

1. Introduction
The visualization of neuroimaging data is one of the primary ways in which we evaluate data quality, interpret results, and communicate findings. These visualizations are commonly produced using graphical user interface (GUI) -based tools where individual images are opened and, within each instance, display settings are manually changed until the desired output is reached. In large part, the choice to use GUI-based software has been driven by a perception of convenience, flexibility, and accessibility. However, there now exist code-based software packages that are well-documented and do not require high-level and comprehensive knowledge of programming, making them accessible to the neuroimaging community. These tools are flexible and can generate reproducible, high-quality, and can make publication-ready brain visualizations in only a few lines of code, especially within the R, Python and MATLAB environments. Here, we first discuss the rationale for the widespread adoption of code-generated visualizations by highlighting major advantages in replicability, flexibility, and integration. We then provide a practical guide outlining the steps required to make code-based brain visualizations and provide a web-app (https://sidchop.shinyapps.io/braincode/; see Section 4) that can generate simple code-templates as starting points for these visualizations. We also present a comprehensive table of tools currently available for programmatic brain visualizations (Table 1) and provide instructive examples of visualizations and associated code as a point of reference (Figure 2-3). Finally, we outline some limitations and gaps in the current functionality of code-based tools. The focus of this guide is on human brain magnetic resonance imaging (MRI) data, but many of the principles discussed and tools provided will equally apply to visualizing data from other organs and imaging modalities such as EEG, MEG, PET and CT.
2. Benefits of learning to generate code-based brain visualizations
2.1. Replicability
In recent years, there have been multiple large-scale efforts empirically demonstrating the lack of reproducibility of findings using neuroimaging data.1 One common solution proposed for achieving robust and reliable discoveries has been to encourage scientific output that can be transparently evaluated and independently replicated. In practice, this typically entails openly sharing detailed methods, materials, code, and data. While there is a trend towards sharing code related to neuroimaging analyses, the sharing of code used to generate figures such as brain renderings and spatial maps has been relatively neglected. This gap in reproducibility is partly driven by the fact that brain figures are often created using a manual process that involves tinkering with sliders, buttons, and overlays on a GUI, concluding with a screenshot and sometimes beautification in image processing software like Illustrator, Photoshop or Inkscape. Such a process makes neuroimaging visualizations inherently difficult, if not impossible to replicate, even by the authors themselves.
The code used for data visualization should reflect a core feature of open science. Given that brain figures regularly form the centerpiece of interpretation within papers, conference presentations, or news reports, making sure they can be reliably regenerated is crucial for knowledge generation and dissemination. By writing and sharing code used to generate brain visualizations, a direct and tractable link is established between the underlying data and the corresponding scientific figure. While this code doesn’t necessarily reflect the validity or accuracy of the scientific finding, it allows for reproducibility, instilling transparency and robustness, while demonstrating a desire to further scientific knowledge. Some even consider publishing figures that cannot be replicated as closer to advertising, rather than science.2
Notably, some GUI-based tools have historically offered command-line access to generate replicable visualizations (e.g., FreeView, FSLeyes, surfice), making their use potentially equally replicable to purely code-based tools. Use of these specialized command-line interfaces can provide a useful middle ground for those who have little experience with coding environments. Nonetheless, these interfaces often still have a learning curve, but can lack other advantages, such as iteration, provided by programming environment (see Sections 2.2 and 2.3). Likewise, other GUI-based tools offer replicability in the form of automatically generated batch scripts (text files containing lines of specialized commands that can be re-executed) or in-built terminals, which can be idiosyncratic and may lack documentation to make them easily usable or replicable by those not familiar with the specific software.
2.2. Flexibility and scalability
Being able to exactly replicate a figures via code has marked advantages beyond open science practices. In particular, the ability to reprogram inputs (such as statistical maps) and settings (such as color schemes, thresholds, and visual orientations) can streamline the entire scientific workflow. Changing inputs and settings via code allows for the easy production of multiple figures, such as those resulting from multiple analyses that require similar visualizations. A simple for-loop or plotting function with altered inputs and/or settings-of-interest can be a powerful method for exploring visualization options or rapidly creating multi-panel figures. Likewise, an arduous request from a reviewer or collaborator to alter the image processing or analysis becomes less of a burden when the associated figures can be re-generated with a few lines of code, as opposed to re-pasting and re-illustrating them manually. Having a code-base with modifiable inputs can mean that the generation of visualizations requires less time, energy and effort than image and instance specific GUI-based generation. This also makes it easier to generate consistent figures across subsequent projects. Critically, the gains of writing code for figures are cumulative, and in addition to improving programming skills, one can build a code-base for figure generation that can be reused and shared throughout a scientific career.
