment with software engineering best practices.34 We mitigate these limitations through both technical and community-based solutions. To minimise hidden-state problems, our implementation encourages linear execution practices through several mechanisms. Educational materials provide explicit guidance on restarting the kernel and executing cells sequentially from top to bottom. Importantly, GitHub Actions automatically test notebooks by running all cells in order after any modifications, ensuring that materials function correctly when run linearly.
Ensuring reproducibility requires effective dependency management, including explicit documentation of software versions and computational environments. In NeurodeskEDU, this is achieved by running notebooks within the Neurodesk containerised environment, where specific software versions are explicitly loaded. With the watermark extension (integrated into the NeurodeskEDU notebook template), Python library versions, system specifications and hardware characteristics are automatically documented, which enables long-term reproducibility of educational materials. This is complemented by direct access to open-source datasets, enabling users to reproduce analyses without proprietary data or navigating complex storage systems.11 Insufficient documentation, such as a lack of explanatory context or analytical reasoning, is addressed through adherence to established best practices for computational notebooks,24 which integrate markdown text and executable code in a clear, modular structure, supported by a standardised template and community review processes. This human-centred computing supports the development of technical writing, documentation, and communication practices that are difficult to achieve with other software.34
Quality assurance through transparency
While absolute correctness cannot be guaranteed, the open-source code and community review increase opportunities for feedback and iterative improvement. All code, data processing steps, and analytical decisions are fully transparent and executable, enabling collective scrutiny and continuous improvement. As notebooks integrate software, documentation, code and visualisations within a single file, updates to any component propagate automatically to all deployment modes (static pages and interactive execution). Following the open-source principle (Linus’s Law: “given enough eyes, all bugs are shallow”), this integrated architecture combined with transparency, systematic testing, and community engagement, supports the ongoing maintenance and reproducibility of educational materials.
Multi-tool integration
Traditional neuroimaging education frequently centres on single-software paradigms, which do not always reflect research practices where analyses draw on multiple tools. NeurodeskEDU provides learning resources that support both single-software notebooks for focused skill development and multi-tool workflows that illustrate how different packages can be combined in practice. Containerisation within Neurodesk enables these materials to coexist seamlessly within a unified environment, allowing users to progress from software-specific instruction to workflow-centric learning as their needs evolve. Integration with Python-based libraries further extends analytical capabilities to incorporate behavioural, demographic, or clinical variables. By providing hands-on experience with both single-tool and multi-tool approaches, the learning resource equips users with transferable skills for constructing flexible analysis pipelines across diverse research contexts.
Educational materials as scholarly outputs
Beyond technical quality assurance, NeurodeskEDU provides mechanisms for formal scholarly recognition that address academic incentive structures. Each notebook receives a persistent DOI that enables formal citation with version-specific identifiers. Each new release receives its own DOI version, allowing notebooks to evolve through community feedback while maintaining permanent access to earlier versions. These “living documents” remain relevant as methods and software advance. Engagement with these reproducible computational narratives exposes users to transparent research practices, fostering habits that support reproducible science throughout their careers.
A community peer review process modelled on JOSE complements rather than gatekeeps: notebooks will display transparent status badges (“Unreviewed” / “Under review” / “Reviewed” / “Review out-of-date”) that enable immediate dissemination while also signalling review status to readers. Automated testing verifies technical functionality before human review, allowing reviewers to focus on pedagogical effectiveness, content quality, and instructional design rather than debugging.
This positions NeurodeskEDU as a curated, peer-reviewed educational reference book that prioritises pedagogical value and currency, demonstrating that educational contributions can carry formal academic weight while remaining dynamically responsive to methodological advances.
Democratising access to neuroimaging education
Technical barriers to participation in workshops or tutorials are reduced by providing a zero-install access via a shared cloud-based Neurodesk instance, allowing equitable participation regardless of local hardware, operating system, or institutional resources. Standardised computational environments ensure consistent learning outcomes, while downloadable and static versions provide persistent access after formal instruction. This flexibility supports sustained engagement with neuroimaging methods.
Sustainability and future directions
As a future extension, NeurodeskEDU could include tutorials useful for clinical research such as workflows demonstrating lesion-awareness. Many commonly used neuroimaging pipelines are typically optimised for healthy brain anatomy and encounter substantial challenges when applied to clinical populations with pathological tissue, such as stroke lesions or traumatic brain injury (TBI).65–68 Integrating established lesion-aware frameworks65,67 into Neurodesk would enable the extension of the repository with tutorials and examples specifically tailored to these populations, covering both imaging analysis and brain-behaviour relationships. Intended for training and methodological exploration, such examples would increase the relevance for researchers and trainees in clinical contexts.