Precise controls via code over visualization settings, such as color schemes, legend placement and camera angles, provides much greater flexibility over visualizations. Nonetheless, part of the appeal of GUI-based tools is that the presets for such settings can provide a useful starting point and reduce the decision burden on novice users. However, similar presets are often available in the form of default settings across most code-based packages, negating the need for the user to manually enter each and every choice required for creating an image. Most code-based tools also come with documentation, with R-packages on the CRAN or Neuroconductor3 repositories requiring detailed guidance. Recent tools have started to include detailed beginner-friendly documentation in GitHub repositories, or even entire papers (e.g., Pham, Muschelli, & Mejia, 2022; Mowinckel & Vidal-Piñeiro, 2020; Huntenburg et at., 2017; Schäfer & Ecker, 2020) that provide examples of figures that can be used as starting points or templates for new users (also see Section 4). As the popularity of code-sharing for figure increases, there will be a cornucopia of templates that can be used as the basis for new figures.
While brain visualizations are often thought of as the end results of analyses, they also form a vital part of quality control for imaging data. Tools to automatically detect artefacts, de-noise the data and generate derivatives are becoming more robust, but are not yet at the stage where visualizing the data is no longer necessary. Nonetheless, when working with large datasets such as Human Connectome Project4 or UK BioBank,5 it is simply not feasible to use traditional GUI-based tools to visually examine the data. The time it takes to open a single file and achieve the desired visualization settings vastly compounds when working with large datasets. Knowing how to programmatically generate brain visualizations can allow for iteration of visualization code over each image of a large datasets making quality checks of each data processing step achievable. The visual outputs of each iteration can be complied into accessible documents that can be easily scrolled, with more advanced usage allowing for the creation of interactive HTML reports (see Section 3.5), similar to those created by standardized data processing tools like fmriprep.6 This increased capacity to conduct visual quality control on larger datasets will improve the identification of processing errors and result in more reliable and valid findings.
2.3. Integrative and Interactive Reporting
Often in neuroimaging studies, programming languages such as R, Python and MATLAB are used for statistical analysis and generating non-brain figures, but the brain figures are outsourced to separate GUI-based tools such as FSLeyes, Freeview or ITK-snap. Increasingly popular software such as R Markdown, Quarto and Jupyter Notebook allow for the mixing of prose and code in a single script, resulting in fully reproducible and publication ready papers. By using code-based tools available within the preferred environment, brain visualizations can be directly integrated and embedded within a paper or report. For instance, a fully reproducible version of the current paper can be found on GitHub. Some journals that publish neuroimaging studies are moving towards reproducible manuscripts, including reproducible figures (e.g. eLife, Aperture Neuro), with other journals like F1000Research and GigaScience even allowing on-demand re-running of code linked to the associated article via cloud-based platforms like Code Ocean (Code Ocean, 2021).
Neuroimaging data are often spatially 3D and can have multiple time points, adding a 4th dimension (e.g., functional imaging data). Thus, communicating findings or evaluating quality using static 2D slices is challenging, and may not be the best representation of the data, or the associated interpretations. While well-curated 3D renderings can help with spatial localisation,7,8 in the end, static images can only provide an incomplete representation of the data, and they force researchers to choose the “best” angle or slice to show, which often involves compromising one result to emphasize another. An added advantage of some of the code-based tools is the generation of ‘rich’ media like interactive figures or animations, that allow users to zoom, rotate and scroll through slices. Interacting with a figure in this way can improve scientific communication of findings. Linking to or even embedding these videos or interactive figures in papers can greatly enhance the communication of findings and make papers more engaging for the reader. Such rich brain visualizations lend themselves to being shared on science communication mediums beyond academic papers—such as presentations, websites and social media—all of which can promote the communication of research with peers and reach larger audiences.9 This last point is becoming increasingly salient as social media has become a core medium for spreading discoveries via science communication to the public,10–12 to the research community,13,14 and even a primary avenue for employment opportunities for early-career researchers.15,16 Overall, public engagement is a cornerstone of science, and the images we create are at the center of the process.
3. Generating Code-based Visualizations
In the following sections we outline the primary steps required when generating programmatic and reproducible human brain visualizations (Figure 1), and provide tools and heuristics to guide this process.

3.1. Selecting a programming language
The first step in generating code-based visualization can be selecting the coding language. Three of the most popular languages are R, Python and MATLAB, all of which have many options for generating brain visualizations (see Table 1). This decision can be made based on what language the user has prior experience with, or if one of these languages was used for the analysis part of a project. There can be advantages in using the same language for visualizations and analyses, as switching between separate environments, or to a GUI-based visualization software, can be a cumbersome deviation from the scientific workflow. This can make debugging errors more difficult, as the user must regularly switch programs to visually examine the results of any modifications or adjustments to prior analyses. Using the brain visualization tools that already exist within a chosen programming environment can provide instant visual feedback on the impact of modifications to processing or analysis.
Alternatively, the choice of programming language may be dictated by visualization and data-type required. For instance, visualizing streamlines from tractography may not be currently available in the R environment (Table 1), and therefore requires the use of Python or MATLAB. Other constraints may include limited access to proprietary software like MATLAB, which would necessitate the use of open-source options such as R, Python or Octave.
3.2. Identify a visualization type
Neuroimaging data and its derivatives can be visualized in multiple forms, that have different associated file-types and visualization requirements (see Section 3.3). A brief description of more popular visualization types is provided below:
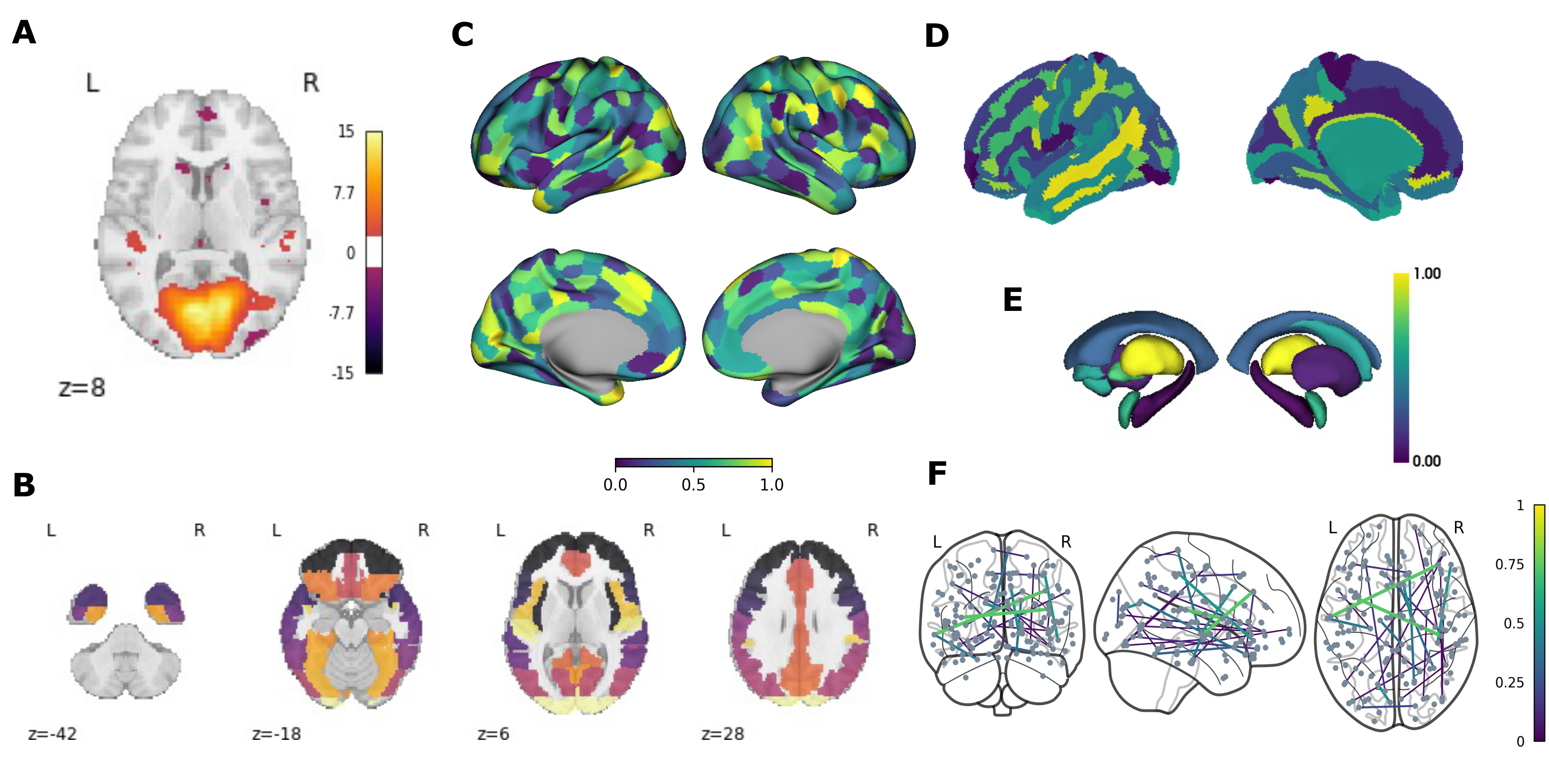
Voxel. In neuroimaging, voxels are used to represent the intensity values of a 3D scan, such as an MRI or CT scan. The voxels can be rendered in different colors to indicate tissue types or other features of interest. For example, in functional MRI scans, voxels can be colored based on their level of activation, to show which areas of the brain are more active during a specific task. These visualizations are often displayed as either slices in axial, sagittal or coronal planes (Fig2A-B; Fig3A-B) or a 3D rendering of the whole brain. Statistical values are displayed as overlays on template anatomical images, that follow a common stereotaxic coordinate system (e.g., MNI152), or on individual-specific anatomical images.