More broadly, maintaining currency with rapidly evolving methods requires sustained community engagement. Scaling the volunteer peer review system will be essential for managing growing contributions while maintaining quality standards. By leveraging the existing contribution framework, future work should also focus on broadening participation across diverse neuroimaging domains. For example, while Python-based workflows are currently dominant, R integration is supported through Jupyter magic commands. This approach allows R code execution within Python notebooks without kernel switching, though full native R kernel support is being tested for future implementation. Expanding the range of contributed workflows and incorporating emerging analysis tools will help ensure the collection remains current, inclusive, and representative of contemporary practice. Moreover, notebooks need not serve solely as educational endpoints; they can function as prototypes and starting points for more advanced workflows, enabling researchers to adapt and scale educational examples into specialised pipelines tailored to their specific research needs.
Limitations
While NeurodeskEDU addresses many barriers to neuroimaging education, dependence on proprietary software remains a limitation. Although the underlying Neurodesk infrastructure supports MATLAB, proprietary licensing requirements are incompatible with the commitment to barrier-free, open-source education accessible to all learners regardless of institutional affiliation. Consequently, NeurodeskEDU does not include MATLAB-based notebooks in the publicly accessible examples collection; however, users with existing institutional licenses can still develop and run MATLAB workflows within Neurodesk environments.
Conclusion
By integrating modern computational infrastructure with established educational content, NeurodeskEDU demonstrates how neuroimaging education can support interactive exploration, reproducible workflows, and multi-tool integration, while embodying principles increasingly central to scientific publishing: transparency, executability, formal citability, community-driven refinement, and establishing quality assurance through peer review. Our framework provides a model applicable to other domains facing similar challenges in teaching and disseminating computational methods. As computational approaches become increasingly central across scientific disciplines, learning resources that democratise access, maintain reproducibility, and enable living documents that evolve through community engagement will be essential for preparing the next generation of researchers and advancing a broader shift toward open, reproducible science.
Data and code availability
Open-source code for the development of NeurodeskEDU resources is available on GitHub (https://github.com/neurodesk/neurodeskedu) under MIT license.
Funding sources
This work is supported by the Wellcome Trust with a Discretionary Award as part of the Chan Zuckerberg Initiative (CZI), The Kavli Foundation, and Wellcome’s Essential Open Source Software for Science (Cycle 6) Program (Grant Ref: [313306/Z/24/Z]). This research was supported by the use of the ARDC Nectar Research Cloud, a collaborative Australian research platform supported by the Australian Research Data Commons (ARDC), a capability funded through the National Collaborative Research Infrastructure Strategy (NCRIS). This work benefited from services and resources provided by the EGI Federation with the dedicated support of CESNET-MCC. Computational resources were provided by the e-INFRA CZ project (ID:90254), supported by the Ministry of Education, Youth and Sports of the Czech Republic. This research was supported by Jetstream2 (NSF award #2005506), which is supported by the National Science Foundation. Jetstream2 is a cloud computing resource managed by the Indiana University Pervasive Technology Institute and part of the ACCESS project. The authors acknowledge the facilities and scientific and technical assistance of the National Imaging Facility, a NCRIS capability at the University of Queensland. TS is supported by a Motor Neurone Disease Research Australia (MNDRA) Postdoctoral Research Fellowship (PDF2112) and NHMRC Ideas grant APP2029871. FLR acknowledges support through the European Union’s Horizon Europe research and innovation funding program under the Marie Skłodowska-Curie Actions project ID 101146996. CR is supported by the National Institutes of Health (NIH) with P50-DC014664 and RF1-MH133701. PT is supported by the NIMH Intramural Research Program (ZICMH002888) of the National Institutes of Health (NIH), HHS, USA; DH is supported by ZIAMH002783 of the National Institutes of Health; The contributions of DH and PT were supported by the Intramural Research Program of the National Institutes of Health (NIH). The contributions of the NIH author(s) are considered Works of the United States Government. The findings and conclusions presented in this paper are those of the author(s) and do not necessarily reflect the views of the NIH or the U.S. Department of Health and Human Services.
Conflicts of interest
The authors have no competing interests to declare that are relevant to the content of this article.