Vertex. In neuroimaging, vertices are used to create a mesh representation of brain structures, such as the cerebral cortex or a subcortical regions. Each vertex has a set of coordinates that specify its location in 3D space and is connected to other vertices to form triangles, which make up the mesh. Vertices can be used to create a 3D visualization of the brain surface and color-coded based on different attributes such as sulcal depth, thickness, or functional activation. These visualizations are often displayed as 3D rendering of each hemisphere from medial and lateral views (Fig2C,G-H; Fig3C-D). Statistical values are displayed as overlays on template surfaces which follow a common stereotaxic coordinate system and fixed number of vertices (e.g., fsaverage; Fig2C,G; Fig3C-D), or on individual-specific surfaces that have been reconstructed using an anatomical image (Fig2H).
Regions of Interest (ROI). In neuroimaging, ROIs are used to identify specific brain structures or areas that are relevant to the research question. ROIs can be defined using various methods, such as manual tracing, atlas-based parcellation, or functional activation patterns. Visualizing ROIs can be done by grouping and assigning the same statistical value or color to sets of voxels or vertices (Fig2B-C; Fig3B-C), or can be done through polygons. Polygonal brain visualizations are simple 2D or 3D shapes which graphically represent the brain or specific structures, but do not carry any additional information on spatial coordinates and only roughly estimate the shape of the brain and its structures. Each region of 2D (Fig 2D,F) and 3D (Fig 2E; Fig3E) polygon visualizations is filled in with colors indicating a region label or a statistical value.
Edge. In the context of neuroimaging, an edge often represents a physical or statistical connection between two brain regions, which can be visualised as a straight or curved line connecting two nodes (brain regions) in a network. One common way data is organized for edge-level visualization is a matrix, often called a ‘connectivity’ or ‘adjacency’ matrix, which indexes the presence and strength of the connections between pairs of brain regions. Visualitaion tools often convert these matrices into network graphs, where the vertices represent brain regions and the edges represent the connections between those regions, and can be displayed in a variety of ways, such as overlayed on a 2D or 3D representation of the brain (Fig2I; Fig3F), with edges represented as straight lines connecting the vertices. Often, visual properties of edges and nodes can also be adjusted to convey information, such as sized or color-coded based the strength or number of connections.
Streamlines. While similar to edges, streamlines are specifically used to represent the white matter fibers and are usually an output of conducting tractography to diffusion-weighted MRI. Streamlines are typically visualized as curved 3D lines that connect different points of the brain and can be used to create 3D visualizations of specific white matter tracts, or all streamlines between regions. They can be color-coded based on the direction of the fibers or properties of the tract, such as myelination. These visualizations can be overlaid on voxel- or vertex-level anatomical brain representations to provide an anatomical reference point.
The following two figures provide examples of voxel, vertex, ROI and edge-level visualizations generated within R (Figure 2) and Python (Figure 3) using open source, well documented and beginner-friendly packages. These are not an exhaustive representation of packages available for visualizing brain data in R and Python (see Table 1). Rather, the figures aim to give the reader a sense of the many options available, and are an entry point to choosing the type of brain visualization needed (also see Section 4). All code used to compile the figures, as well as the contents of each panel are provided in the accompanying online repository.
3.3. Identify input file-formats
Neuroimaging data and its derivatives come in many different file formats, and code-based visualization packages have specific formats they are designed to work with. Table 1 provides a key, listing which data-type can be used as inputs for each package. Some of the most common MRI file-formats used as inputs for visualizations are briefly described below:
Plain text format. The simplest input formats are a scalar, vector, and matrix, which represent a single data-point, one-dimensional array of data (e.g., a single column or row), and a two-dimensional array of data (e.g. multiple columns or rows), respectively. These data are often stored in plain text formats such as .txt, .csv, and .tsv and can be generated by neuroimaging analyses software such as SPM, FSL or FreeSurfer. These files can also contain rows and columns of region names and/or spatial coordinates. All programming languages have functions to read these plain text formats into the coding environment. These formats are often used in region-level visualizations, where groups of voxels or vertices share the same value or color (Fig2B-F; Fig3B-E), or in edge-level visualizations, where a matrix is used to identify regions are connected by an edge (Fig2F; Fig3F).
NIfTI. NIfTI (.nii) files store 3D or 4D image data that are often a matrix of voxel intensities or a series of 3D matrices for 4D data such as fMRI and dMRI. The image data is stored as a 3D matrix of voxel intensities, and the header contains additional information, such as the image dimensions and voxel size. Additional information such as the subjects demographics and scanner parameters can also be stored in the header in the form of metadata.
GIfTI. GIFTI (.gii) is an extension of the NIFTI format, and stores data in a surface-based format represented as a set of vertices, edges, and faces that define a surface mesh. The format also includes support for storing data such as curvature, thickness, and functional activity maps on the surface mesh. Often .gii file names will have a pre-indicator of what information the file contains, such as .surf.gii, which would contain only vertices, edges and faces to define a surface mesh. Or .func.gii files that contain data values for every vertex, which are essentially data arrays whose indices correspond to a surface file and need a corresponding surface file to know where in the brain to assign the data values. GIFTI files can also store multiple surfaces in a single file, and can include information about the topology of the surfaces, such as the number of vertices, edges, and faces. Additional metadata can also be stored in the header.
CIfTI. CIFTI (.cii) files can store data from both surface-based and volume-based neuroimaging analyses, combining aspects of NIFTI and GIFTI files. For surface-based data, the file contains vertex coordinates, and data values at each vertex. For volume-based data, the file contains a 3D matrix of voxel intensities. Often this datatype is used to represent the cortex as vertices, and subcortical, brain stem and cerebellar structures as voxels. CIFTI files can be divided into three main types: .dtseries (store time-series data, such as fMRI data), .dtscalar (store scalar data, such as thickness or curvature maps), and .dtlabel (store label data, such as parcellations of the brain). These files can also include fields with additional metadata such as surface and volume registration information.
FreeSurfer. FreeSurfer is a commonly used image processing and analysis software that comes with a variety of proprietary formats to store outputs. The primary format is .mgh and its compressed version .mgz, which like .nii files, genrally stores voxel-level data. Vertex-level data is stored in multiple formats such as .pial, .white, and .inflated. FreeSurfer also uses .label files to store a list of vertices and associated labels for each brain structure, and .annot files FreeSurfer store annotation information such as vertices, labels and color information that can be overlaid on the surface reconstruction.
Tractography. Commonly used tractography file formats include .trk and .tck developed by the TrackVis and MRtrix software packages, respectively. Both formats store coordinates for streamlines as a series of 3D points, with each point represented by its x, y, and z coordinates, as well as a tract header with the number of points in the tract, the properties of the tract (e.g., mean diffusivity, fractional anisotropy), as well as the starting and ending indices of streamlines.
Critically, many of these datatypes are interchangeable, and can be converted between each other. There are many ways to convert between format, for instance, the Connectome Workbench,17 and related R-packages like ciftitools18 allow for conversion between NIFTI, CIFTI and GIFTI formats. FreeSurfer functions such as mri_convert, the NiBabel19 library in Python and the fsbrain20 in R, all allow for conversion between the propriety formats and open-source NIFTI, CIFTI and GIFTI formats. Therefore, if a given file format to is not compatible with a visualization package, library, or toolbox, the user can convert data into the desired format. Although, it is important to visualize and validate data after converting between data-structures, to ensure the data have not been misinterpreted, and also to be aware that unintended consequences of mapping between 2D surface and 3D volume formats can arise.21
3.4. Select a package, library or toolbox
The previous steps of deciding a programming environment, visualization type and input data-type will help users decide which package, library or toolbox is the right choice. Table 1 provides a list of tools in R, Python and MATLAB, classified by whether they are able to generate voxel, vertex, ROI, edge or streamline based visualizations. While each tool may contain the ability to generate code-based visualizations, some tools are more beginner-friendly and better documented than others. Usually, these tools are specifically designed for brain data visualization, as opposed to tools that are designed for brain data analysis but also provide some limited visualization functionality. Some examples of well documented and beginner-friendly tools are provided via a code template generator (see Section 4).
An important consideration when selecting a tool is whether it can generate publication-ready plots. Publication-ready plots are high resolution, labelled, contain all color bars and legends, and require no additional manual image manipulation. While all tools listed in Table 1 contain some of these features, some tools enable more precise control over publication-ready features such as legend placement, color bar placement, annotations, labeling, and multi-panel figures. These tools usually produce visualization that rely on mainstream general purpose plotting engines such as ggplot in R and matplotlib in Python. This allows users to leverage many additional features to make their brain visualizations publication ready. For example, the ggseg and ggsed3d packages22 in R generate plots compatible with the widely-used grammar of graphics (i.e., ggplot2) and plotly engines, respectively. Similarly, the Nilearn library in python allows plots to be generated using matplotlib or plotly engines. We note that many of the others listed in Table 1 also rely on common plotting engines to generate visualizations.
3.5. Generate Visualization
Popular integrated development environments (IDE) such as RStudio, Visual Studio and Spyder, come with the inbuilt ability to display and update figures as the code is executed. The resulting visualization can be shared or embedded in papers in multiple different ways, with differing levels of replicability (see Section 2.3) and visual quality. One common way to share visualizations is to export it as a image raster format such as .png, .tiff or .jpeg, where images appear as a grid of pixels and each pixel in the grid contains information about the color and intensity of that specific point in the image. These formats are resolution dependent, and will become pixelated and difficult to parse when enlarged. Whereas vector formats, such a .svg, .eps and .pdf can be scaled larger or smaller without losing quality. While all coding environments provide ways to export visualizations into raster formats, exporting using vector formats, while visually superior, depends on the specific tool. Generally, only visualization tools that rely on mainstream general purpose plotting engines such as ggplot in R and matplotlib in Python allow for images to be exported as true vector formats.
Increasingly popular software such as R Markdown, Quarto, Jupyter Notebook, and Google Collab can create dynamic documents that combine code, text, and visualizations in a single file. This makes it easier to document workflows and share complete analyses, enhancing both collaboration and reproducibility. Including the code used to generate figures and other results alongside well formatted text-based explanations (see Section 2.3), enables the user and others to replicate work accurately. These tools also offer a wide range of output formats for documents, including PDF, HTML, Word and LaTeX. This versatility enables the generation of polished reports, presentations, manuscripts, or even interactive dashboards, all from a single source file. Currently, while R Markdown is primarily associated with R and Google Collab with Python, Jupyter Notebook and Quarto support a broader range of programming languages, including Python, Julia, R, and others.
_web-app_which_generates.png)
3.6. Share visualization code
Images that are generated using code can then be inserted into outputs such as a manuscript and the associated code can be included in supplementary materials. While this is the simplest way to share visualizations and code, it may not be as accessible as uploading code to dedicated code-sharing and version control platforms such as GitHub or GitLab. These services are currently widely used and allow for code to maintain formatting, version control and search functions.
Alternate options are widely used general-purpose research data repositories, such as Open Science Framework, Zenodo or FigShare, that enable researchers to publish and share their datasets, software, code and other research outputs at no cost. One advantage of these platforms is that they can assign a Digital Object Identifier (DOI) number to shared materials, making them independently citable and enhancing visibility since DOIs are indexed by various repositories and search engines. Some platforms even provide usage metrics, enabling users to gather insight on how often code and materials are accessed, cited or reused by others, which can be valuable information for evaluating the impact and reach of work.
An important consideration when both writing and sharing code for figure generation is the long-term preservation of code and resistance to software collapse. While a discussion of code and software preservation is outside the scope of the current paper, readers can refer to [NO_PRINTED_FORM], and initiatives such as Software Heritage which aim to preserve and archive all the software source code available worldwide, ensuring that valuable software source code is not lost over time.
In addition to the platform used, how accessible the code is to both the user and others depends on how clearly the code is written, formatted and commented. While guidance on proper organization of the neuroimaging visualization code is beyond the scope of this guide, we point readers to other practical guides on this topic.24,25
While sharing code is necessary for replicability, it is often not sufficient, as the underlying data source being visualized may be needed for the code to function correctly. While many of the same sharing platforms listed above can also host source data alongside code, there now exist specialized platforms, such as OpenNeuro and NeuroVault, that allow sharing of neuroimaging specific datasets, such as those containing NIFTI and CIFTI images. If the source data for visualizations cannot be shared, synthetic data can also be generated and provided alongside the code be provided.26
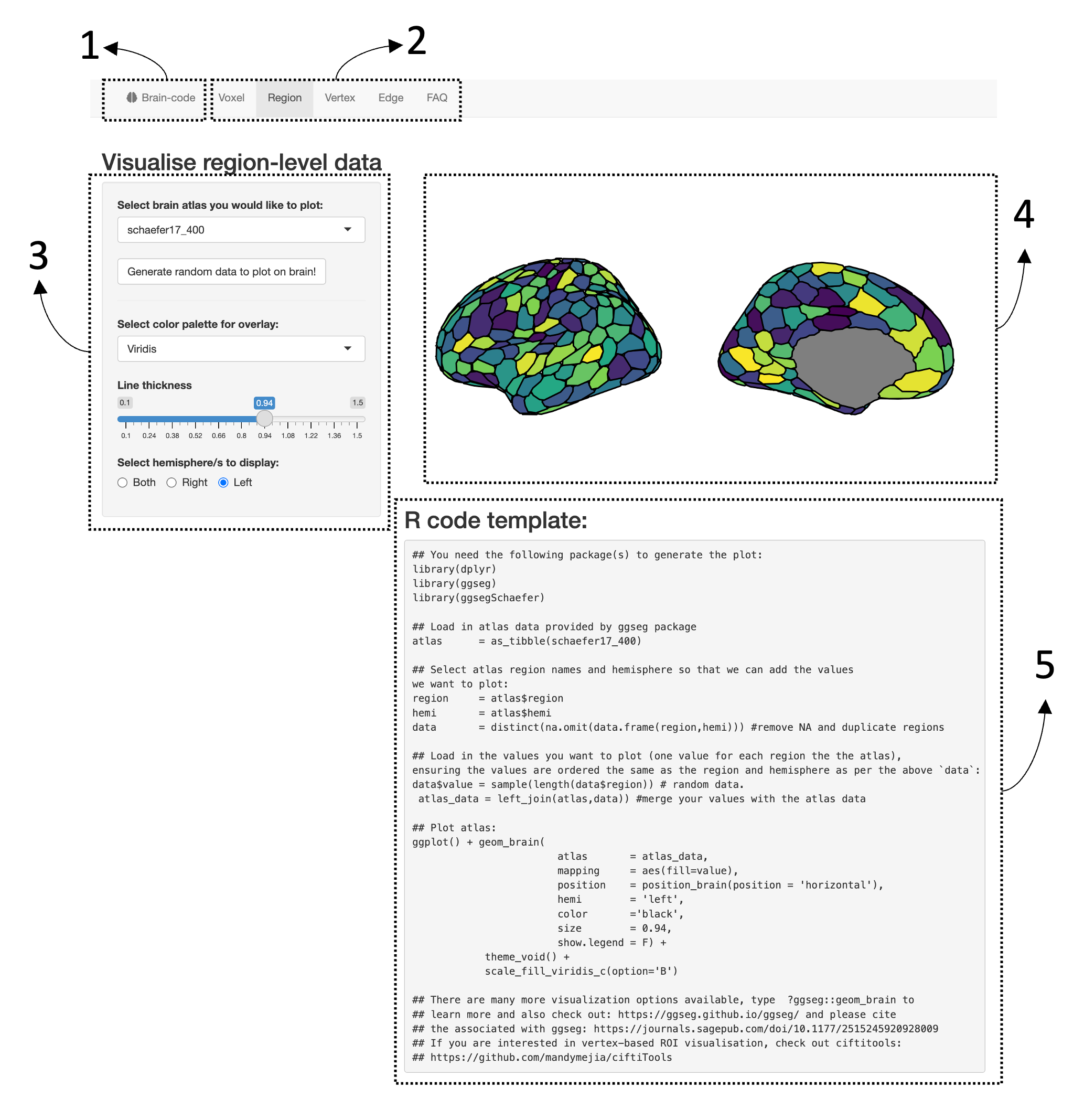
4. Brain-Code: A web-app for generating code templates for brain visualizations
To assist researchers transition into generating code-based brain visualizations, we have developed a web-app (https://sidchop.shinyapps.io/braincode/) that interactively generates of code-templates for beginner friendly libraries/packages in R and Python. In the web-app, users can select R or Python as their coding environment, and choose between voxel, ROI, vertex, and edge-level visualizations. They can then manually adjust a limited set of visualization setting, such as color-scales and view, and are provided with a reactive code-template that can be copied and then used within their respective programming environment. The provided code templates require users to customize the code, such as alter file-paths. The available settings have been purposefully limited to allow users to explore and fine-tune additional visualization options within their own programming environment. The code-template also contains links and prompts to more detailed documentation, alternate packages/libraries and tutorials which allow for more complex and publication-ready brain visualizations. Users can download bundled version of the web-apps via a GitHub repository.
5. Limitations and Functionality Gaps
While many code-based tools are well documented and do not require a strong knowledge of programming, there can still be a steep learning curve for new users, compared to using a GUI. This is especially true for the purpose of a publication-ready figure, where fine adjustments to visual features such as legend placement, font size and multi-panel figure positioning may be needed. While most code-based tools offer some control over these finer steps, there are differences between them in feature availability and usability, with tools that use established graphic engines such as ggplot2, matplotlib and plotly providing the most versatile and well-documented features for visual auxiliary. Relatedly, while some interactive image viewers can be opened within an integrated development environment like R-Studio (e.g., Muschelli, 2016), for quick and interactive viewing of single GUI tools can be faster and more practical.
Often cerebellar and brain-stem regions are not well represented in software (e.g., Figure 2-3), potentially mirroring the cortico-centric sentiment that has prevailed in human neuroimaging research.27 Likewise, custom non-cortical atlases such as non-standard subcortical atlas schemes are not yet straightforward, and usually require multiple functions and packages to visualize. Visualizing these structures often requires chaining together multiple GUI-based tools (see Madan, 2015). Alternatively users can convert neuroimaging specific file-formats into domain general visualization or polygon formats, such as .vtk, .ply or .obj, which can be read, manipulated and visualized using general purpose code-based tools. Examples of such tools include PyVista and Mayavi in Python and rayshader and plotly in R. Moreover, some neuroimaging derived datatypes, such as streamlines resulting from DWI-based tractography, are still not well represented in code-based visualization tools and future development should focus on enhancing visualization capabilities using these data-types.
As can be seen in Table 1 (https://sidchop.shinyapps.io/braincode_selector/), there are usually multiple packages within each programming environment which can visualize each data type. While this provides choice for advanced users, it can also lead to confusion for novice users who may not be familiar with the nuanced differences between tools. While the process we have outlined, and the table and web-app we have provided will help users decide the ideal package, future work should continue to consolidate brain visualization methods into unified beginner-friendly code-based tools which rely on established and well-documented graphic engines and can plot multiple data types.